




 本文深入探讨了Apache Storm如何确保从Spout发出的每个tuple都能被完全处理,包括可靠性特性的实现原理及其配置方法。介绍了Ack机制的工作流程,以及如何通过配置来平衡可靠性和性能。
本文深入探讨了Apache Storm如何确保从Spout发出的每个tuple都能被完全处理,包括可靠性特性的实现原理及其配置方法。介绍了Ack机制的工作流程,以及如何通过配置来平衡可靠性和性能。
转载自:
https://blog.youkuaiyun.com/xiaolang85/article/details/37761283
https://blog.youkuaiyun.com/xiaolang85/article/details/29215269
https://blog.youkuaiyun.com/guicaizhou/article/details/79273770
Storm保证从spout发出的每个tuple都会被完全处理。这篇文章介绍storm是怎么做到的,以及使用者怎么做才能充分利用storm的可靠性特点。
从spout发射的一个tuple可以引起其它成千上万个tuple因它而产生, 例如计算一篇文章中每个单词出现次数的topology:
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout(1, new KestrelSpout("kestrel.backtype.com",
22133,
"sentence_queue",
new StringScheme()));
builder.setBolt(2, new SplitSentence(), 10)
.shuffleGrouping(1);
builder.setBolt(3, new WordCount(), 20)
.fieldsGrouping(2, new Fields("word")); 这个topology从一个Kestrel队列读取句子, 把每个句子分割成一个个单词, 然后发射这一个个单词:一个源tuple(一个句子)引起后面很多tuple的产生(一个个单词),这些消息构成一个树状结构,我们称之为“tuple tree”。

在storm里面一个tuple被完全处理的意思是: 这个tuple以及由这个tuple所导致的所有的tuple都被成功处理。而一个tuple在timeout所指定的时间内没有成功处理会被认为处理失败了。 而这个timetout可以通过Config.TOPOLOGY_MESSAGE_TIMEOUT_SECS来指定。
如果消息被完整处理或者未被完整处理,Storm会如何进行接下来的操作呢?为了弄清这个问题,来看下spout实现的接口:
public interface ISpout extends Serializable {
void open(Map conf, TopologyContext context,
SpoutOutputCollector collector);
void close();
void nextTuple();
void ack(Object msgId);
void fail(Object msgId);
} 首先storm通过调用spout的nextTuple方法来获取下一个tuple, Spout通过open方法参数里面提供的SpoutOutputCollector来发射新tuple到它的其中一个输出消息流, 发射tuple的时候spout会提供一个messageId, 后面我们通过这个messageId来追踪这个tuple。举例来说,KestrelSpout从kestrel队列里面读取一个消息,并且把kestrel提供的消息id作为messageId, 看例子:
_collector.emit(new Values("field1","field2", 3),msgId); 接下来,这个发射的tuple被传送到消息处理者bolt那里, storm会跟踪由此tuple所产生的这课tuple树。如果storm检测到一个tuple被完全处理了,那么storm会以最开始的那个messageId作为参数去调用消息源的ack方法;反之storm会调用spout的fail方法。值得注意的一点是, storm调用ack或者fail的task始终是产生这个tuple的那个spout任务。所以如果一个spout被分成很多个task来执行,消息执行的成功失败与否始终会通知最开始发出tuple的那个task。
我们再以KestrelSpout为例来看看spout需要做些什么才能保证“一个消息始终被完全处理”, 当KestrelSpout从Kestrel里面读出一条消息,首先它“打开”这条消息, 这意味着这条消息还在kestrel队列里面,并未从队列中真正的删除,而是将此消息设置为“pending”状态,直到ack或者fail被调用。处于“pending”状态的消息不会被发给其他消息处理者;但如果这个spout“断线”了,那么所有处于“pending”状态的消息会被重新标示成“等待处理”。
为了使用Storm提供的可靠处理特性,我们需要做两件事情,首先,在生成一个新的tuple的时候要通知storm;其次,完成处理一个tuple之后要通知storm。通过上面的两步,storm就可以检测到一个tuple tree何时被完全处理了,并且会调用相关的ack或fail方法来通知Spout。
Storm提供了简单明了的方法来完成上述两步。由一个tuple产生一个新的tuple称为: anchoring(锚定)。锚定是在我们发送消息的同时进行的,即发射一个新tuple的同时也就完成了一次anchoring。看下面这个例子: 这个bolt把一个包含一个句子的tuple分割成每个单词一个tuple。
public void execute(Tuple tuple) {
String sentence = tuple.getString(0);
for(String word: sentence.split(" ")) {
_collector.emit(tuple, new Values(word));
}
_collector.ack(tuple);
} emit的第一个参数是输入tuple,第二个参数则是输出tuple,这其实就是通过输入tuple anchoring了一个新的输出tuple。因为这个“单词tuple”被anchoring在“句子tuple”一起, 如果其中一个单词处理出错,那么这整个句子会被重新处理。作为对比,我们看看如果通过下面这行代码来发射一个新的tuple的话会有什么结果。
_collector.emit(new Values(word));用这种方法发射会导致新发射的这个tuple脱离原来的tuple树(unanchoring), 如果这个tuple处理失败了, 整个句子不会被重新处理。到底要anchoring还是要 unanchoring则完全取决于你的业务需求。
一个输出tuple可以被anchoring到多个输入tuple。这种方式在stream合并或者stream聚合的时候很有用。一个多入口tuple处理失败的话,那么它对应的所有输入tuple都要重新执行。看看下面演示怎么指定多个输入tuple:
List<Tuple> anchors = new ArrayList<Tuple>();
anchors.add(tuple1);
anchors.add(tuple2);
_collector.emit(anchors, new Values(1, 2, 3));多重锚定会将被锚定的消息加到多棵tuple tree上。
我们通过anchoring来构造这个tuple树,最后一件要做的事情是在你处理完当个tuple的时候告诉storm,通过OutputCollector类的ack和fail方法来做。调用OutputCollector 的fail方法会立即将消息源头发出的那个tuple标记为fail,这样可以让这个tuple被快速的重新处理,因为你不需要等那个timeout时间来让它自动fail。每个你处理的tuple,必须被ack或者fail。因为storm追踪每个tuple要占用内存。所以如果你不ack/fail每一个tuple, 那么最终你会看到OutOfMemory错误。
大多数Bolt遵循这样的规律:读取一个tuple;发射一些新的tuple;在execute的结束的时候ack这个tuple。这些Bolt往往是一些过滤器或者简单函数。Storm为这类规律封装了一个IBasicBolt类。如果用IBasicBolt来做,发送到OutputCollector的tuple会自动和输入tuple相关联,而在execute方法结束的时候那个输入tuple会被自动ack的。但是,处理聚合和合并的bolt往往要处理一大堆的tuple之后才能被ack,而这类tuple通常都是多输入的tuple,所以这个已经不是IBasicBolt可以罩得住的了。
那么Storm到底是怎么实现可靠性的呢?
这里依靠Strom的ACK框架,Strom ACK可以在工作过程中不保存整棵Tuple树的映射,而对于任一大的一个Tuple树,它只需要恒定的20字节就可以进行跟踪,大大节省了内存。
Storm里面有一类特殊的task称为:acker,Acker Bolt属于System的组件,由系统创建,他们负责跟踪spout发出的每一个tuple的tuple树。当acker发现一个tuple树已经处理完成了。它会发送一个消息给产生这个tuple的那个spout。可以通过Config.TOPOLOGY_ACKERS来设置一个topology里面的acker的数量,默认值是1。 如果你的topology里面的tuple比较多的话, 那么把acker的数量设置多一点,效率会高一点。
Ack原理很简单:对于每个Spout Tuple保存一个ack-val的校验值,它是64位的数字(随机产生),初始值是0,然后每发射一个Tuple或者ack一个Tuple,Tuple的ID都要跟这个校验值异或一下,并且把得到的值更新为ack-val的新值。如果每个发射出去的Tuple都被ack了,最后ack-val一定是0。如果ack-val为0,表示这个Tuple树就被完整处理过了。或则当达到超时时间,ack-val不为0,则Tupel处理失败了。
Ack框架的执行过程如下。
- Storm的Spout中对每条发送的消息生成一个MessageId对象,内容为
<RootId,消息ID>,消息ID为一个long类型的随机数,并且Spout会以RootId为键,以消息为值,放到自己的pending Map中,并且只保留一段时间,具体时间由topology.message.timeout.secs决定,超时后则调用Spout的fail方法。- Spout发送消息出去后,给Acker Blot发射一条Tuple消息,消息的内容为[tuple-id,ack-val,task-id]。tuple-id为消息的RootId,Spout发送的消息有一个或者多个接受目标Task,对所有的目标Task的消息ID进行异或操作,得到一个
ack-val。task-id为Spout的ID,这样Acker就知道是哪个Spout发送过来的Ack消息。并且有多个Acker Bolt的时候,可以根据task-id进行一致性哈希,同一个task-id的Ack消息可以确保被同一个Acker Bolt进行跟踪。发送消息的StreamId是__ack_init(ACKER-INIT-STREAM_ID)。- Acker Bolt收到StreamId为
CKER-INIT-STREAM_ID的消息后,会在自己的pending对象(TimeCacheMap)中添加一条记录{tuple-id:{task-id:ack-val}},记录中的各项值从Spout中发送过来。- Bolt收到的消息中(来自于Spout或者父Blot)同样会包含MessageId对象。Bolt在发射消息的过程中,对每个需要接受该消息的Task,会创建一个新的MessageId对象。该MessageId对象会发送给目标Task,并且该MessageId中的消息ID和接受到的消息ID进行异或操作,把得到的ack-val发送个Acker Bolt.发送给Acker的消息内容为
<tuple-id, ack-val>,消息的StreamId为__ack_ack(ACKER_ACK_STREAM_ID)。- Acker Bolt收到StreamId为
ACKER_ACK_STREAM_ID的消息后,根据tuple-id从pending中取出老的ack-val,并将新老ack-val进行异或操作,更新到pengding中。
6.如果上一步的异或结果为0,这Acker Bolt认为从Spout发出的消息都已经正确处理完毕了,就会给Spout发送通知。消息的内容为tuple-id,StreamId为_ack_ack(ACKER_ACK_STREAM_ID)。- Spout收到StreamId为ACKER_ACK_STREAM_ID的消息,则将pending Map中的tuple-id记录删除,并调用Spout的ack方法。
- 如果在第1步中的Spout在发射消息的时候,不指定消息ID,则Storm不会启用Ack跟踪。如果系统中不含Acker Blot,也不会启用Ack。
- 如果Bolt调用了fail方法,会给Acker Bolt发送StreamId为
__ack_fial(ACKER_FAIL_STREAM_ID)消息。Acker Bolt收到ACKER_FAIL_STREAM_ID消息,会将该消息转发给对应的Spout。Spout收到fail消息后,则执行Spout的fail方法。- Acker Bolt的pending中,只保存一段时间的跟踪消息,具体时间由
topology.message.timeout.secs决定,超过这个时间,就会删除这个tuple-id的跟踪信息。如果后续收到Blot发送的跟踪消息,则会触发Acker发送ACKER_FAIL_STREAM_ID的消息。
Ack框架的执行过程如图:
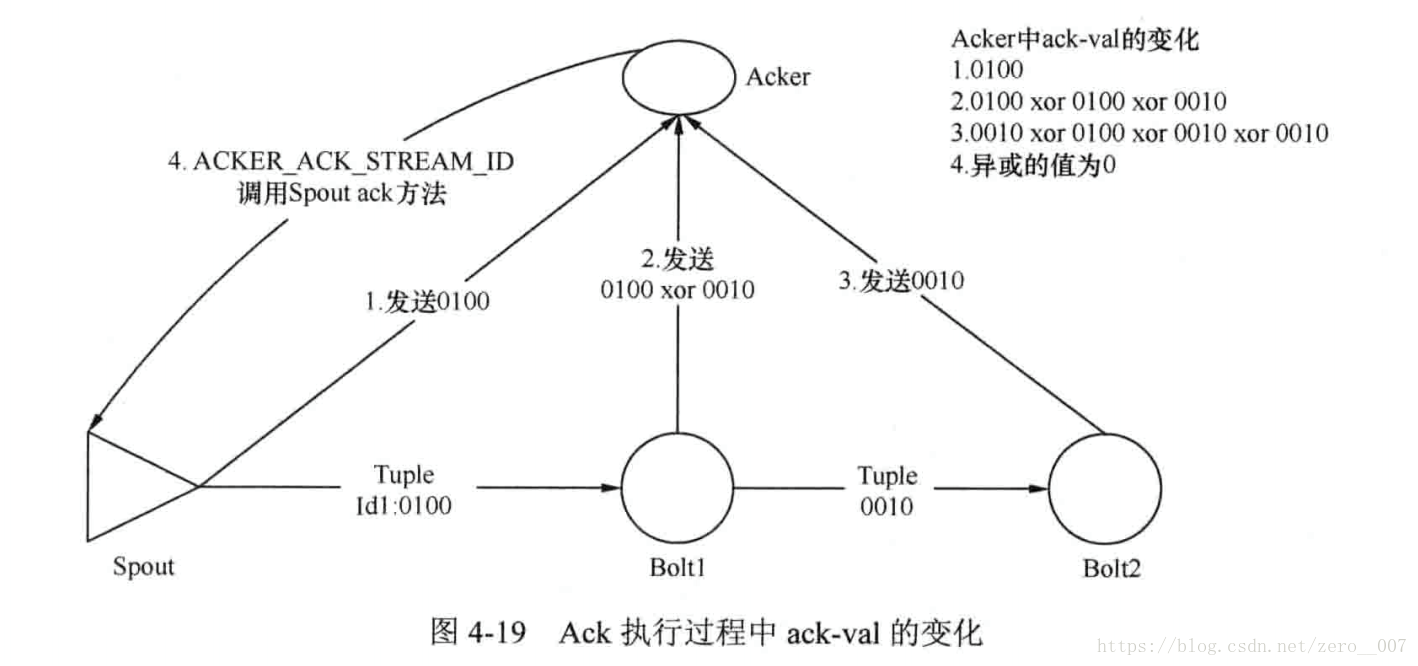
- Spout产生一个Tiple,其初始的消息ID为0100,Spout同时将该消息ID发送给Acker和Bolt1。
- Bolt1收到Spour发送过来的消息ID为0100的消息,经过处理后,产生了新的消息,消息ID为0010,Bolt1就将0100 xor 0010 的结果发送给Acker。
- Bolt2收到Bolt1的消息,处理完成后,没有后续的消息产生,则直接将Bolt1的消息ID转发给了Acker。
- Acker中,此时ack-val值已经为0了,因此在StreamId为
ACKER_ACK_STREAM_ID的流上发送相应的消息。Spout收到消息后,调用Spout的ack方法,完后整个消息流的ack操作,确认所有的消息都被处理了。
如果可靠性对你来说不是那么重要,那么你可以通过不跟踪这些tuple树来获取更好的性能。不去跟踪消息的话会使得系统里面的消息数量减少一半,因为对于每一个tuple都要发送一个ack消息。并且它需要更少的id来保存下游的tuple,减少带宽占用。
有三种方法可以去掉可靠性:
第一是把Config.TOPOLOGY_ACKERS设置成 0. 在这种情况下, storm会在spout发射一个tuple之后马上调用spout的ack方法。也就是说这个tuple树不会被跟踪。
第二个方法是在tuple层面去掉可靠性。 你可以在发射tuple的时候不指定messageid来达到不跟粽某个特定的spout tuple的目的。
最后一个方法是如果你对于一个tuple树里面的某一部分到底成不成功不是很关心,那么可以在发射这些tuple的时候unanchor它们。 这样这些tuple就不在tuple树里面, 也就不会被跟踪了。
来看下Storm所有可能的失败场景,并看看storm在每种情况下是怎么避免数据丢失的。
1. 由于对应的task挂掉了,一个tuple没有被ack: storm的超时机制在超时之后会把这个tuple标记为失败,从而可以重新处理。
2. Acker挂掉了: 这种情况下由这个acker所跟踪的所有spout tuple都会超时,也就会被重新处理。
3. Spout挂掉了: 在这种情况下给spout发送消息的消息源负责重新发送这些消息。比如Kestrel和RabbitMQ在一个客户端断开之后会把所有”处理中“的消息放回队列。
集群的各级容错
任务级失败
- 因为bolt任务crash引起的消息未被应答。此时,acker中所有与此bolt任务关联的消息都会因为超时而失败,对应spout的fail方法将被调用。
- acker任务失败。如果acker任务本身失败了,它在失败之前持有的所有消息都将会因为超时而失败。Spout的fail方法将被调用。
- Spout任务失败。这种情况下,Spout任务对接的外部设备(如MQ)负责消息的完整性。例如当客户端异常的情况下,kestrel队列会将处于pending状态的所有的消息重新放回到队列中。
任务槽(slot) 故障
- worker失败。每个worker中包含数个bolt(或spout)任务。supervisor负责监控这些任务,当worker失败后,supervisor会尝试在本机重启它。
- supervisor失败。supervisor是无状态的,因此supervisor的失败不会影响当前正在运行的任务,只要及时的将它重新启动即可。supervisor不是自举的,需要外部监控来及时重启。
- nimbus失败。nimbus是无状态的,因此nimbus的失败不会影响当前正在运行的任务(nimbus失败时,无法提交新的任务),只要及时的将它重新启动即可。nimbus不是自举的,需要外部监控来及时重启。
集群节点(机器)故障
- storm集群中的节点故障。此时nimbus会将此机器上所有正在运行的任务转移到其他可用的机器上运行。
- zookeeper集群中的节点故障。zookeeper保证少于半数的机器宕机仍可正常运行,及时修复故障机器即可。

















 7615
7615

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









