




 本文详细介绍了Kafka的底层日志结构,包括其分区、Segment、.log文件和索引文件(如OffsetIndex、TimeIndex等)的运作机制。重点讨论了如何通过二分查找算法高效访问数据,以及Kafka对二分查找的优化,特别是通过划分热区和冷区以减少缺页中断。
本文详细介绍了Kafka的底层日志结构,包括其分区、Segment、.log文件和索引文件(如OffsetIndex、TimeIndex等)的运作机制。重点讨论了如何通过二分查找算法高效访问数据,以及Kafka对二分查找的优化,特别是通过划分热区和冷区以减少缺页中断。
转载自:https://baijiahao.baidu.com/s?id=1770010432876434780&wfr=spider&for=pc
Kafka的底层日志结构
基本结构的展示:
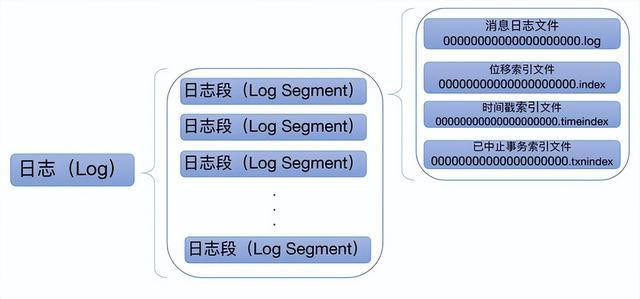
每个Topic都包含一个或多个Partition,不同Partition可位于不同节点。同时Partition在物理上对应一个本地文件夹(也就是个日志对象Log),每个Partition包含一个或多个Segment,每个Segment包含一个数据文件和多个与之对应的索引文件。在逻辑上,可以把一个Partition当作一个非常长的数组,可通过这个“数组”的索引(offset)去访问其数据。
一个segment包含一个.log后缀的文件和多个index后缀的文件。
.log文件:具体存储消息的日志文件
.index文件:位移索引文件,可根据消息的位移值快速地从查询到消息的物理文件位置
.timeindex文件:时间戳索引文件,可根据时间戳查找到对应的位移信息
.txnindex文件:已中止事物索引文件
除了.log是实际存储消息的文件以外,其他的几个文件都是索引文件。索引本身设计的原来是一种空间换时间的概念,在这里kafka是为了加速查询所使用。
kafka索引不会为每一条消息建立索引关系,这个也很好理解,毕竟对一条消息建立索引的成本还是比较大的,所以它是一种稀疏索引的概念,就好比我们常见的跳表,都是一种稀疏索引。
kafka日志的文件名一般都是该segment写入的第一条消息的起始位移值baseOffset,比如000000000123.log,这里面的123就是baseOffset,具体索引文件里面纪录的数据是相对于起始位移的相对位移值relativeOffset,baseOffset与relativeOffse的加和即为实际消息的索引值。假设一个索引文件为:00000000000000000100.index,那么起始位移值即 100,当存储位移为 150 的消息索引时,在索引文件中的相对位移则为 150 - 100 = 50,这么做的好处是使用 4 字节保存位移即可,可以节省非常多的磁盘空间。
kafka索引文件
每个索引文件包含若干条索引项。不同索引文件的索引项的大小不同,比如offsetIndex索引项大小是8B,timeIndex索引项的大小是12B。

上图是OffsetIndex的结构,位移值用 4 个字节来表示,物理磁盘位置也用 4 个字节来表示。可能会疑问,位移值offset不是长整型吗,应该是 8 个字节才对啊?这是因为offset=baseOffset+relativeOffse,使用相对位移值可以节省磁盘空间。
注意,relativeOffse是4字节,那么就限定了kafka中的每个日志段文件的大小不会超过2^32=4GB。
TimeIndex 中的时间戳类型是长整型,占用 8 个字节,位移依然使用相对位移值, 占用 4 个字节,因此总共需要 12 个字节。
kafka对索引文件的存取用到了零拷贝技术—mmap,即 Java 中的 MappedByteBuffer。mmap是一种内存映射文件的方法,即将一个文件或者其它对象映射到进程的地址空间,实现文件磁盘地址和进程虚拟地址空间中一段虚拟地址的一一对映关系。在很多操作系统中(比如 Linux),这段映射的内存区域实际上就是内核的页缓存 (Page Cache)。这就意味着,里面的数据不需要重复拷贝到用户态空间,避免了很多不 必要的时间、空间消耗。
kafka的二分查找算法
1)普通二分查找
offsetIndex每个索引项大小是8B,但操作系统访问内存时的最小单元是页,一般是4KB,即4096B,会包含了512个索引项。而找出在索引中的指定偏移量,对于操作系统访问内存时则变成了找出指定偏移量所在的页。
假设索引的大小有13个页,如下图所示:

由于Kafka读取消息,一般都是读取最新的偏移量,所以要查询的页就集中在尾部,即第12号页上。根据二分查找,将依次访问6、9、11、12号页。

当随着Kafka接收消息的增加,索引文件也会增加至第13号页,这时根据二分查找,将依次访问7、10、12、13号页。

可以看出这次访问的页和上一次的页完全不同。
之前在只有12号页的时候,Kafak读取索引时会频繁访问6、9、11、12号页,而由于Kafka使用了mmap来提高速度,即读写操作都将通过操作系统的page cache,所以6、9、11、12号页会被缓存到page cache中,避免磁盘加载。
但是当增至13号页时,则需要访问7、10、12、13号页,而由于7、10号页长时间没有被访问(现代操作系统都是使用LRU或其变体来管理page cache),很可能已经不在page cache中了,那么就会造成缺页中断(Page Fault)(线程被阻塞等待从磁盘加载没有被缓存到page cache的数据)。在Kafka的官方测试中,这种情况会造成几毫秒至1秒的延迟。
2)kafka优化的二分查找
Kafka对二分查找进行了改进。既然一般读取数据集中在索引的尾部。那么将索引中最后的 8192B(8KB)划分为“热区”(刚好缓存两页数据),其余部分划分为“冷区”,分别进行二分查找。这样做的好处是,在频繁查询尾部的情况下,尾部的页基本都能在page cahce中,从而避免缺页中断。
下面我们还是用之前的例子来看下。由于每个页最多包含512个索引项,而最后的1024个索引项所在页会被认为是热区。那么当12号页未满时,则10、11、12会被判定是热区;而当12号页刚好满了的时候,则11、12被判定为热区;当增至13号页且未满时,11、12、13被判定为热区。假设我们读取的是最新的消息,则在热区中进行二分查找的情况如下:
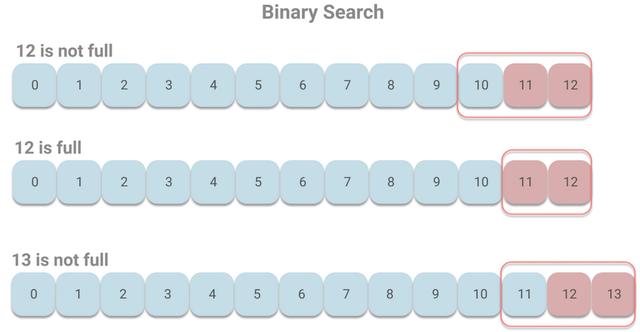
当12号页未满时,依次访问11、12号页,当12号页满时,访问页的情况相同。当13号页出现的时候,依次访问12、13号页,不会出现访问长时间未访问的页,则能有效避免缺页中断。

















 2605
2605

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









