 使用Python爬取微博数据:步骤详解,
使用Python爬取微博数据:步骤详解,





 本文详细介绍了如何通过Python的weiboSpider项目,从GitHub下载代码,安装依赖,配置cookie,设置爬取参数,以及执行脚本来爬取微博数据的过程。
本文详细介绍了如何通过Python的weiboSpider项目,从GitHub下载代码,安装依赖,配置cookie,设置爬取参数,以及执行脚本来爬取微博数据的过程。
1、安装Git

2、下载项目
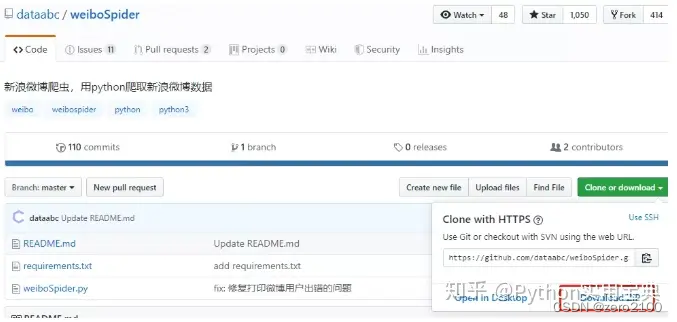
进入下方的网址,点击Download ZIP下载项目文件
用Git命令下载 git clone https://github.com/dataabc/weiboSpider.git
3、安装项目依赖
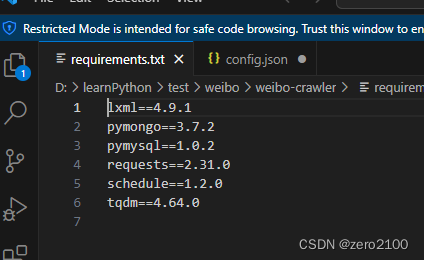
将该项目压缩包解压后,打开你的cmd/Termianl进入该项目目录,输入以下命令:
pip install -r requirements.txt便会开始安装项目依赖,等待其安装完成即可。
4. 登录微博
Python 超简单爬取新浪微博数据 (高级版) - 知乎 (zhihu.com)
打开weibospider文件夹下的weibospider.py文件,将"your cookie"替换成爬虫微博的cookie,具体替换位置大约在weibospider.py文件的22行左右。cookie获取方法:
5、设置要爬取的user_id
打开config.json文件,进行修改:
{
"user_id_list": "user_id_list.txt",
"only_crawl_original": 1,
"since_date": 10,
"start_page": 1,
"write_mode": [
"csv"
],
"original_pic_download": 1,
"retweet_pic_download": 0,
"original_video_download": 1,
"retweet_video_download": 0,
"download_comment": 1,
"comment_max_download_count": 1000,
"download_repost": 1,
"repost_max_download_count": 1000,
"user_id_as_folder_name": 0,
"remove_html_tag": 1,
"cookie": "your cookie",
"mysql_config": {
"host": "localhost",
"port": 3306,
"user": "root",
"password": "123456",
"charset": "utf8mb4"
},
"mongodb_URI": "mongodb://[username:password@]host[:port][/[defaultauthdb][?options]]"
}
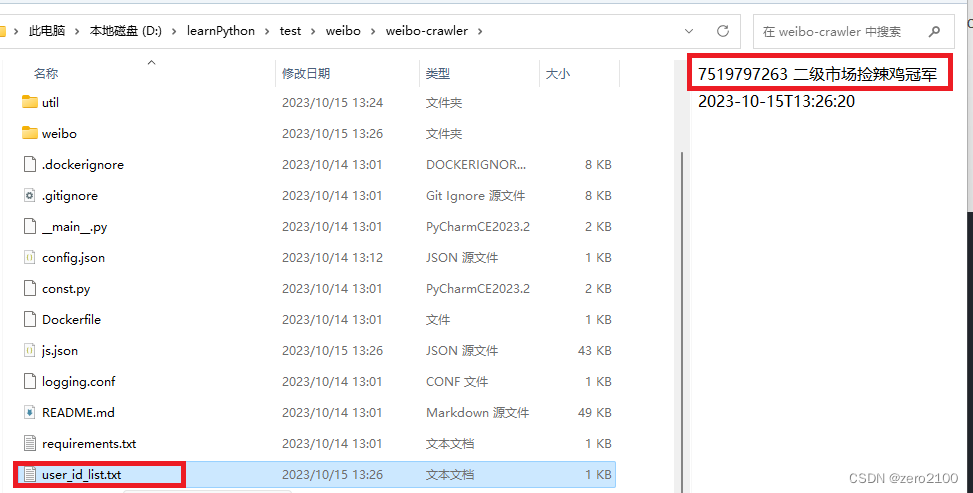
6、执行脚本
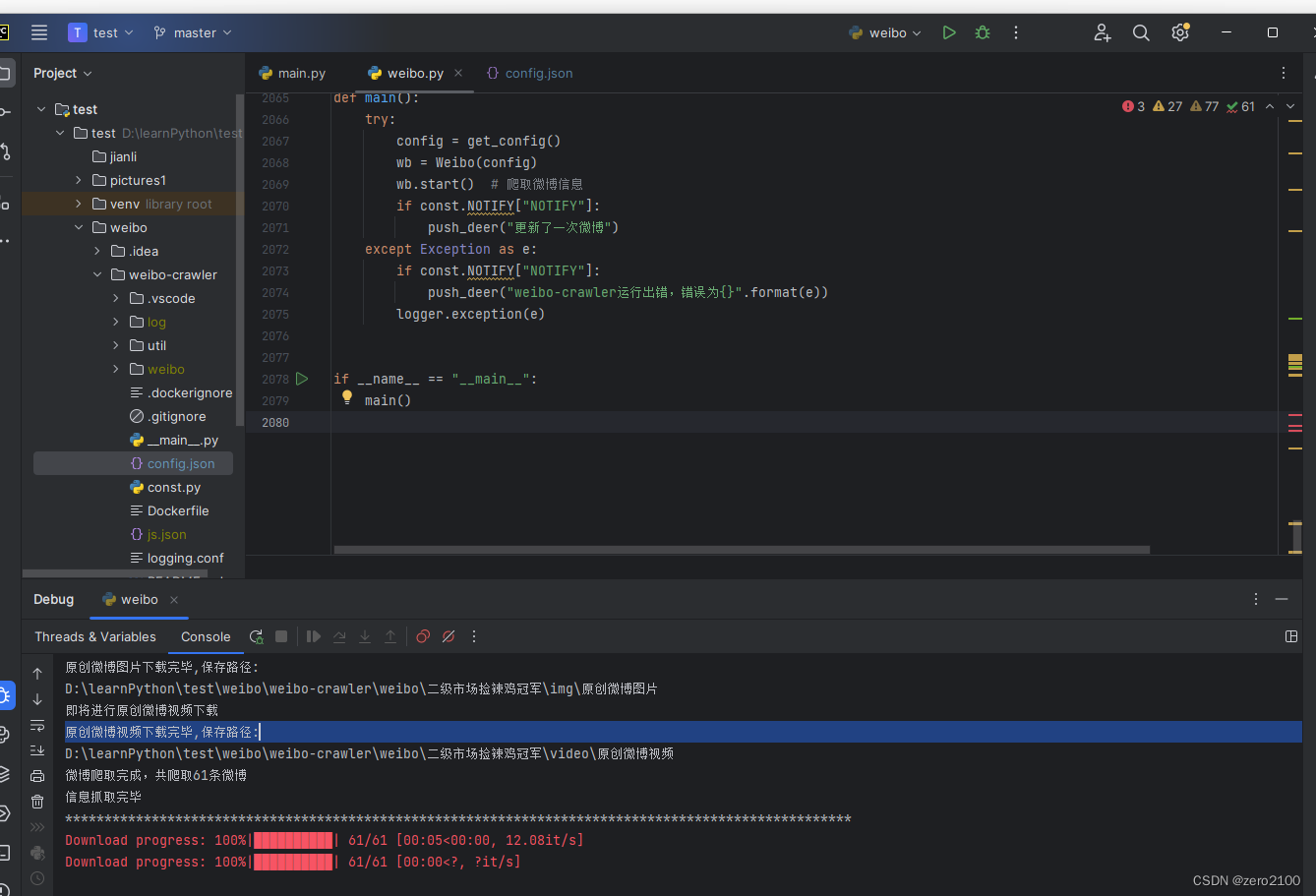
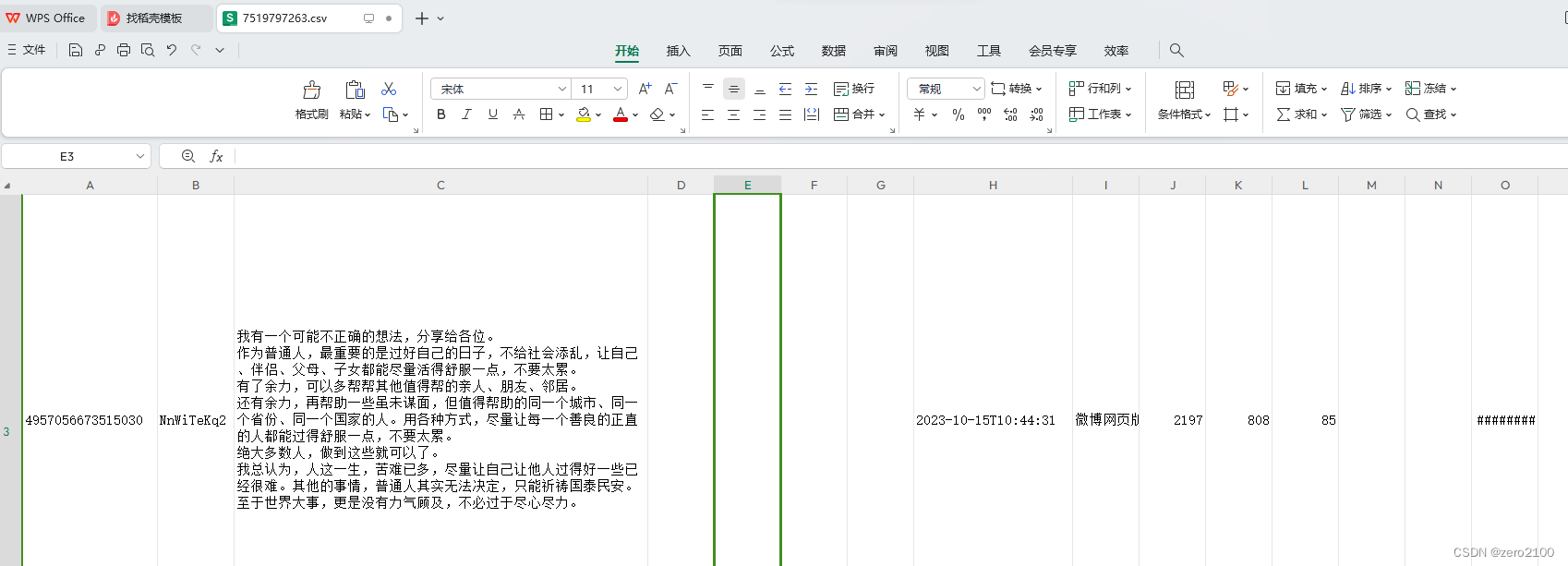
爬到的结果



















 3725
3725

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











