



 本文讲解了如何使用Python的urllib模块进行基础网络抓取,并通过BeautifulSoup4解析HTML结构,实现豆瓣电影评论的爬取。
本文讲解了如何使用Python的urllib模块进行基础网络抓取,并通过BeautifulSoup4解析HTML结构,实现豆瓣电影评论的爬取。
1、Python urllib 模块是什么
urllib 模块是 Python 标准库,其价值在于抓取网络上的 URL 资源,入门爬虫时必学的一个模块。
from urllib.request import urlopen
def print_hi(name):
# Use a breakpoint in the code line below to debug your script.
print(f'Hi, {name}') # Press Ctrl+F8 to toggle the breakpoint.
# Press the green button in the gutter to run the script.
if __name__ == '__main__':
print_hi('PyCharm')
with urlopen('https://edu.youkuaiyun.com/') as html:
page = html.read()
print(page)
print_hi('PyCharm')
2、beautifulsoup4 使用 pip install beautifulsoup4
#code:utf-8
import requests
from bs4 import BeautifulSoup
import time
# 如果想多爬几页可以将16修改为更大的偶数
for i in range(2,16,2):
url = 'https://movie.douban.com/subject/34841067/comments?start={}0&limit=20&status=P&sort=new_score'.format(i)
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.5 Safari/605.1.15'
}
# 请求
r=requests.get(url, headers=headers)
# 查看状态码
print(r.status_code)
# 获取标题
html = BeautifulSoup(r.text,"html.parser")
title = html.find("h1").text
# 获取用户名、评论、评分
divs = html.find_all("div", class_ = "comment")
s = {"力荐":"❤❤❤❤❤","推荐":"❤❤❤❤❤","还行":"❤❤❤","较差":"❤❤","很差":"❤"}
with open("{}.txt".format(title),"w+",encoding="utf-8") as f:
f.write(str(["用户", "评分", "内容"]))
for div in divs:
print("---------------------------------")
name = div.find("a", class_="").text
print("用户名:",name)
content = div.find("span", class_="short").text
print("用户评论:",content)
score = None
for i in range(1,6):
try:
score = s[div.find("span", class_="allstar{}0 rating".format(i))["title"]]
except:
continue
if score == None:
score = "用户未评分"
print("评分:",score)
print("[+]...{}的评论已爬取".format(name))
f.write("\n")
f.write(str([name,score,content]))
f.close()
以下是控制台的输出结果:
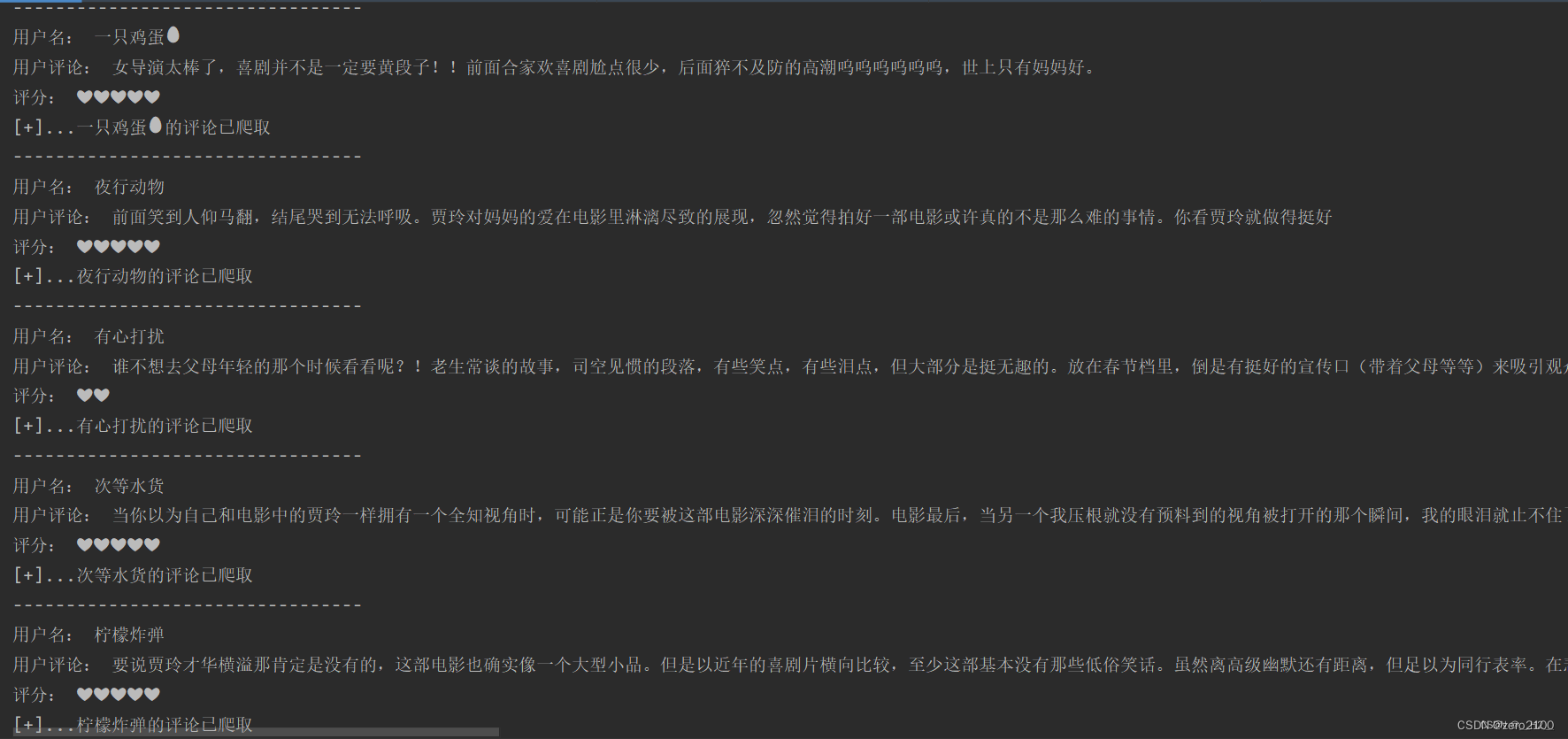
会生成一个以电影名为名字的txt的文件,我们爬取到的数据全部保存在其中,如下: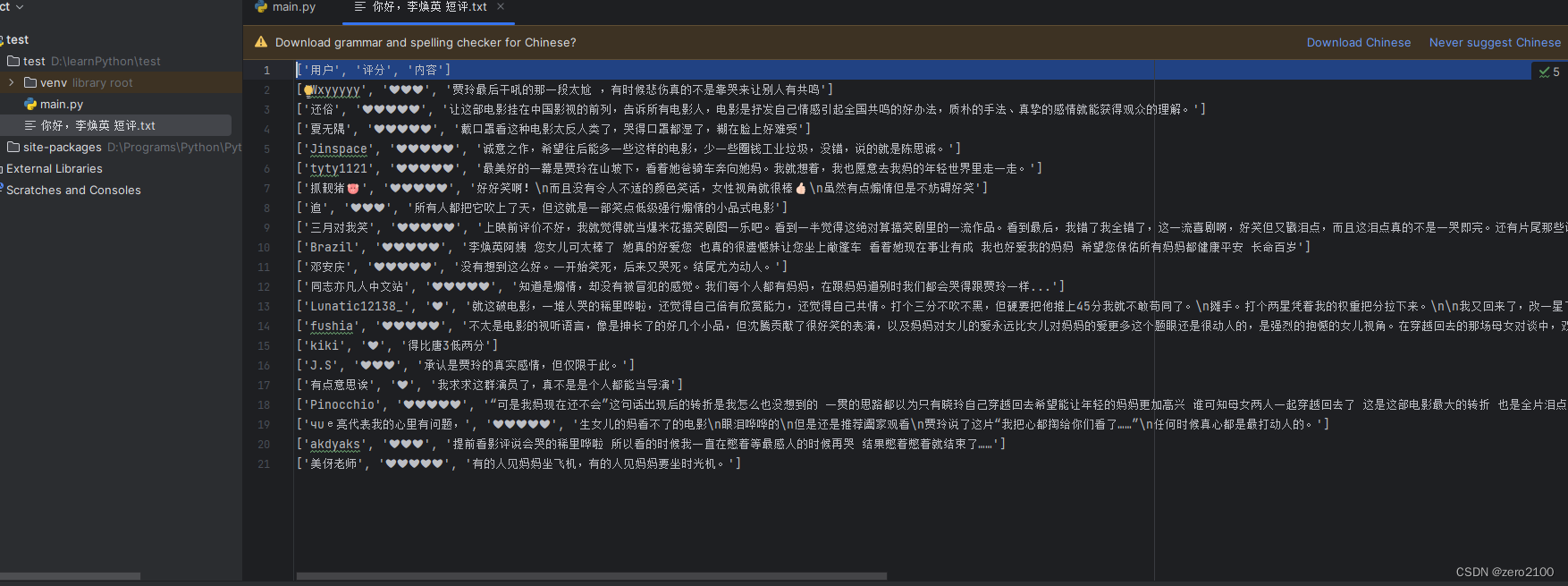


















 26万+
26万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











