







 本文介绍了Facebook AI的VQ-WAV2VEC,一种在WAV2VEC基础上的自监督离散语音表示学习方法。它通过Gumbel-Softmax或K-means聚类将连续信号转化为离散特征,便于像BERT处理文本一样处理。实验表明,VQ-WAV2VEC结合BERT在声学模型性能上优于原始WAV2VEC。
本文介绍了Facebook AI的VQ-WAV2VEC,一种在WAV2VEC基础上的自监督离散语音表示学习方法。它通过Gumbel-Softmax或K-means聚类将连续信号转化为离散特征,便于像BERT处理文本一样处理。实验表明,VQ-WAV2VEC结合BERT在声学模型性能上优于原始WAV2VEC。
1 简介
本文根据2019年《VQ-WAV2VEC: SELF-SUPERVISED LEARNING OF DISCRETE SPEECH REPRESENTATIONS》翻译总结的。是Facebook AI 继WAV2VEC之后的创作,是WAV2VEC基础上的发展。
WAV2VEC详见https://blog.youkuaiyun.com/zephyr_wang/article/details/127821501
如文章题目所述,是对离散语音变量的学习,文章引入了两种量化方法,gumbel softmax或者k-means clustering来进行离散化,类似VQ-VAE。离散化后就可以类似NLP那样处理了,如BERT处理的也是文本这种离散化的数据。
如下图所示,VQ-WAV2VEC离散化后输入BERT模型,然后再输入声学模型AM。实验发现VQ-WAV2VEC+BERT比WAV2VEC或者log-mel filterbank输入声学模型的效果好。
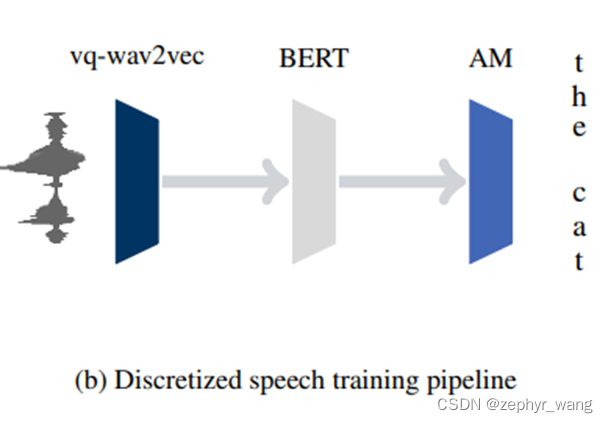
2 VQ-WAV2VEC
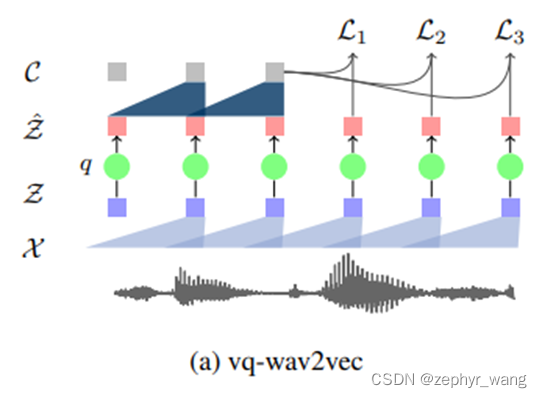

量化模型有两种方法,gumbel softmax或者k-means clustering。
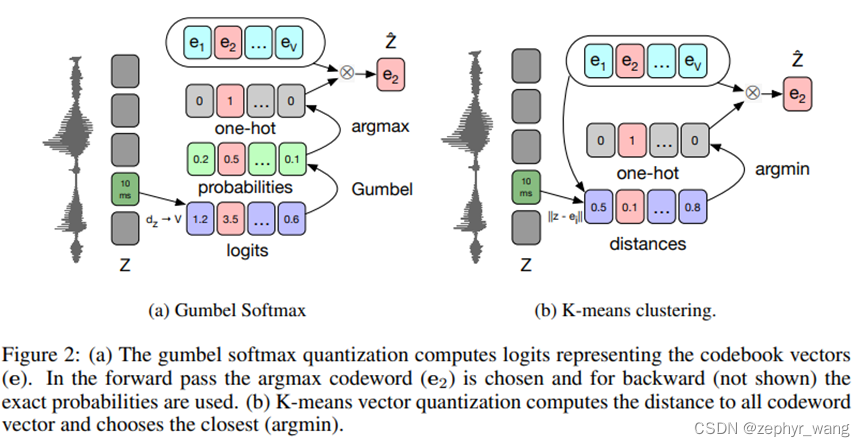
2.1 gumbel softmax
主要是看上图a,对z应用一个线性层,接着一个ReLU,然后一个线性输出logit,然后进行gumbel softmax。具体公式如下:

2.2 k-means
如上图b,主要是比较z与e的距离, 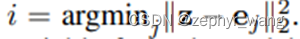
损失函数在WAV2VEC上增加了两项,

3 实验结果
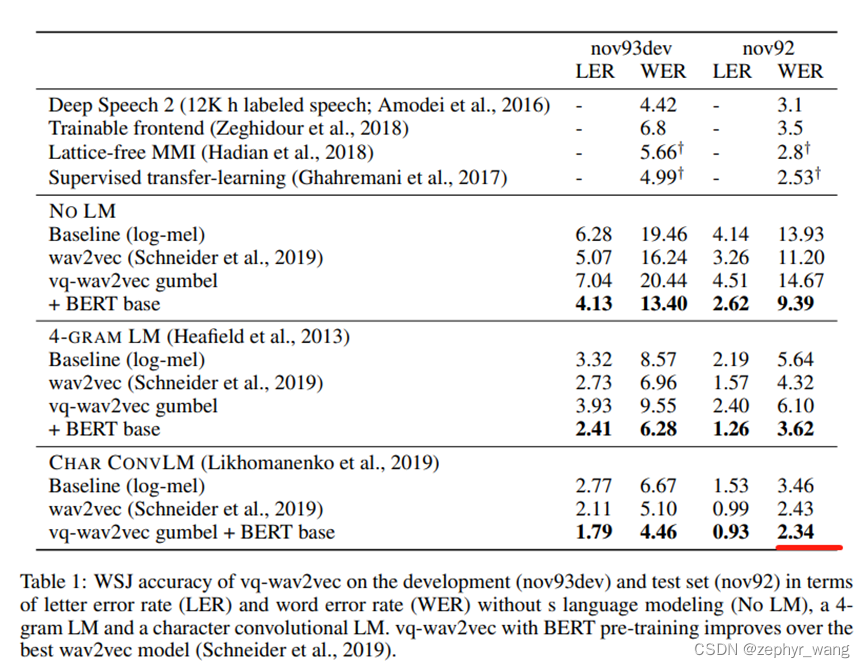
如下表,vq-wav2vec with BERT好于wav2vec。
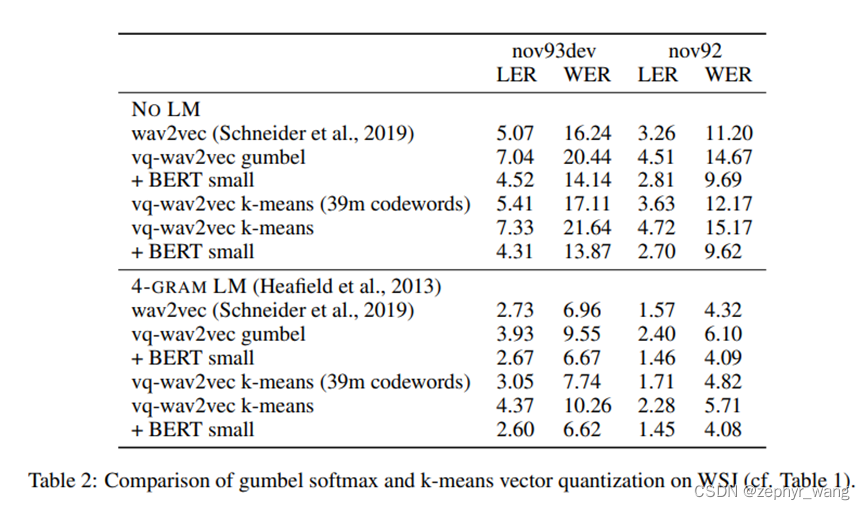
下表说明gumbel softmax 和 k-means方法效果差不多。

















 658
658

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









