




深入研究多模态大模型的对齐策略
yearn 大模型生态圈 2024年11月22日 11:40 四川

多模态大模型(MLLMs)虽然在视觉与语言理解任务上取得了显著进展,但仍面临“幻觉”现象,即生成的描述可能不符合视觉内容。为了解决这一问题,研究人员提出了偏好对齐(preference alignment)方法来增强模型与图像内容的契合度。然而,由于偏好数据集、基模型类型和对齐方法的差异,目前尚不清楚具体哪些因素对性能提升最为关键。因此,本研究旨在通过独立分析各个因素,探索不同的对齐方法对MLLMs性能的影响。
主要贡献
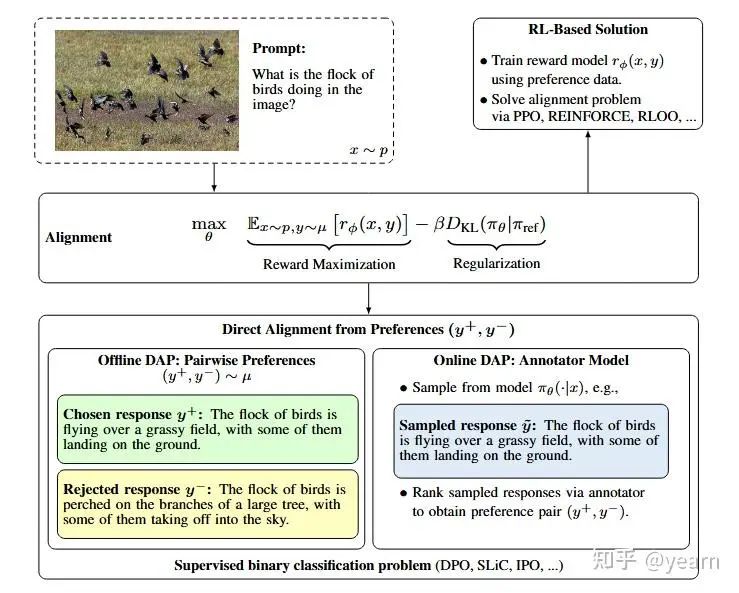
1.对齐方法分类:本文将偏好对齐方法分为离线方法(如DPO)和在线方法(如在线DPO),并证明结合离线和在线方法可在某些情况下进一步提升模型性能。
2.偏好数据集分析:回顾了多种已发布的多模态偏好数据集,并分析其构建细节如何影响模型表现,提供了对数据集在不同应用场景下的性能影响的全面见解。
3.偏好数据采样新方法:提出了“偏差驱动幻觉采样”(Bias-Driven Hallucination Sampling, BDHS),无需额外的人工标注或外部模型支持,仅依赖于偏差驱动的采样,即可生成具有竞争力的对齐数据。
4.系统化实验验证:在多个基准任务上验证BDHS的效果,展示了其在减少幻觉现象方面的有效性,与更大规模的偏好数据集相比,BDHS依然表现出色。
技术细节
多模态偏好数据的组成
多模态偏好数据通常由一个或多个多模态大语言模型(MLLMs)生成的响应构建,且通常不包含待对齐的模
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1086
1086

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









