




 本文详细介绍Hadoop集群的搭建过程,包括环境配置、JDK与Hadoop安装、集群免密码登录设置等关键步骤,并演示如何进行格式化、启动及web访问。此外,还提供了HDFS命令使用、Eclipse开发环境配置、Maven与Tomcat安装,以及Hadoop网盘应用的实例。
本文详细介绍Hadoop集群的搭建过程,包括环境配置、JDK与Hadoop安装、集群免密码登录设置等关键步骤,并演示如何进行格式化、启动及web访问。此外,还提供了HDFS命令使用、Eclipse开发环境配置、Maven与Tomcat安装,以及Hadoop网盘应用的实例。
hadoop环境搭建
1,概念
``1.1,理论
1)集群:指的是多台设备构成一个完整的应用,这些多台设备就构成一个集群
2)hadoop
hadoop=hdfs+运算框架。
hadoop的运算框架有两种:mapreduce(第一代运算框架)和 yarn(第二代运算框架)
3)hdfs
hdfs=hadoop dfs;d->分布式,fs->filesystem(文件系统)
4)mapreduce
hadoop第一代运算框架,hadoop的底层运算框架
5)yarn
hadoop第二代运算框架,yarn必须在第一代运算框架启动后才能用
``1.2,术语
1)m/s:
指的是master(主)/slave(从)结构,既主从结构;
一个管理者(master)多个工作者(slave)。master负责分配与派发任务,
slave负责执行任务。主机是:namenode,从机是:datanode
2)公钥
公钥是一对加密代码,发送给其他设备后,就能免密码登录其他设备
3)免密码登录
集群节点之间通信不需要输入密码也能互相登录发送信息。实现方式是通过公钥实现的
2,hadoop集群搭建
2.1,集群配置方案
``以下是集群设备配置方案:
| 角色 | 网络用户名 | 用户名 | 用户组 | ip | 子网掩码 | 网关 | dns |
|---|---|---|---|---|---|---|---|
| master | node1 | hduser | hadoop | 192.168.3.101 | 255.255.255.0 | 192.168.3.1 | |
| slave | node2 | hduser | hadoop | 192.168.3.102 | 255.255.255.0 | 192.168.3.1 | |
| slave | node3 | hduser | hadoop | 192.168.3.103 | 255.255.255.0 | 192.168.3.1 |
master :管理者
slave:工作者
2.2,linux环境搭建
1)创建用户与用户组:用户名:hduser;用户组:hadoop
2)修改网络用户名(/etc/sysconfig/network)
打开network配置文件:sudo vi /etc/sysconfig/network,修改hostname值为node1
3)修改本地主机名(网络用户名)域名解析记录
1,打开host配置文件:vi /etc/hosts
2,增加如下内容:
192.168.3.51 node1
192.168.3.52 node2
192.168.3.53 node3
4)更改用户拥有超级用户角色(/etc/sudoers)
1,修改sudoers权限为可编辑:chmod 777 /etc/sudoers
2,打开sudoers文件增加内容:vi /etc/sudoers
3,在root ALL=(ALL) ALL内容下面增加如下内容:
hduser ALL=(ALL) ALL
4,将sudoers权限改回440:chmod 440 /etc/sudoers
5,配置ip 子网掩码 网管 dns 配置如下图片:
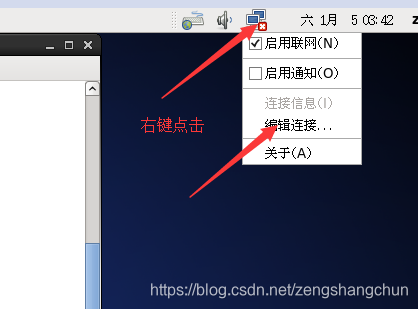
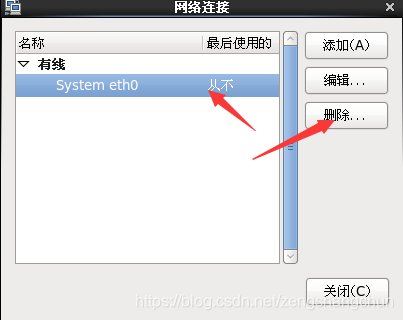
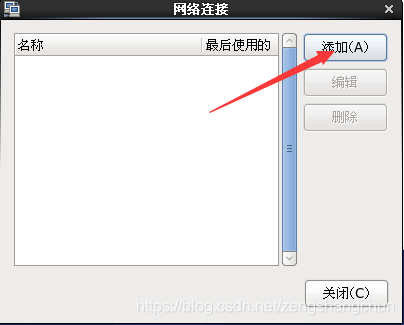
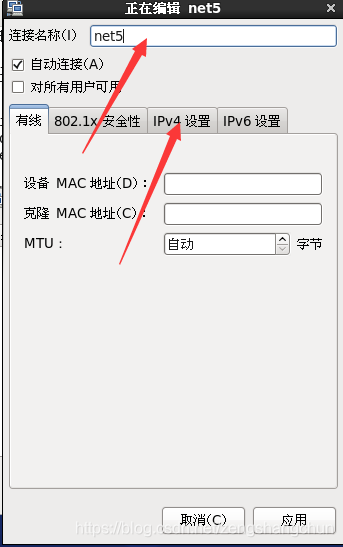
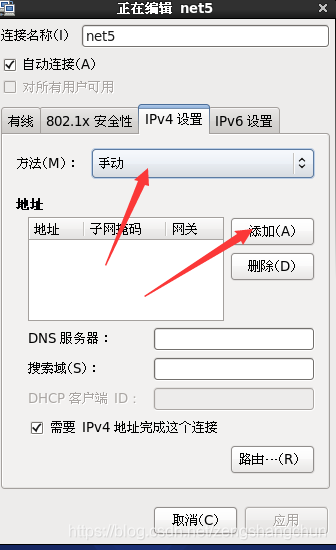
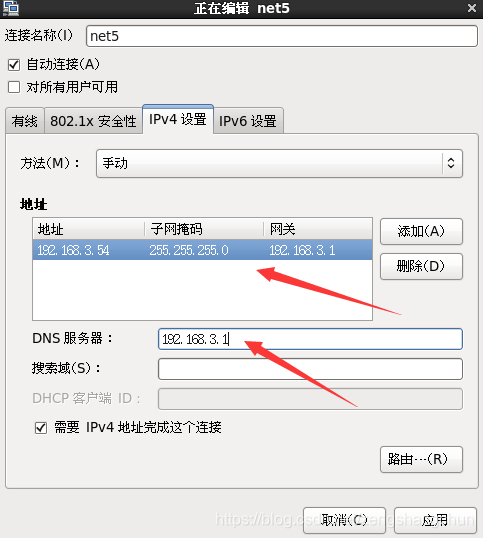
6,防火墙服务关闭
service iptables stop
chkconfig iptables off
````````````````以上是集群中每一台都要配置`````````````````
``````````以下操作都是用hduser操作,不能用root操作```````````
7,克隆两台设备,分别是node2,node3(安装了jdk后再克隆,安装步骤在2.3.1)
主机名上右键-管理-克隆;
完成后启动, 配置ip 子网掩码 网管 dns
修改网络用户名:sudo vi /etc/sysconfig/network,修改hostname值为node2
8,集群设备之间免密码登录(hduser帐户操作)
A,在node1上生成公钥
ssh-keygen -t rsa 然后直接回车就好,不用输入东西
B,将node1的公钥派发给node2
ssh-copy-id node2
C,将node1的公钥派发给node3
ssh-copy-id node3
D,将node1的公钥派发给node1
ssh-copy-id node1
E,将node1的公钥派发给node1的localhost
ssh-copy-id localhost
F,将node1的公钥派发给node1的127.0.0.1
ssh-copy-id 127.0.0.1
完成后测试:ssh node2
2.3,hadoop集群搭建
``2.3.1,jdk安装(/usr/java)
1)yum卸载已经安装的JDK
查看:yum list installed|grep java
卸载:yum remove -y 软件名
2)先获取安装包
3)解压到安装目录
4)JDK配置环境变量(/etc/profile):
打开:vi /etc/profile,在文档最后追加内容:
export JAVA_HOME=/usr/local/java/jdk1.8.0_171
export PATH=$PATH:$JAVA_HOME/bin
5)生效环境变量:
source /etc/profile
6)测试:
java -version
``2.3.2,安装hadoop
1)获取hadoop的 tar 安装包并解压
解压到/home/hduser/下,解压后更改文件夹名为hadoop
解压:tar -zxvf hadoop-2.6.5.tar.gz -C /home/hduser/
改名:mv /home/hduser/hadoop-2.6.5 /home/hduser/hadoop
以上步骤完成后我们获取hadoop主目录:cd /home/hduser/hadoop
2)配置hadoop环境变量(/etc/profile):
打开:vi /etc/profile,在文档最后追加内容:
export HADOOP_HOME=/home/hduser/hadoop
export PATH=/home/hduser/hadoop/bin
3)更改hadoop配置文件(hadoop主目录/etc/hadoop/)
A,hadoop-env.sh (hadoop hdfs 运行环境文件)
更改 JAVA_HOME:export JAVA_HOME=/usr/java/jdk1.8.0_171
B,mapred-env.sh (hadoop mapreduce 运算框架运行环境文件)
更改 JAVA_HOME:export JAVA_HOME=/usr/java/jdk1.8.0_171
C,yarn-env.sh (hadoop yarn 运算框架运行环境文件)
更改 JAVA_HOME:export JAVA_HOME=/usr/java/jdk1.8.0_171
D,slaves (工作者节点的信息)
修改工作者信息如下:
把 localhost 删除,增加下面信息
node2
node3
E,core-site.xml (hadoop 核心配置文件)
注释:fs.defaultFS:该属性配置的dfs的访问入口
注释:hdfs:// :这是hdfs文件系统的访问权限
注释:hadoop.tmp.dir :本地临时文件夹
注释:file:/ :是访问本地文件的协议格式
注释:tmp(临时文件)文件夹默认是不存在的,需要手动创建
在 <configuration> 节点里添加下面内容:
<property>
<name>fs.defaultFS</name>
<value>hdfs://node1:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/hduser/hadoop/tmp</value>
</property>
F,hdfs-site.xml (hdfs 的配置文件)
<!-- namenode 备份节点 访问地址 -->
<property>
<name>dfs.namenode.secordary.http-address</name>
<value>node1:50090</value>
</property>
<!-- namenode 数据存放目录 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/hduser/hadoop/dfs/name</value>
</property>
<!-- datanode 数据存放目录 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/hduser/hadoop/dfs/data</value>
</property>
<!-- 数据备份个数 -->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<!-- 可以通过web访问 完全分布式 -->
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
G,mapred-site.xml (mapreduce 配置文件,如果没有就新建一个或者拷贝一个)
注释:mapreduce.framework.name:配置作业运算框架使用yarn框架
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>node1:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>node1:19888</value>
</property>
H,yarn-site.xml (yarn 配置文件)
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>node1:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>node1:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>node1:8035</value>
</property>
<property>
<name>yarn.resouecemanager.admin.address</name>
<value>node1:8033</value>
</property>
<property>
<name>yarn.resouecemanager.webapp.address</name>
<value>node1:8088</value>
</property>
创建上面第5,6步需要三个文件:新建这三个文件(uduser创建):
/home/hduser/hadoop/tmp/
/home/hduser/hadoop/dfs/name
/home/hduser/hadoop/dfs/data
将node1 的hadoop 文件夹 复制到node2 与node3的hduser对应的文件夹下:
scp -r /home/hduser/hadoop hduser@node2:/home/hduser/
scp -r /home/hduser/hadoop hduser@node3:/home/hduser/
``2.3.3,格式化与启动
1)格式化(只能格式化一次,只须主机格式化,从机也会格式化)
利用hadoop 主目录下bin目录下的hadoop命令格式化
bin/hadoop namenode -format
2)启动
利用hadoop主目录下sbin目录
启动分布式文件系统:sbin/start-dfs.sh
启动运算框架:sbin/start-yarn.sh
3)关闭
利用hadoop主目录下 sbin目录
关闭运算框架:sbin/stop-yarn.sh
关闭分布式文件系统:sbin/stop-dfs.sh
4)内机浏览器web访问分布式系统:http://node1:50070
3,hdfs 命令
下面的命令需要启动hadoop,用完后需要关闭。
``3.1,hdfs命令
1)访问hdfs根目录(/)
bin/hadoop dfs -ls /
2)在hdfs新建目录:/test
bin/hadoop dfs -mkdir /test
3)从本地上传文件a.txt到 hdfs /test/下
bin/hadoop dfs -put ***/a.xtx /test/
4)将hdfs /test/下a.txt 下载到本地桌面并命名为b.txt
bin/hadoop dfs -get /test/a.txt /home/hduser/桌面/b.txt
5)删除hdfs 上 /test 目录
bin/hadoop dfs -rmr /test
4,安装eclipse
``4.1,新下载eclipse 需要安装hadoop-eclipse-plugin-2.6.4.jar插件(该插件需要去网上下载):
1)解压到 /home/hduser/ 目录下(hduser用户操作)
2)eclipse需要hadoop-eclipse-plugin-2.6.4.jar插件,将该插件复制到eclipse/plugins/目录下
3)用命令启动eclipse:eclipse目录/eclipse -clean
4)启动后改变显示视图
window -> show view -> project Explorer
5)在命令启动eclipse后,配置hadoop环境
eclipse -> window -> preference -> Hadoop map/Reduce 右侧配置:
hadoop installation direction:/home/hduser/hadoop
5)打开mappreduce 选项卡
eclipse -> window -> show view -> others -> 搜索并打开 map/Reduce
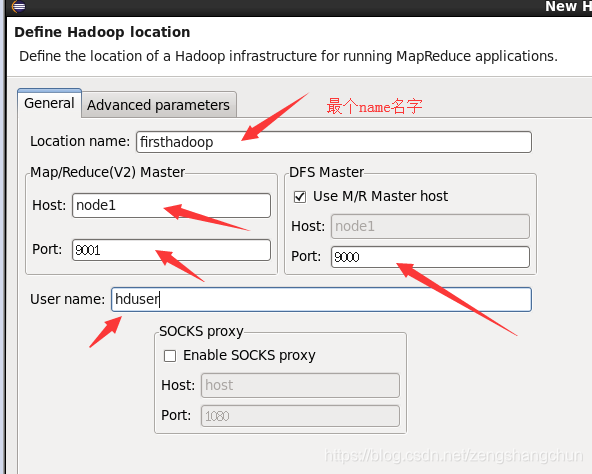
6)在选项卡中 右键点击 new Hadoop location 新增 mapreduce locaion,弹出配置界面
7)弹出配置界面配置如下:
name:取个名字
dfs:node1 9000
mapreduce:node1 9001
8)eclipse 工作空间左侧project explore 选项卡中,点击dfs locations 能看到我们配置的分布式文件
操作步骤图片如下:
5,测试
``5.1,wordcout 单词计数作业
1)node1 本地创建2个记事本 1.txt,2.txt
1.txt:
this is a hadoop text .hadoop is a application .
this is a example .
2.txt:
java
mysql
hadoop
mybatis
2)将node1 本地的 1.txt,2.txt 分别上传到 hdfs /input/下
3)在 hdfs 上新建一个文件夹 /output/ 用于存放计算的结果集
4)利用 hadoop 自带样例 jar 包执行单词计数器运算
自带样例:hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.5.jar
语法:hadoop jar hadoop-mapreduce-examples-2.6.5.jar wordcount 被运算的资源位置 结果输出位置
$>hadoop jar /home/hduser/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.5.jar /input/* /output/wc1
6,安装 maven,mysql,tomcat
maven安装如下:
1)解压tar包
2)配置环境变量:
打开:vi /etc/profile
添加如下内容:
export MAVEN_HOME=/home/hduser/apache-maven-3.6.0
export PATH=$PATH:$MAVEN_HOME/bin
3) 查看安装是否成功:
mvn -version
4)在 /home/hduser/ 下新建工厂目录:
mkdir /home/hduser/repository
5)更改配置文件(settings.xml)
打开配置文件:vi /home/hduser/apache-maven-3.6.0/conf/settings.xml
在 <localRepository> 节点下添加工厂路径:
<localRepository>/home/hduser/repository</localRepository>
在 <mirrors> 节点里添加 阿里云 镜像工厂
<mirror>
<id>alimaven</id>
<name>aliyun maven</name>
<url>http://maven.aliyun.com/nexus/content/repositories/central</url>
<mirrorOf>*</mirrorOf>
</mirror>
6)初始化:
mvn help:system
7,eclipse 开发 hdfs
7.1,eclipse配置maven:
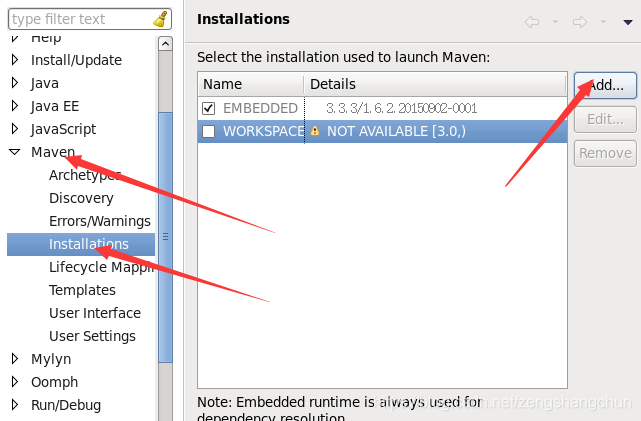
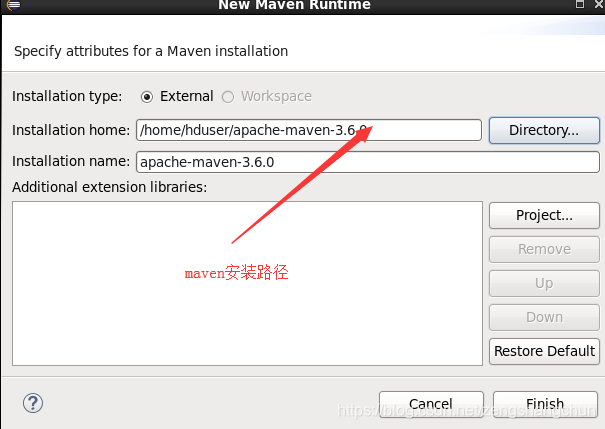
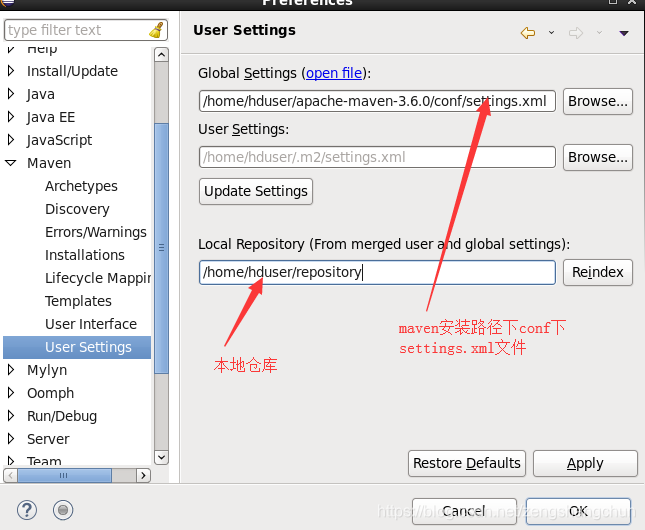
7.2,eclipse配置tomcat:
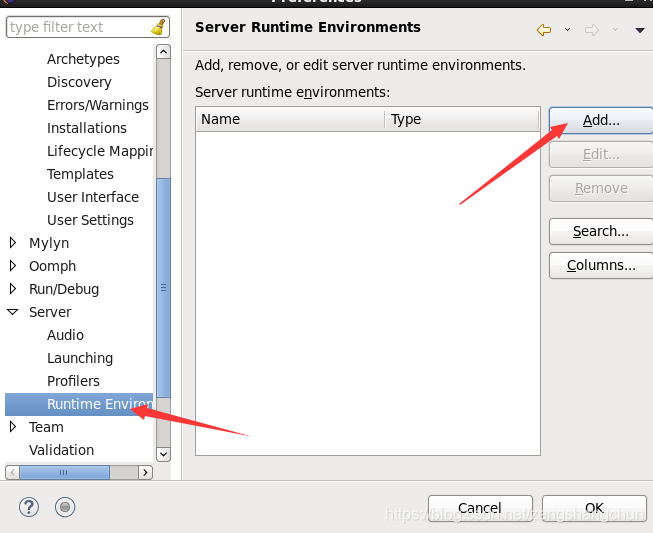
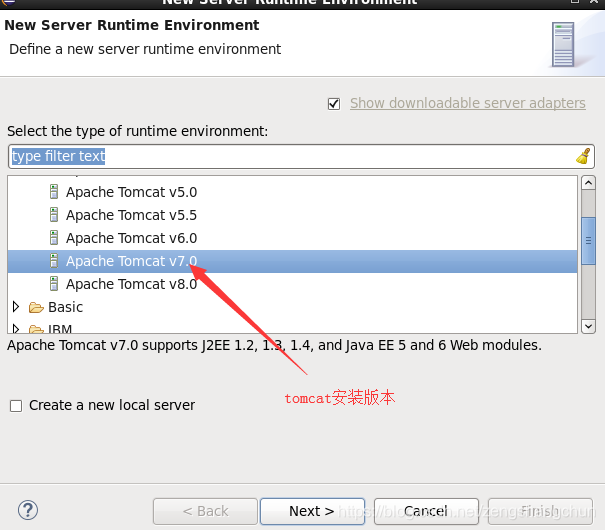
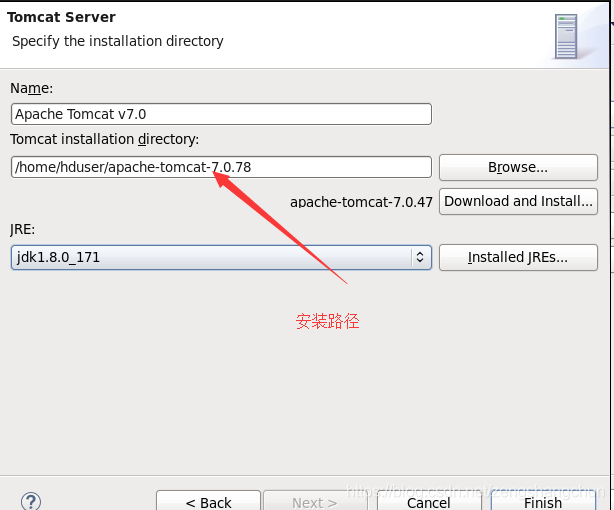
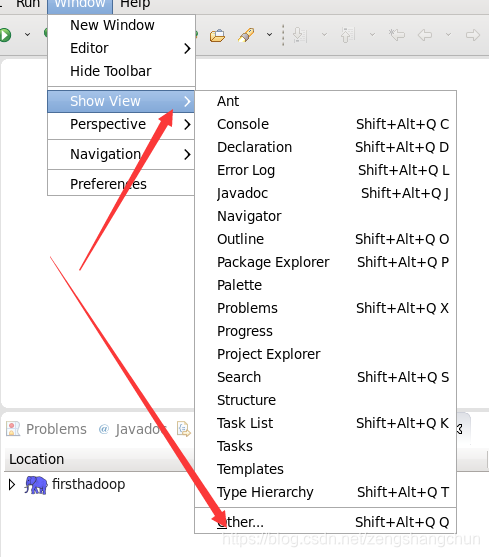
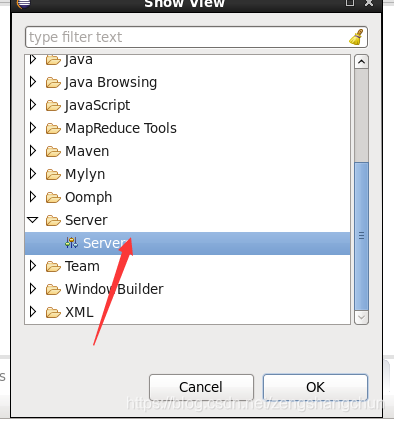
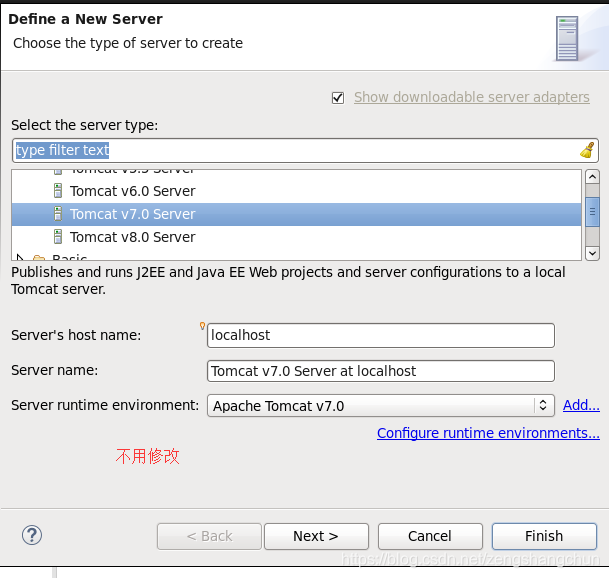
7.3,eclipse新建web项目:
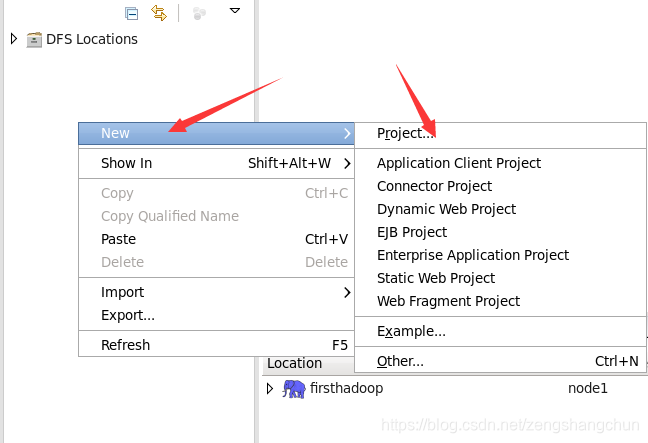
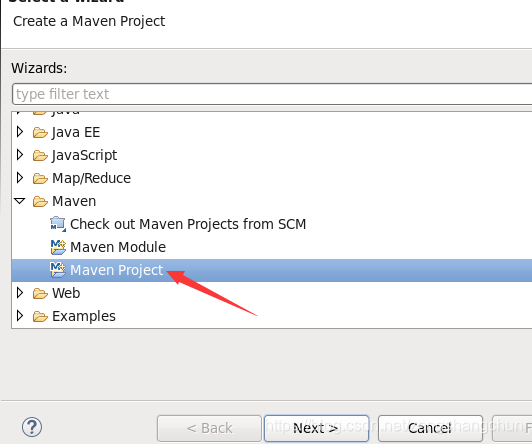
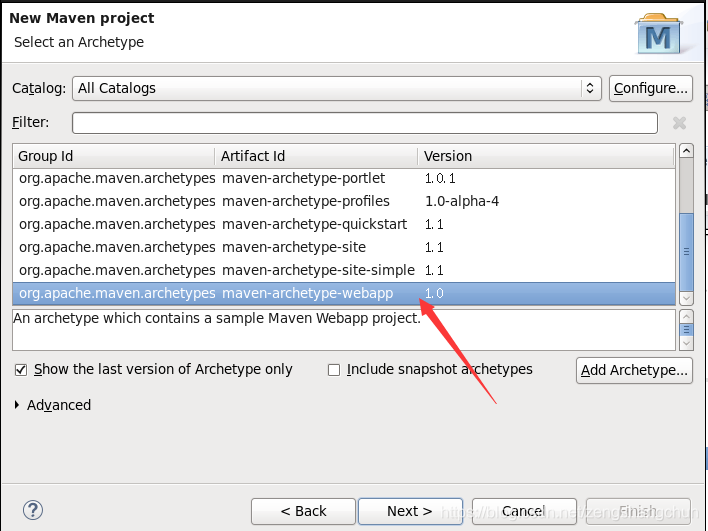
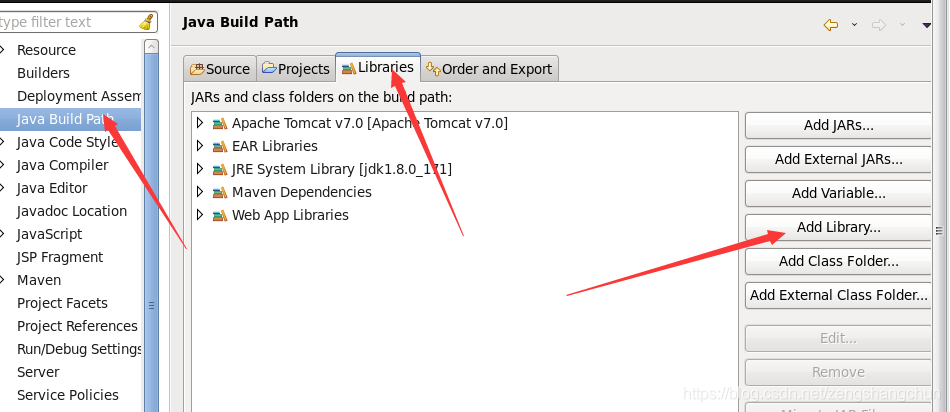
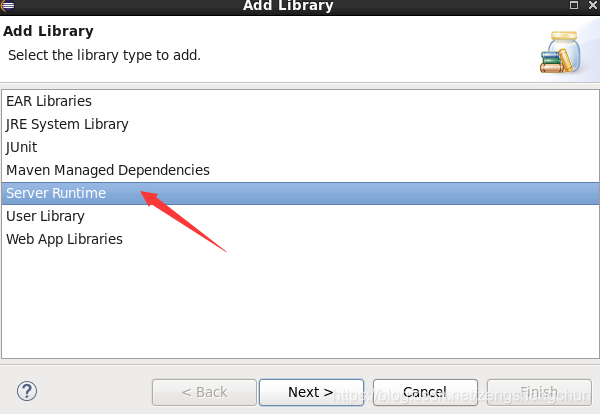
8,hdfs网盘应用
8.1,环境搭建
1)apache-maven
2)apache-tomcat
8.2,项目搭建
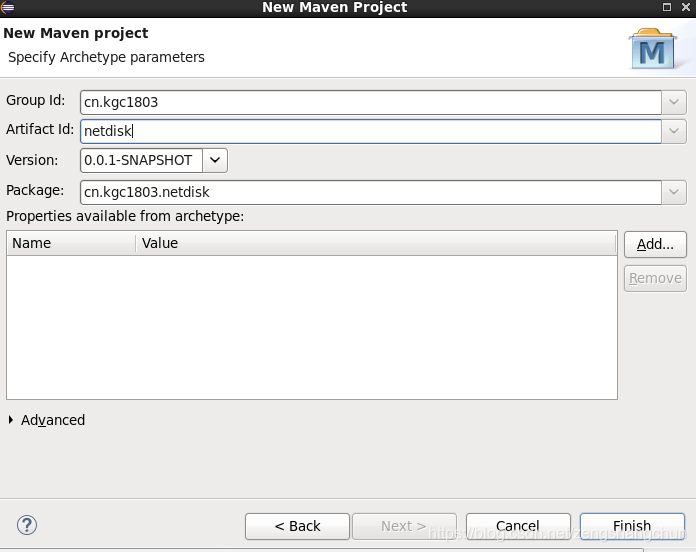
1)新建maven web项目
2)更改项目配置
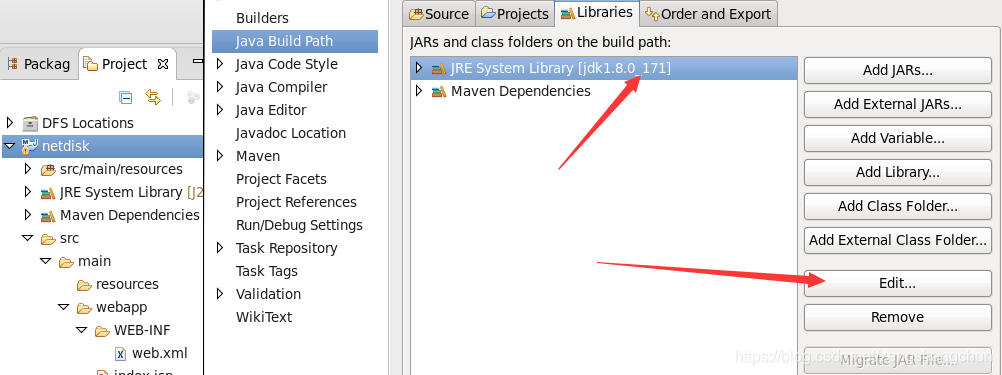
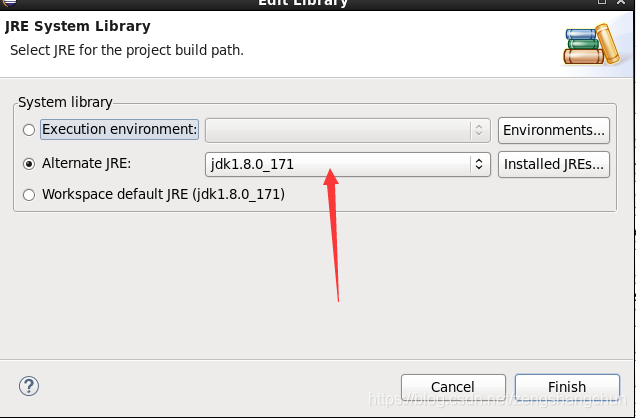
jdk:右键项目 build path
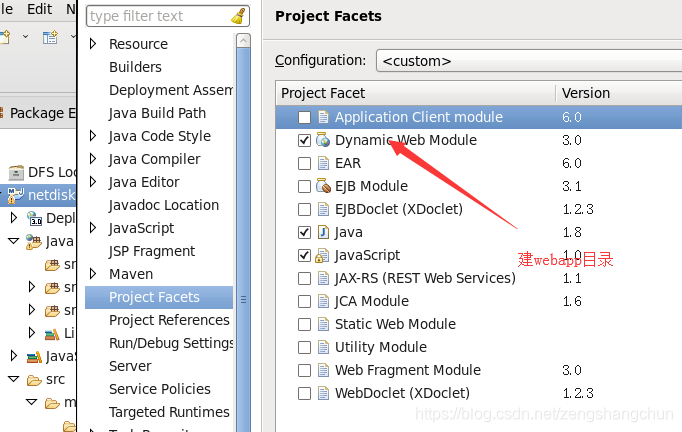
web facts:右键项目 properties -> 左侧 project facts
指定 src/main/webap 是web资源地址
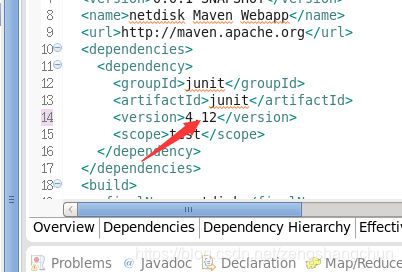
3)增加项目 jar 依赖
hadoop 公共包:
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.6.5</version>
</dependency>
hadoop hdfs 包:
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.6.5</version>
</dependency>
hadoop client 包:
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.6.5</version>
</dependency>
文件上传包:
commons-io:
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
<version>2.4</version>
</dependency>
commons-fileupload:
<dependency>
<groupId>commons-fileupload</groupId>
<artifactId>commons-fileupload</artifactId>
<version>1.2.1</version>
</dependency>
log4j jar
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.13</version>
</dependency>
4)从hadoop目录下复制core-site.xml ,log4j.properties到项目resources目录下
cp -rp /home/hduser/hadoop/etc/hadoop/core-site.xml /home/hduser/workspace/netdisk/src/main/resources/
cp -rp /home/hduser/hadoop/etc/hadoop/log4j.properties /home/hduser/workspace/netdisk/src/main/resources/

















 1707
1707

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









