




 本文详细介绍了如何从零开始手写一个简化版的webpack打包工具,涵盖了读取源文件、转换ES6+代码为ES5、解析依赖关系、合成bundle.js文件等关键步骤。
本文详细介绍了如何从零开始手写一个简化版的webpack打包工具,涵盖了读取源文件、转换ES6+代码为ES5、解析依赖关系、合成bundle.js文件等关键步骤。
我们知道,webpack是一个强大的打包工具,能通过引入各种插件依赖来对代码进行处理,今天就简单实现以下webpack里面的一部分核心内容
手写webpack
所需的babel npm 包
这里给一个package.json,可以先把相关的npm包安装下来
{
"name": "mywebpack",
"version": "1.0.0",
"description": "",
"main": "index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"author": "",
"license": "ISC",
"dependencies": {
"@babel/core": "^7.9.6",
"@babel/parser": "^7.9.6",
"@babel/preset-env": "^7.9.6",
"@babel/traverse": "^7.9.6"
}
}
初始化文件,编写要编译的文件
首先,新建一个文件,执行npm init来初始化
在根目录下新建src来存放要编译的文件
我们知道,ES module的语法是不能直接被浏览器执行的,那么我们这里就来编译一下ES module的语法,在src文件夹下新建文件如下,然后写入相应代码
// index.js
import { text } from './text.js'
console.log(`text:${text}`)
// text.js
export const text = 'text'
这道代码其实就是打印一个text而已,这里我还用了模板字符串,虽然浏览器大多支持了,但在babel编译后,也会变为ES5的代码
那么,接下来我们就真正地来做webpack的功能代码编写了,我们先在根目录下创建一个文件来编写webpack的功能代码
获取entry入口文件
首先,我们当然要获取到入口文件,入口文件的获取,有用过nodejs的同学应该都知道,我们可以直接通过fs模块来获取到src文件夹下的文件
通常用到的读取文件的fs模块的API有两个,readFile和readFileSync,这两个的区别在于第一个是通过读取完毕调用回调函数来实现文件读取的异步操作,但这样可能会带来像回调地狱的问题,所以我一般采用readFileSync,所以这里编写函数如下,我们可以打印内容看看
const fs = require('fs')
// 读取文件的函数
function readSrcFile(fileName) {
// 文件内容 格式为'utf-8',不设置的话会得到二进制内容
const fileContent = fs.readFileSync(fileName, 'utf-8')
console.log('fileContent: ', fileContent);
}
readSrcFile('./src/index.js')
在命令行中执行my_webpack.js文件,使用node命令即可

可以看到,打印出了index.js的内容
所以到这一步,读取文件就完成了,其实也就是调用个API的事
将读取到的内容转译成AST
那么既然说到了转译,就肯定要用上我们的核心内容babel了,这里我们需要先装一下相应的npm包@babel/parser
cnpm i @babel/parser
实际上引入这个包后,这个操作也就是一个调用API的过程而已
这里我们调用@babel/parser的parse方法来进行转译,这里要注意的是,我们要传入一些相应的参数,告知babel我们当前用的是模块化的代码,这个方法第一个参数是要转译的内容,第二个参数是一个对象,对象里配置了我们的一些转译设置,详情看babel的文档
那么,代码如下
const fs = require('fs')
const parser = require('@babel/parser')
// 读取文件的函数
function readSrcFile(fileName) {
// 文件内容
const fileContent = fs.readFileSync(fileName, 'utf-8')
const ast = parser.parse(fileContent, {
sourceType: 'module'
})
console.log('ast: ', ast);
}
readSrcFile('./src/index.js')
在执行一次my_webpack.js文件,结果就可以看到对应的ast树了
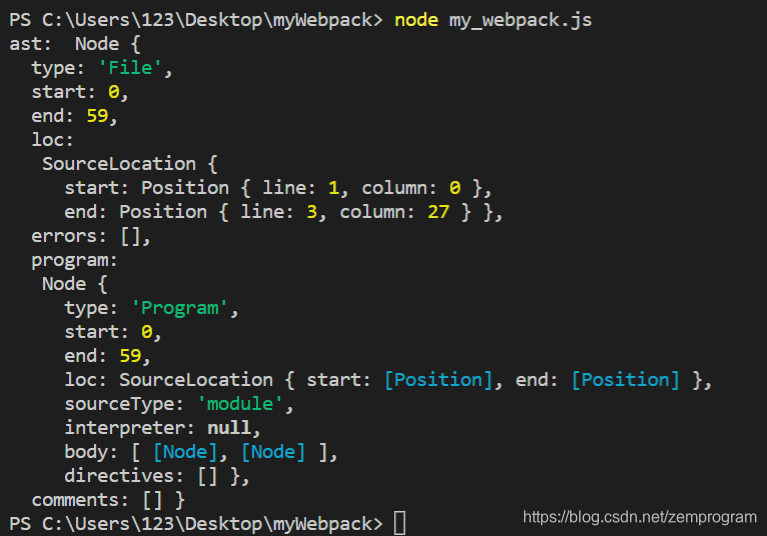
怎么知道这就是对应的ast树呢,我们可以上这个地址去看看https://astexplorer.net/
将我们index.js的代码复制到这个网站上
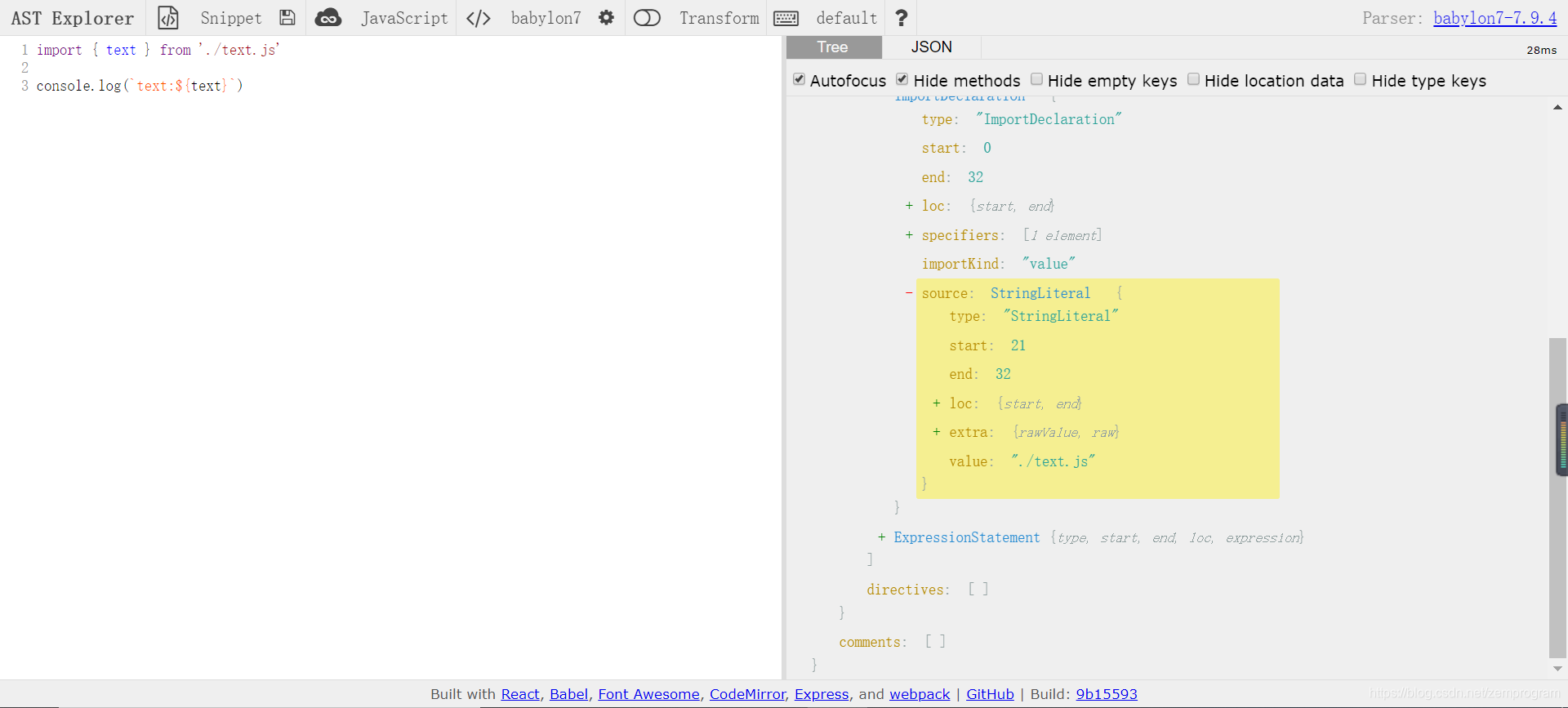
可以看到对应的ast树内容是符合的
找到依赖文件
既然我们已经得到了我们的入口文件idnex.js的ast,我们要知道的是,webpack实际上也只是通过你的入口文件,然后来找到入口文件依赖的其他文件,对这些依赖的文件也进行一个编译打包处理,所以在这一步,我们要先找到入口文件依赖的文件,然后再去找到依赖的这些文件所依赖的文件。
首先把babel依赖安装下来
npm i @babel/traverse
然后我们去先看看ast的结构里面,哪里是我们要引入的依赖
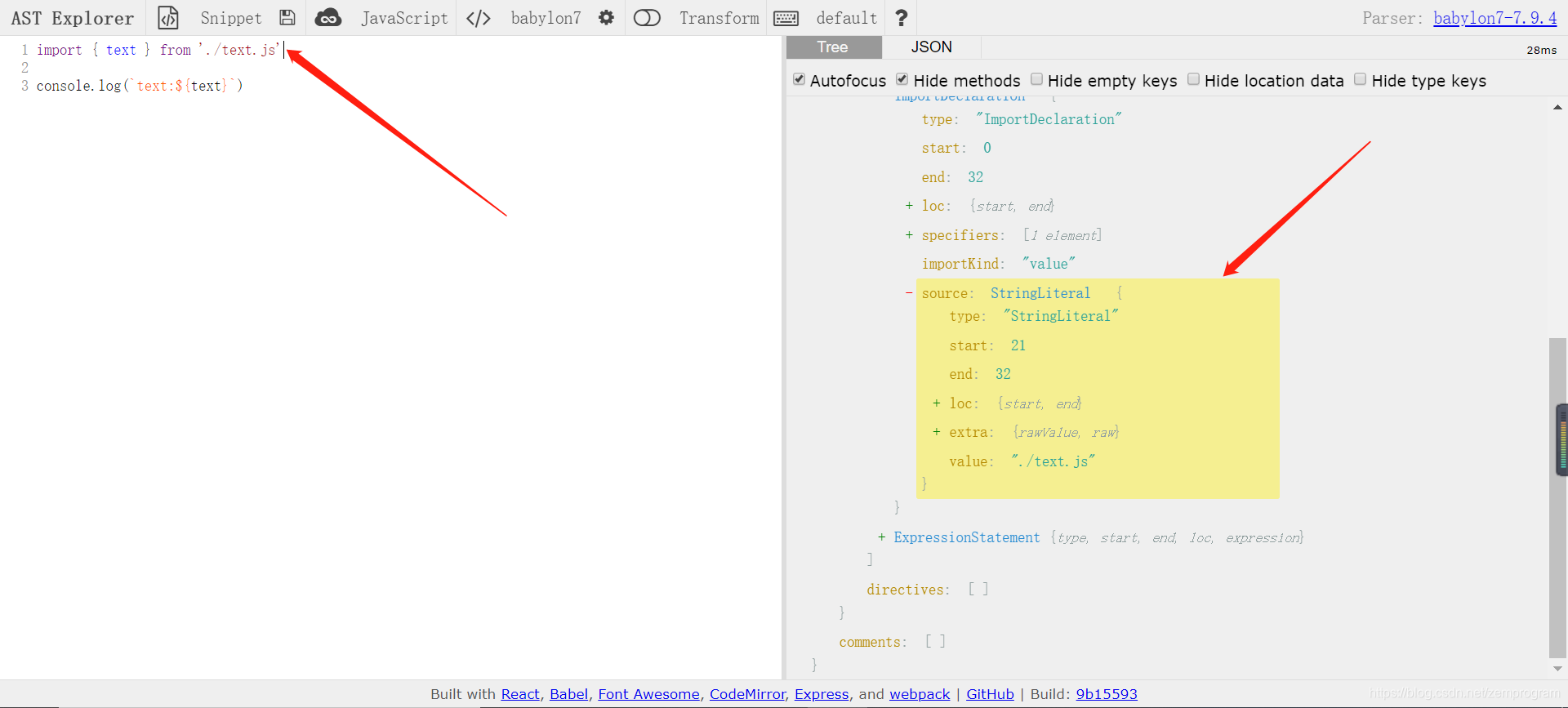
可以看到StringLiteral就是我们所要依赖的文件,但StringLiteral在ast中并不只是出现在import语句的引入,所以我们要去先获取它的上层ImportDeclaration,那么,开始写代码
const fs = require('fs')
const parser = require('@babel/parser')
const traverse = require('@babel/traverse').default
// 读取文件的函数
function readSrcFile(fileName) {
// 文件内容
const fileContent = fs.readFileSync(fileName, 'utf-8')
const ast = parser.parse(fileContent, {
sourceType: 'module'
})
// 找出依赖文件
// 传入参数,第一个为要解析的ast树,第二个为一个对象,每个属性对应一个钩子,可以让我们对ast里面对应的节点进行操作
traverse(ast, {
ImportDeclaration: (path) => {
console.log('path: ', path);
}
})
}
readSrcFile('./src/index.js')
这里我们先看看打印出来是什么,可以看到下图
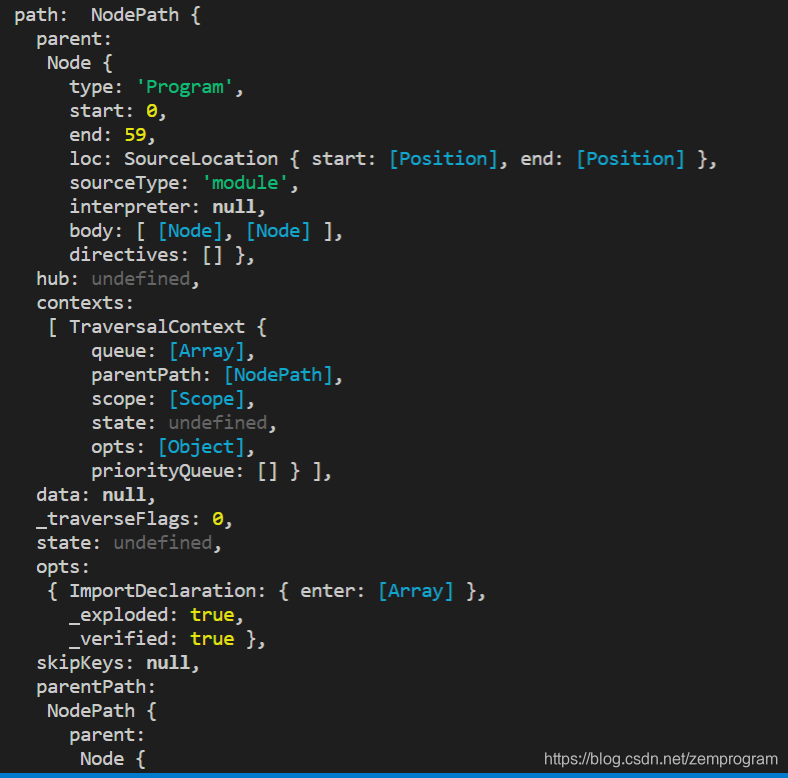
最终打印出来的就是这个节点在整颗ast树里面的信息,包括其父节点,本身节点信息,还有上下文等,那么因为我们要获取的是这个节点里面的StringLiteral,所以要关注节点本身,也就是node(输出太长所以我没法把整个输出截图出来)
就是下图
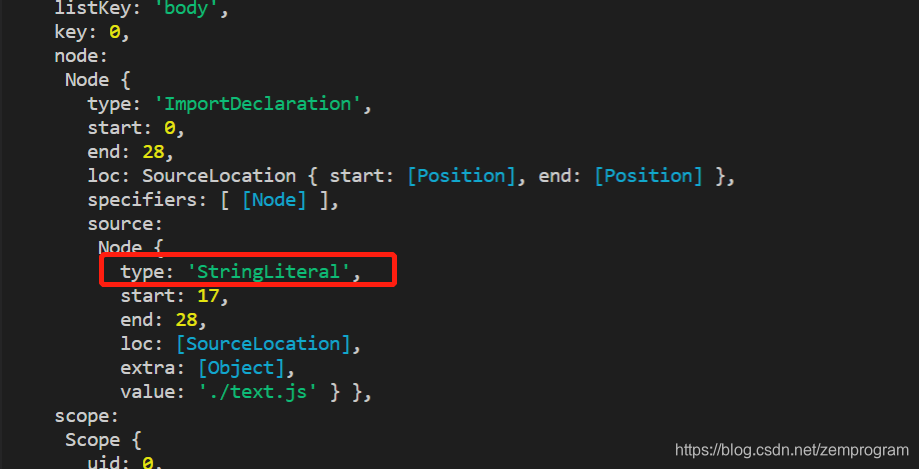
那么,我们通过解构赋值,来直接得到这个node,然后打印出相关内容
const fs = require('fs')
const parser = require('@babel/parser')
const traverse = require('@babel/traverse').default
// 读取文件的函数
function readSrcFile(fileName) {
// 文件内容
const fileContent = fs.readFileSync(fileName, 'utf-8')
const ast = parser.parse(fileContent, {
sourceType: 'module'
})
// 找出依赖文件
// 传入参数,第一个为要解析的ast树,第二个为一个对象,每个属性对应一个钩子,可以让我们对ast里面对应的节点进行操作
traverse(ast, {
ImportDeclaration: ({ node }) => {
console.log('value: ', node.source.value);
}
})
}
readSrcFile('./src/index.js')
执行文件可以看到,打印出了我们要的内容

但是实际上,我们的入口文件依赖的不只有一个文件,所以我们要把这些依赖的文件,放在一个数组里存储起来
const fs = require('fs')
const parser = require('@babel/parser')
const traverse = require('@babel/traverse').default
// 读取文件的函数
function readSrcFile(fileName) {
// 文件内容
const fileContent = fs.readFileSync(fileName, 'utf-8')
const ast = parser.parse(fileContent, {
sourceType: 'module'
})
// 找出依赖文件
// 声明存储依赖文件的数组
const dependences = []
// 传入参数,第一个为要解析的ast树,第二个为一个对象,每个属性对应一个钩子,可以让我们对ast里面对应的节点进行操作
traverse(ast, {
ImportDeclaration: ({ node }) => {
dependences.push(node.source.value)
}
})
console.log('dependences: ', dependences)
}
readSrcFile('./src/index.js')
然后我们给测试文件添加依赖,虽然这里不会检查是否真的有可以依赖的文件,但为了后面的测试全面,还是在src里面增加一个文件好了
// text1.js
export const text1 = 'text1'
// text2.js
export const text2 = 'text2'
// index.js
import { text1 } from './text1.js'
import { text2 } from './text2.js'
console.log(`text1:${text1} text2:${text2}`)
然后执行文件,可以看到打印出依赖的两个文件的路径了

ES6+代码转为ES5
既然找到了依赖文件,那我们就可以来将当前代码转为ES5代码了,然后后面再通过循环去执行这个过程,找到更深层次的依赖文件,来实现所有依赖文件的打包编译
那么,我们就先做好这一步
首先,还是要先安装依赖包
npm i @babel/core @babel/preset-env
然后,对ast树进行一个转译
const fs = require('fs')
const parser = require('@babel/parser')
const traverse = require('@babel/traverse').default
const babel = require('@babel/core')
// 读取文件的函数
function readSrcFile(fileName) {
// 文件内容
const fileContent = fs.readFileSync(fileName, 'utf-8')
const ast = parser.parse(fileContent, {
sourceType: 'module'
})
// 找出依赖文件
// 声明存储依赖文件的数组
const dependences = []
// 传入参数,第一个为要解析的ast树,第二个为一个对象,每个属性对应一个钩子,可以让我们对ast里面对应的节点进行操作
traverse(ast, {
ImportDeclaration: ({ node }) => {
dependences.push(node.source.value)
}
})
// 从ast转换为ES5代码
const { code } = babel.transformFromAstSync(ast, null, {
presets: ['@babel/preset-env']
})
console.log('code: ', code)
}
readSrcFile('./src/index.js')
这里为什么要用解构赋值,因为这个方法实际上返回有一个对象,这个对象的code属性才是最后编译好的ES5代码,大家也可以打印出来看看,这里我就不增加多余篇幅了
那么上面的内容执行出来就是
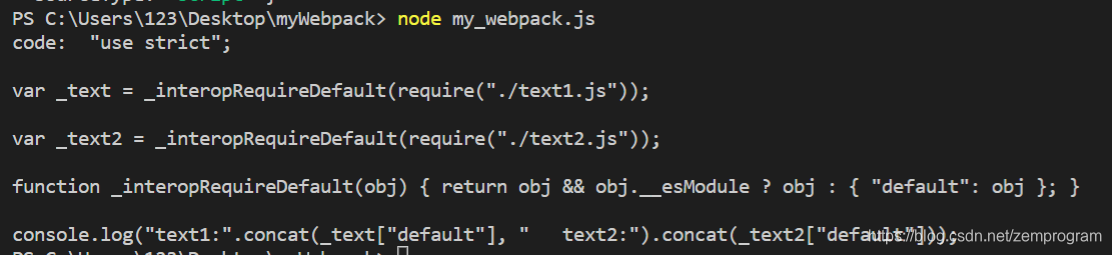
可以看到,代码被成功转换了,import被转换成了require,而打印得模板字符串,也通过ES5得语法,通过concat方法来实现了相同的打印
循环分析
首先我们要将上面的编译内容return出来,然后后面可以进行重复的调用,为了明确是哪一次的解析,给返回加上一个id
const fs = require('fs')
const parser = require('@babel/parser')
const traverse = require('@babel/traverse').default
const babel = require('@babel/core')
let ID = 0
// 读取文件的函数
function readSrcFile(fileName) {
// 文件内容
const fileContent = fs.readFileSync(fileName, 'utf-8');
const ast = parser.parse(fileContent, {
sourceType: 'module'
})
// 找出依赖文件
// 声明存储依赖文件的数组
const dependences = [];
// 传入参数,第一个为要解析的ast树,第二个为一个对象,每个属性对应一个钩子,可以让我们对ast里面对应的节点进行操作
traverse(ast, {
ImportDeclaration: ({ node }) => {
dependences.push(node.source.value);
}
})
// 从ast转换为ES5代码
const { code } = babel.transformFromAstSync(ast, null, {
presets: ['@babel/preset-env']
})
let id = ID++;
return {
id,
fileName,
dependences,
code
}
}
readSrcFile('./src/index.js')
然后,我们需要去写一个方法,在这个方法里,我们读取入口文件,然后将文件使用上面的readSrcFile方法处理,判断返回的对象的dependences是否还有成员,即是否还有依赖的文件,如果有,就继续对这些文件使用readSrcFile处理,如果没有,就停下来,这实际上就是一个深度遍历,使用递归可以实现深度遍历,下面我要用的是使用队列来实现广度遍历
这里我们再处理一下我们的src测试文件夹,在text1.js中引入一个text3.js,来达到一个嵌套依赖的结构
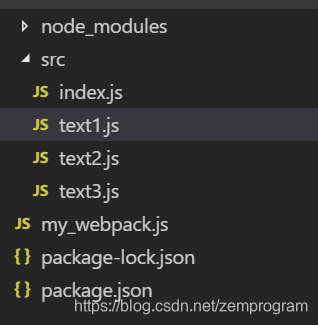
// text1.js
import { text3 } from './text3.js'
export const text1 = `text1 ${text3}`
// text3.js
export const text3 = 'text3'
为了能更好地处理路径,所以在这里引入了path这个npm包,然后下面就直接show代码了,广度遍历也没什么好说的了,就直接利用队列,在找到新的依赖就从队列末端压入
const fs = require('fs')
const path = require('path')
const parser = require('@babel/parser')
const traverse = require('@babel/traverse').default
const babel = require('@babel/core')
let ID = 0
// 读取文件的函数
function readSrcFile(fileName) {
// ...
}
// 从文件入口对依赖文件处理
function handleFiles(fileName) {
// 获取入口文件处理后的对象
const fileObj = readSrcFile(fileName);
const list = [fileObj];
for (const asset of list) {
// 使用path获取asset.fileName文件所在的文件夹
const dirname = path.dirname(asset.fileName);
// 为了在后面能通过id找到模块,设置一个map
asset.mapping = {};
// 遍历队列
asset.dependences.forEach(relativePath => {
// 将上面得到的文件夹路径和相对路径拼接起来得到绝对路径
const absolutePath = path.join(dirname, relativePath);
// 将依赖的文件使用readSrcFile处理
const child = readSrcFile(absolutePath);
// 将对应模块的id传入到mapping中
asset.mapping[relativePath] = child.id;
// 将依赖的文件添加到队列尾部
list.push(child);
});
}
return list;
}
const graph = handleFiles('./src/index.js');
console.log('graph: ', graph);
执行文件,可以看到下图
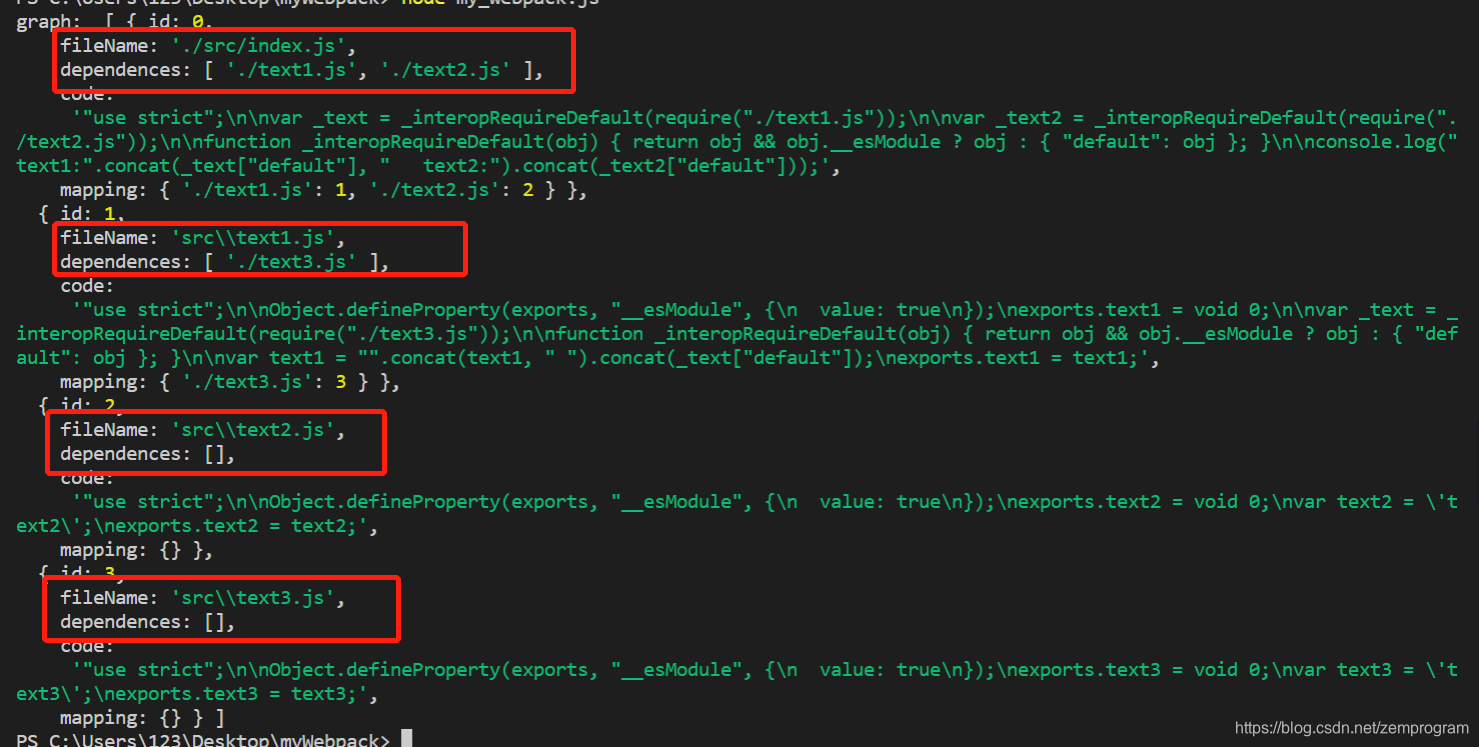
几个嵌套依赖文件都打印出来了,而且其中成员的code属性,就是各个文件转译为ES5代码的内容。
合成到bundle.js文件中
那么,既然我们已经得到所有文件的转译内容了,接下来就是将这些文件合并到bundle.js文件里了,这里再写一个方法bundle
这里使用模板字符串来做处理,通过模板字符串的形式,将我们得到的code直接存放在最好返回的内容中,同时,为了能通过id来直接得到对应的文件/模块,所以这里使用id来做为key
我们可以先看看模板内容是什么
const fs = require('fs')
const path = require('path')
const parser = require('@babel/parser')
const traverse = require('@babel/traverse').default
const babel = require('@babel/core')
let ID = 0
// 读取文件的函数
function readSrcFile(fileName) {
// 文件内容
const fileContent = fs.readFileSync(fileName, 'utf-8');
const ast = parser.parse(fileContent, {
sourceType: 'module'
})
// 找出依赖文件
// 声明存储依赖文件的数组
const dependences = [];
// 传入参数,第一个为要解析的ast树,第二个为一个对象,每个属性对应一个钩子,可以让我们对ast里面对应的节点进行操作
traverse(ast, {
ImportDeclaration: ({ node }) => {
dependences.push(node.source.value);
}
})
// 从ast转换为ES5代码
const { code } = babel.transformFromAstSync(ast, null, {
presets: ['@babel/preset-env']
})
let id = ID++;
return {
id,
fileName,
dependences,
code
}
}
// 从文件入口对依赖文件处理
function handleFiles(fileName) {
// 获取入口文件处理后的对象
const fileObj = readSrcFile(fileName);
const list = [fileObj];
for (const asset of list) {
// 使用path获取asset.fileName文件所在的文件夹
const dirname = path.dirname(asset.fileName);
// 为了在后面能通过id找到模块,设置一个map
asset.mapping = {};
// 遍历队列
asset.dependences.forEach(relativePath => {
// 将上面得到的文件夹路径和相对路径拼接起来得到绝对路径
const absolutePath = path.join(dirname, relativePath);
// 将依赖的文件使用readSrcFile处理
const child = readSrcFile(absolutePath);
// 将对应模块的id传入到mapping中
asset.mapping[relativePath] = child.id;
// 将依赖的文件添加到队列尾部
list.push(child);
});
}
return list;
}
// 构建最终的bundle.js文件的内容
function bundle(graph) {
let modules = ''
graph.forEach(mod => {
modules += `
${mod.id}:[
function (req,mod,exp){
${mod.code}
},
${JSON.stringify(mod.mapping)}
],
`
})
const result = `
(function(modules){
})({${modules}})
`;
return result;
}
const graph = handleFiles('./src/index.js');
const result = bundle(graph)
console.log('result: ', result);
执行文件
看到
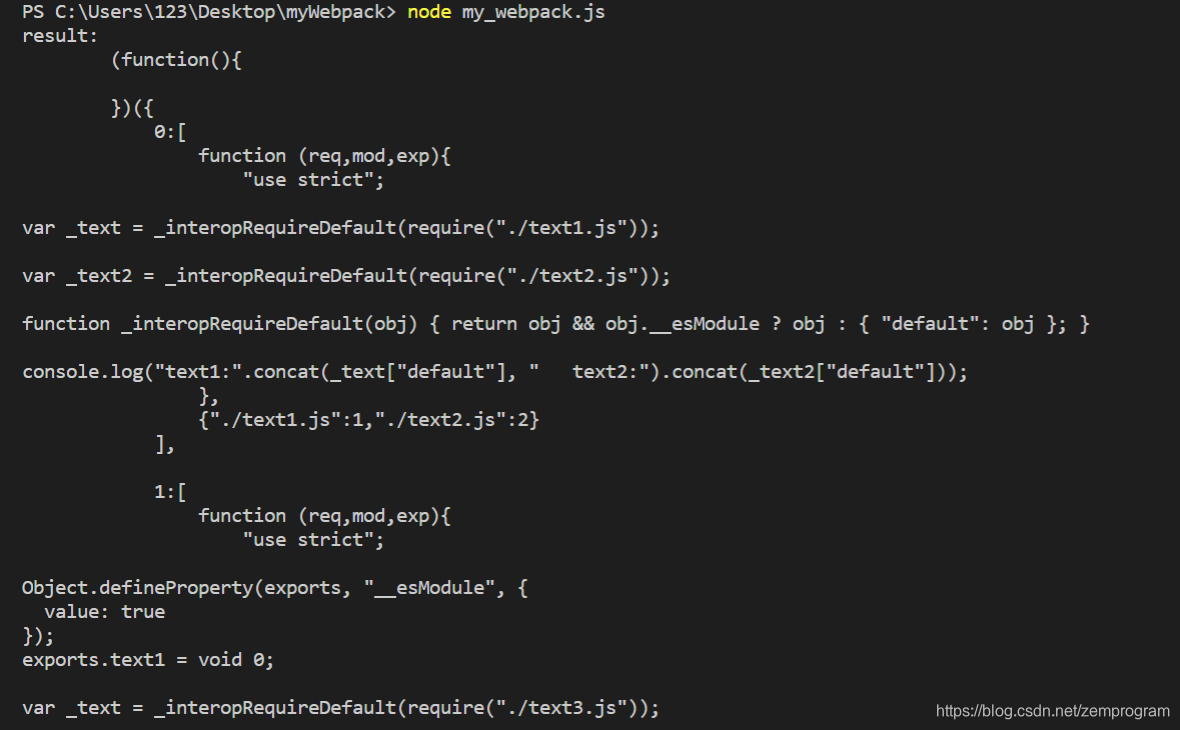
传给IIFE的modules内容如上,那么接下来,我们就要对这个modules进行处理,这里贴一下bundle函数的修改
// 构建最终的bundle.js文件的内容
function bundle(graph) {
let modules = ''
graph.forEach(mod => {
modules += `
${mod.id}:[
function (require,module,exports){
${mod.code}
},
${JSON.stringify(mod.mapping)}
],
`
})
// 在内部构建require来通过id获取到模块内容
// 而在require函数内部,由于fn里面的内容是通过相对路径来进行文件/模块获取的
// 所以还需要在里面写入另一个函数localRequire来对路径做处理
// 因为以我们上面的形式处理,id是从0开始的,require(0)就是从入口文件执行
const result = `
(function(modules){
function require(id){
const [fn,mapping] = modules[id];
function localRequire(relativePath){
return require(mapping[relativePath]);
}
const module = {
exports:{}
}
fn(localRequire , module , module.exports);
return module.exports;
}
require(0)
})({${modules}})
`;
return result;
}
再次执行文件,将打印出来的内容,复制到浏览器的控制台运行,如果运行成功,则说明编译成功了

看到这里,正确地输出了文本内容
将内容写到dist文件夹下的bundle.js文件
我们在根目录下创建一个dist文件夹,然后在my_webpack.js文件下写下一句
fs.writeFileSync('./dist/bundle.js', result)
执行文件
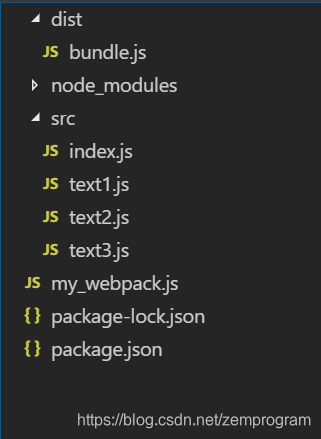
可以看到文件夹下面多了一个bundle.js文件,这就是我们生成的代码
完整的my_webpack.js文件如下
const fs = require('fs')
const path = require('path')
const parser = require('@babel/parser')
const traverse = require('@babel/traverse').default
const babel = require('@babel/core')
let ID = 0
// 读取文件的函数
function readSrcFile(fileName) {
// 文件内容
const fileContent = fs.readFileSync(fileName, 'utf-8');
const ast = parser.parse(fileContent, {
sourceType: 'module'
})
// 找出依赖文件
// 声明存储依赖文件的数组
const dependences = [];
// 传入参数,第一个为要解析的ast树,第二个为一个对象,每个属性对应一个钩子,可以让我们对ast里面对应的节点进行操作
traverse(ast, {
ImportDeclaration: ({ node }) => {
dependences.push(node.source.value);
}
})
// 从ast转换为ES5代码
const { code } = babel.transformFromAstSync(ast, null, {
presets: ['@babel/preset-env']
})
let id = ID++;
return {
id,
fileName,
dependences,
code
}
}
// 从文件入口对依赖文件处理
function handleFiles(fileName) {
// 获取入口文件处理后的对象
const fileObj = readSrcFile(fileName);
const list = [fileObj];
for (const asset of list) {
// 使用path获取asset.fileName文件所在的文件夹
const dirname = path.dirname(asset.fileName);
// 为了在后面能通过id找到模块,设置一个map
asset.mapping = {};
// 遍历队列
asset.dependences.forEach(relativePath => {
// 将上面得到的文件夹路径和相对路径拼接起来得到绝对路径
const absolutePath = path.join(dirname, relativePath);
// 将依赖的文件使用readSrcFile处理
const child = readSrcFile(absolutePath);
// 将对应模块的id传入到mapping中
asset.mapping[relativePath] = child.id;
// 将依赖的文件添加到队列尾部
list.push(child);
});
}
return list;
}
// 构建最终的bundle.js文件的内容
function bundle(graph) {
let modules = ''
graph.forEach(mod => {
modules += `
${mod.id}:[
function (require,module,exports){
${mod.code}
},
${JSON.stringify(mod.mapping)}
],
`
})
// 在内部构建require来通过id获取到模块内容
// 而在require函数内部,由于fn里面的内容是通过相对路径来进行文件/模块获取的
// 所以还需要在里面写入另一个函数localRequire来对路径做处理
// 因为以我们上面的形式处理,id是从0开始的,require(0)就是从入口文件执行
const result = `
(function(modules){
function require(id){
const [fn,mapping] = modules[id];
function localRequire(relativePath){
return require(mapping[relativePath]);
}
const module = {
exports:{}
}
fn(localRequire , module , module.exports);
return module.exports;
}
require(0)
})({${modules}})
`;
return result;
}
const graph = handleFiles('./src/index.js');
const result = bundle(graph)
fs.writeFileSync('./dist/bundle.js', result)
console.log('result: ', result);

















 1749
1749

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









