



ollama
下载
ollama是一个开源的 LLM(大型语言模型)服务工具,用于简化在本地运行大语言模型,降低使用大语言模型的门槛,使得大模型的开发者、研究人员和爱好者能够在本地环境快速实验、管理和部署最新大语言模型,包括如Llama 3、Phi 3、Mistral、Gemma等开源的大型语言模型。
Ollama目前支持以下大语言模型:https://ollama.com/library
下载地址:Ollama
安装完后可以看命令行是否安装成功

模型选择
搜索deepseek-r1
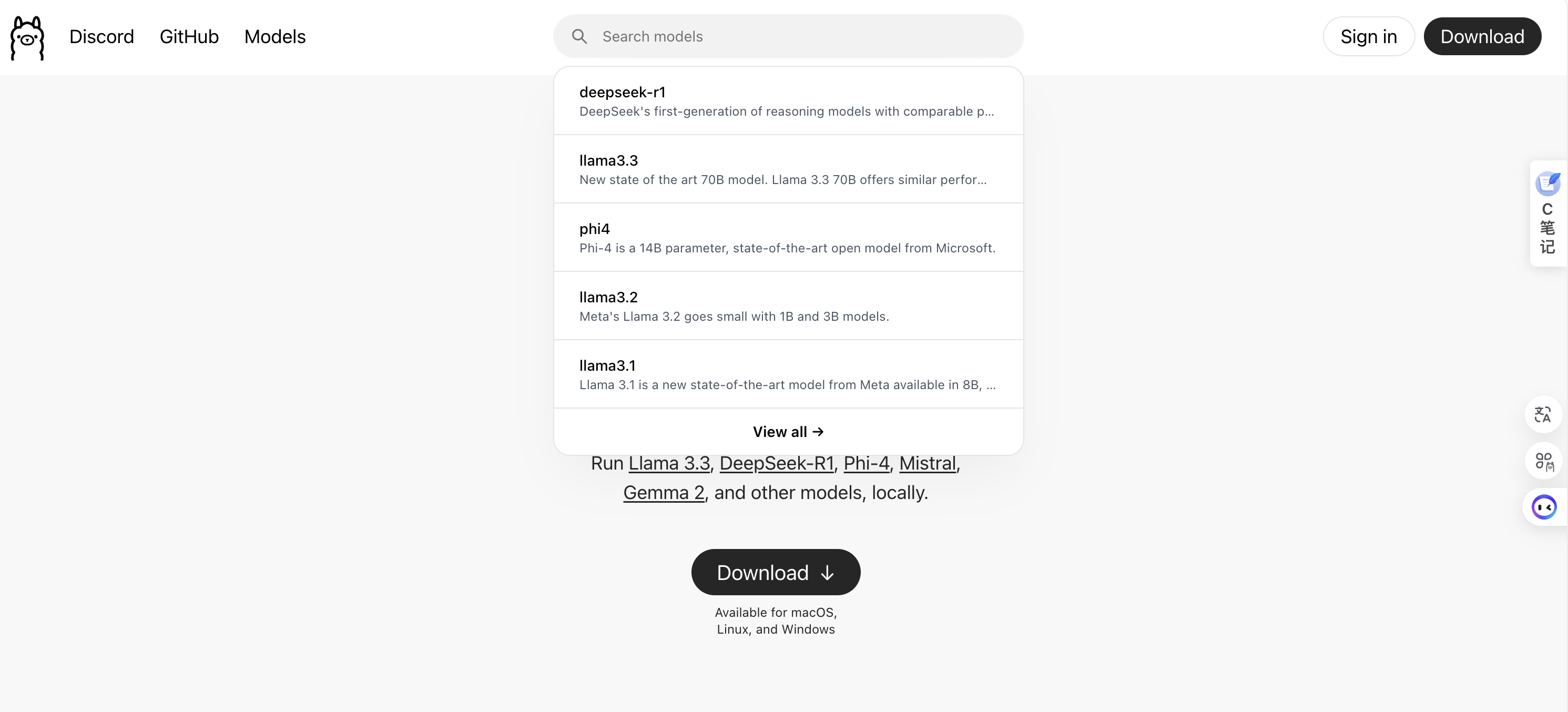
选择模型推理模式
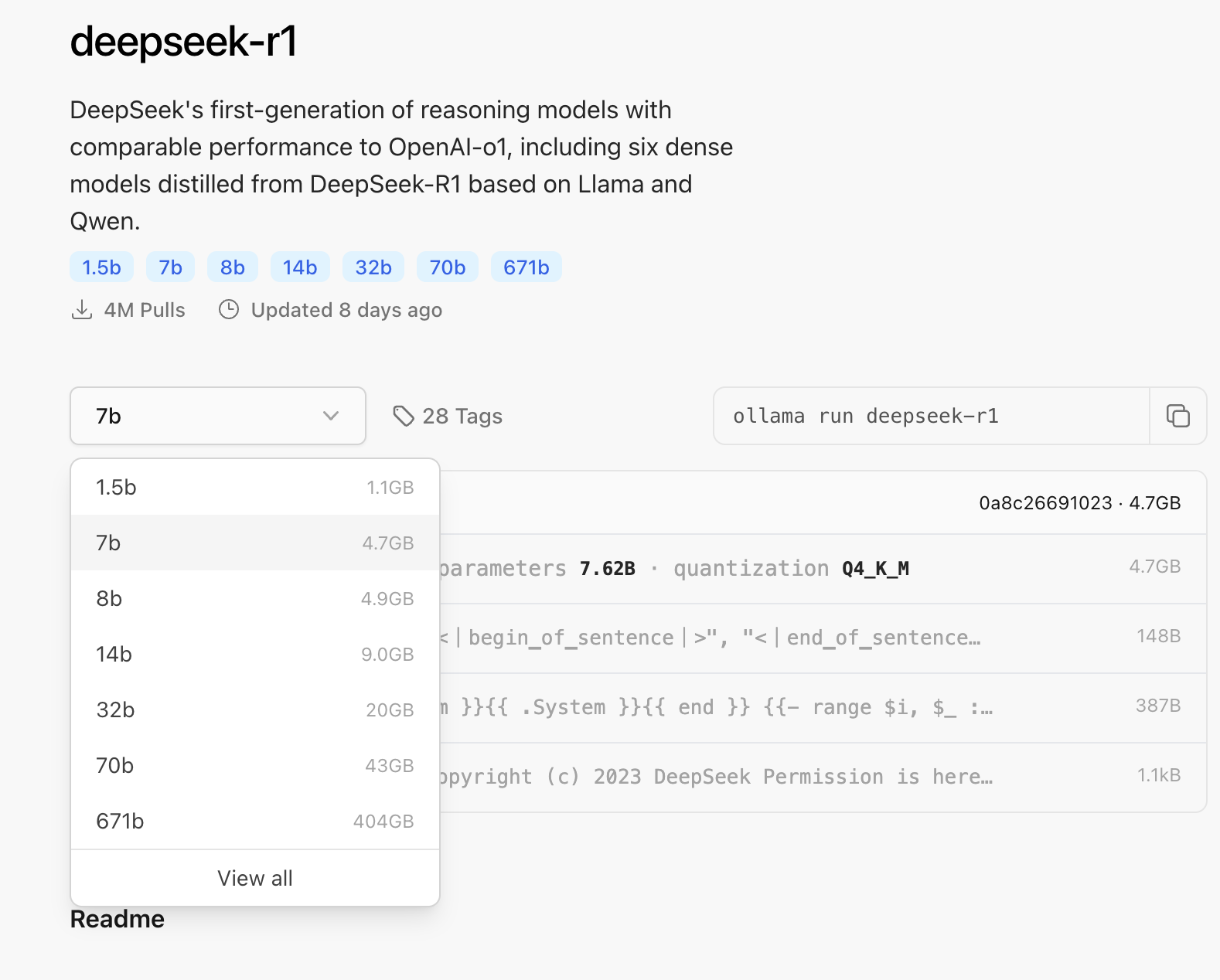
模型大小和显卡、内存资源表格
本机用的mac m4芯片 16+512配置,可以使8B模型流畅运行
然后选择适合本机的模型大小命令在终端运行。
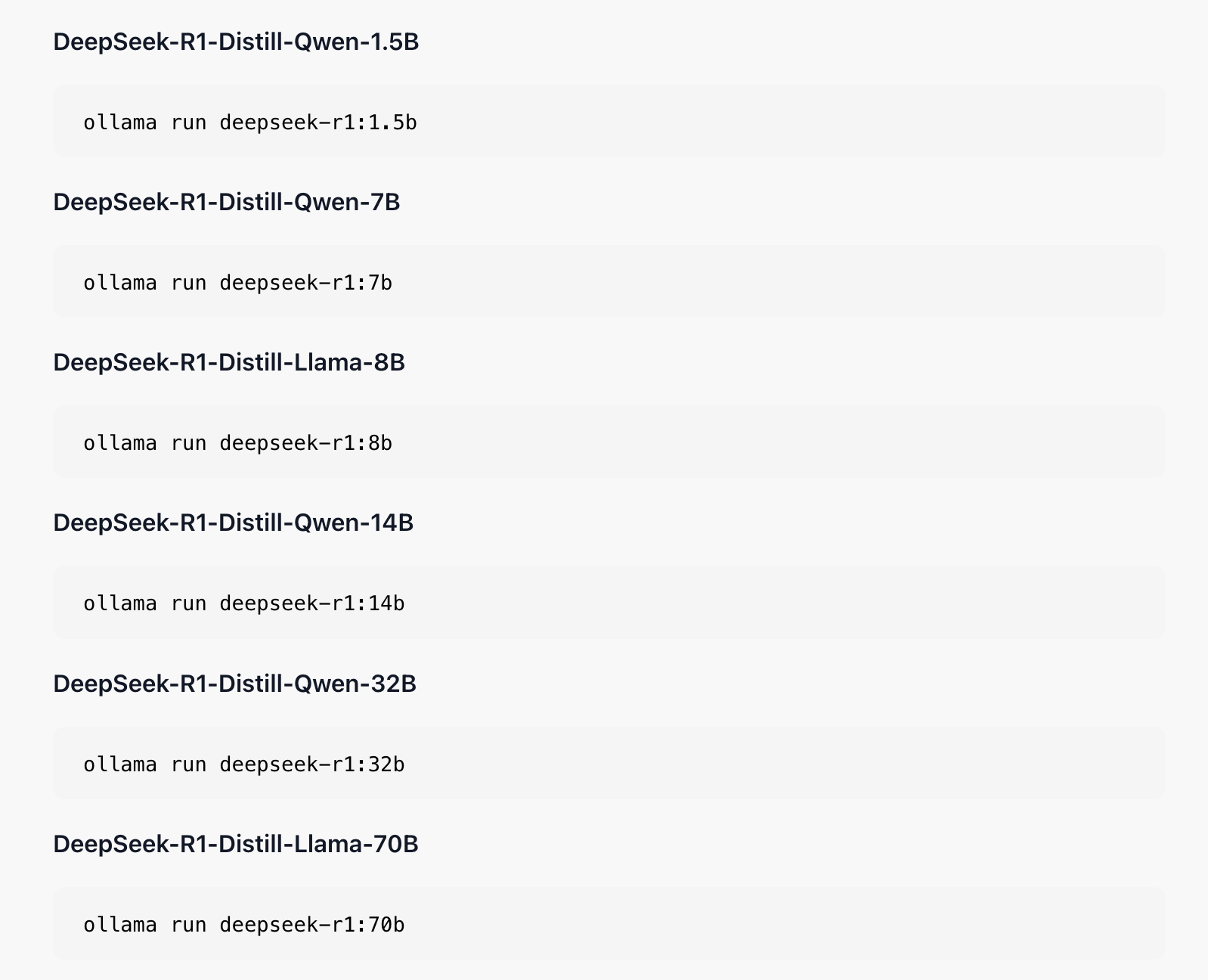
安装好后就可以使用模型了

输入/bye可退出命令行
chatbox
虽然终端可以直接运行,但是不方便。这里推荐chatbox
Chatbox AI 是一款 AI 客户端应用和智能助手,支持众多先进的 AI 模型和 API,可在 Windows、MacOS、Android、iOS、Linux 和网页版上使用。
安装地址:Chatbox AI官网:办公学习的AI好助手,全平台AI客户端,官方免费下载
也可以使用在线版本
点击设置
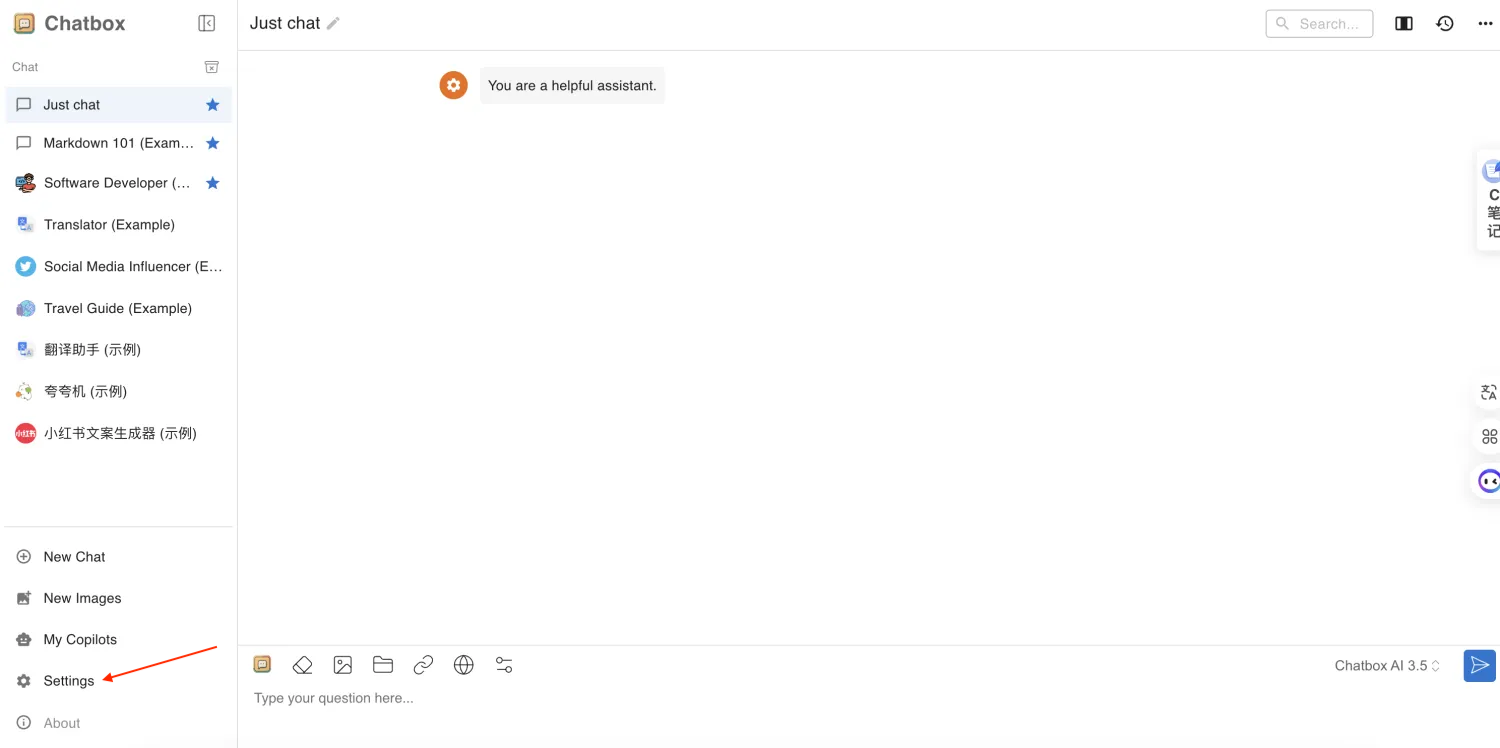
进行如下配置
开启新对话就可以直接使用了!
模型差异
这里就用豆包(在线)和deepSeek-r1 8b(本地)来做一个比较。
学术问题
勾股定理
豆包


deepSeek-r1




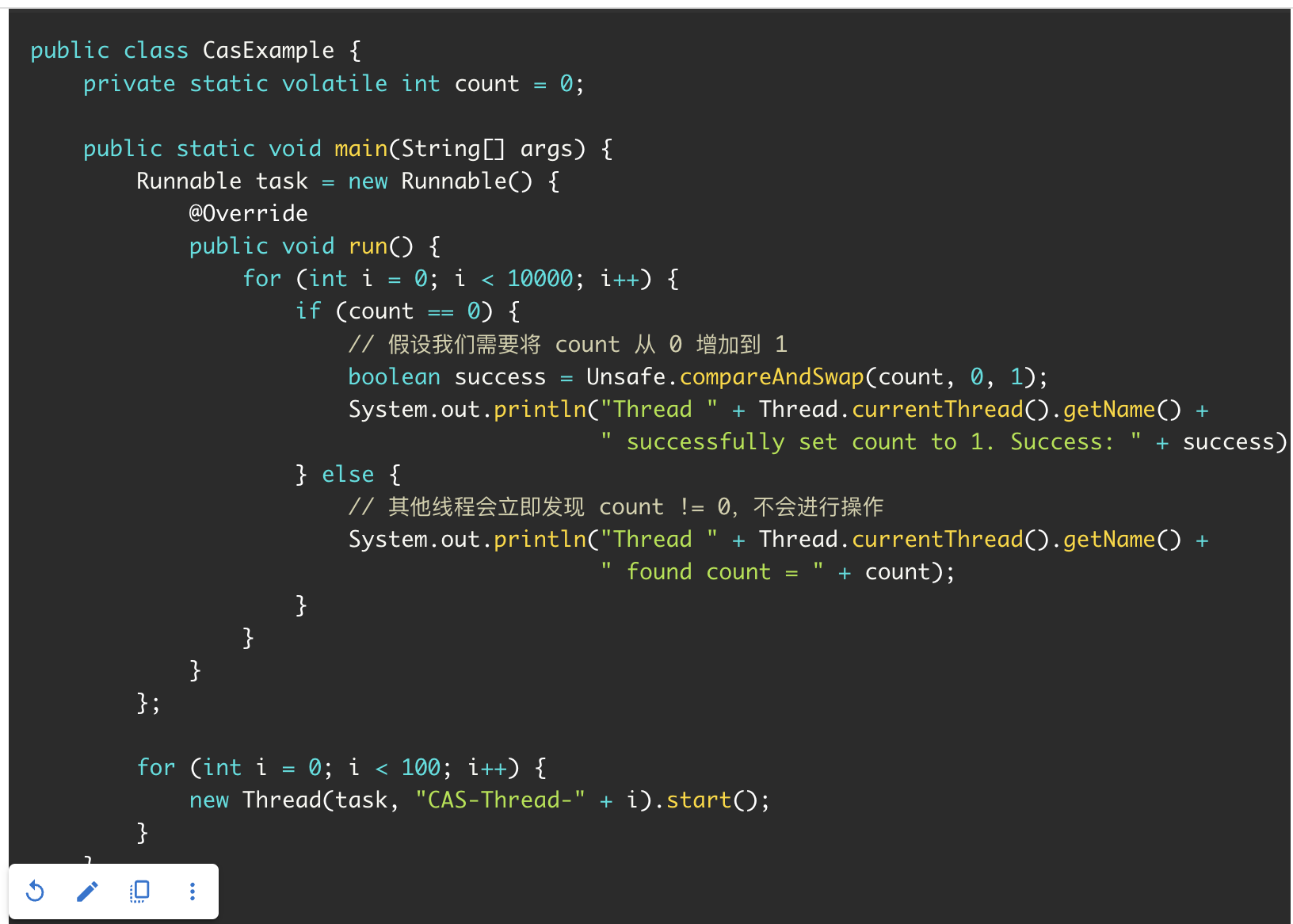
代码问题
CAS
豆包



deepSeek-r1




逻辑问题
喜欢装好人的王老汉被警察发现家里冰柜装满了好人,那他是不是好人
豆包
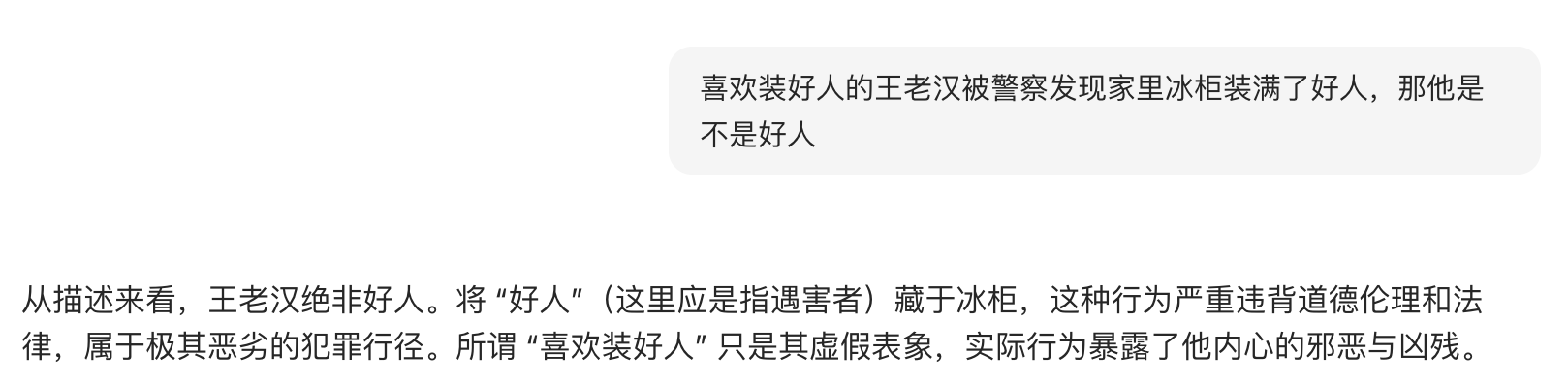
deepSeek-r1


差异
相比于线上给用户使用的豆包,本地部署的deepSeek-r1会把自己的思考过程给写出来,也就是它应该如何去回答用户提出的问题。
资源占用情况
本地使用deepSeek-r1 8b模型生成对话,后台占用资源情况。
内存
cpu


















 1921
1921

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











