




 本文深入解析Python中的生成器表达式、模块概念及应用、模块搜索路径、Python文件的双用途、软件开发规范以及模块循环导入问题的解决策略。
本文深入解析Python中的生成器表达式、模块概念及应用、模块搜索路径、Python文件的双用途、软件开发规范以及模块循环导入问题的解决策略。
一、生成器表达式
示范1:
#列表生成式
res = [i for i in range(10) if i > 5]
print(res) #[6, 7, 8, 9]
#生成器表达式用小括号包起来
g = (i for i in range(10) if i > 5)
print(g)
print(next(g))
print(next(g))
print(next(g))
print(next(g))
示范2:
with open('a.txt', mode='rt', encoding='utf-8') as f:
res = 0
for line in f:
res += len(line)
print(res)
#简洁写法
with open('a.txt', mode='rt', encoding='utf-8') as f:
res = sum(len(line) for line in f)
print(res)
二、模块
-
什么是模块:模块就是一系列功能的集合体
模块分为四个通用的类别:
- 使用python编写的.py文件
- 已被编译为共享库或DLL的C或C++扩展
- 把一系列模块组织到一起的文件夹(注:文件夹下有一个
_init_.py文件,该文件夹称之为包) - 使用C编写并链接到python解释器的内置模块
模块有三种来源:
- 内置模块
- 第三方模块
- 自定义模块
-
为何要用模块
- 使用内置的或者第三方的模块的好处是:拿来主义,极大提升开发效率
- 使用自定义的模块的好处是:将程序各部分组件共用的功能提取出放到一个模块里,其他的组件通过导入的方式使用该模块,该模块即自定义的模块,好处是可以减少代码冗余
-
如何用模块
第一种方式:import 模块名
首次导入模块会发生三件事
- 会产生一个模块的名称空间
- 执行spam.py文件的内容,将产生的名字丢到模块的名称空间里
- 在当前执行文件中拿到一个名字spam,该名字指向模块的名称空间
#之后的导入直接引用首次导入的成果
import spam
#使用
print(spam.money)
print(spam.read1)
spam.read1()
spam.read2()
#补充:可以把导入的模块起别名
import spam as sm
print(sm.money)
第二种方式:from 模块名 import 名字1,名字2
from spam import read1,read2
#不需要名字前缀直接使用
print(read1)
print(read2)
read1()
read2()
#from可以起别名但不是对导入的模块起别名,是对模块中的名字名字起别名
from spam import money as m
print(m)
#补充:如果模块的名字非常多可以使用*号
from spam import *
import总结:
优点:指名道姓地问某一个名称空间要名字,不会与当前执行文件名称空间中的名字冲突
缺点:引用模块中的名字必须加前缀(模块名.)使用不够简洁
from…import总结:
优点:引用模块中的名字不用加前缀(模块名.)使用更为简洁
缺点:容易与当前执行文件名称空间中的名字冲突
三、模块的搜索路径
查找模块路径的优先级
- 内存
- 内置模块
- sys.path(是以执行文件为准的)
import sys
print(sys.path) #打印当前环境变量
#如果要使用aaa文件夹下的模块可以使用append加入环境变量
import sys
sys.path.append(r'D:\zdc\day15\aaa')
#如果不使用import也可以使用from aaa文件加下的模块
from aaa import spam
print(spam.money)
四、如何区分python文件的两种用途
print(__name__)
当文件被当作执行文件执行时__name__的值为__main__
当文件被当作模块导入时__name__的值为模块名
#mmm.py
def f1():
print('f1')
def f2():
print('f2')
if __name__ == '__main__':
f1()
f2()
#run.py
import mmm
#运行run.py mmm.py不会被直接调用
五、软件开发规范
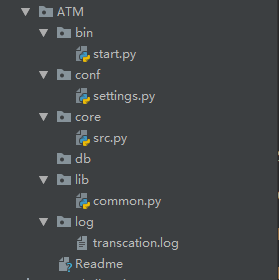
根目录:ATM
执行文件夹:bin
start.py:执行|启动文件
配置文件夹:conf
settings.py:配置文件
核心文件夹:core
src.py:核心代码
数据文件夹:db
存放数据文件
自定义文件夹:lib
common.py:公用模块
日志文件夹:log
transcation.log:日志文件
#=========================>start.py
import sys
import os
# 1. 应该把项目的根目录加到环境变量里
# 2. 应该把项目根目录所在绝对路径拿到,然后加到环境变量里
# sys.path.append(r'D:\脱产5期内容\day15\05 软件开发的目录规范part1\ATM')
BASE_DIR=os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
sys.path.append(BASE_DIR)
from core import src
src.run()
#=========================>settings.py
import os
BASE_DIR=os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
LOG_PATH=r'%s\log\transcation.log' %BASE_DIR
#=========================>src.py
from lib import common
def register():
print('注册。。。')
def login():
print('登陆。。。')
def shopping():
print('购物。。。')
def withdraw():
print('提现。。。')
# 调用日志功能
common.logger('egon提取了1亿')
func_dic={
'1':register,
'2':login,
'3':shopping,
'4':withdraw
}
def run():
while True:
print("""
0 退出
1 注册
2 登陆
3 购物
4 提现
""")
choice=input('请输入指令>>>: ').strip()
if choice == '0':break
if choice in func_dic:
func_dic[choice]()
else:
print('请重新输入指令。。。')
#=========================>common.py
import time
from conf import settings
def logger(msg):
with open(r'%s' %settings.LOG_PATH,mode='at',encoding='utf-8') as f:
f.write('%s %s\n' %(time.strftime('%Y-%m-%d %H:%M:%S'),msg))
#=========================>transcation.log
2018-12-04 12:43:47 egon提取了1亿
2018-12-04 12:44:02 egon提取了1亿
2018-12-04 12:47:10 egon提取了1亿
2018-12-04 12:50:34 egon提取了1亿
六、模块的循环导入问题
#run.py
import m1
#m1.py
print('正在导入m1')
from m2 import y
x = 'm1'
#m2.py
print('正在导入m2')
from m1 import x
y = 'm2'
#在运行run.py的时候会报错ImportError: cannot import name 'x'
#======================>解决办法1:
#m1.py
print('正在导入m1')
x = 'm1'
from m2 import y
#m2.py
print('正在导入m2')
y = 'm2'
from m1 import x
#run.py
import m1
#======================>解决方法2:
#m1.py
print('正在导入m1')
def func1():
from m2 import y,func2
print('来自m2的y',y)
func2()
x = 'm1'
#m2.py
print('正在导入m2')
def func2():
from m1 import x
print('来自m1的x', x)
y = 'm2'
#run.py
import m1
m1.func1()
#正在导入m1
#正在导入m2
#来自m2的y m2
#来自m1的x m1


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









