




 本文介绍了一种名为unCLIP的新型文本到图像生成模型,它利用CLIP图像嵌入来增强图像多样性和保真度。该模型通过两阶段过程工作,首先生成CLIP图像嵌入,然后解码为图像,实现了与GLIDE相似的图像质量,但在多样性方面表现更佳。
本文介绍了一种名为unCLIP的新型文本到图像生成模型,它利用CLIP图像嵌入来增强图像多样性和保真度。该模型通过两阶段过程工作,首先生成CLIP图像嵌入,然后解码为图像,实现了与GLIDE相似的图像质量,但在多样性方面表现更佳。
论文:https://cdn.openai.com/papers/dall-e-2.pdf
代码:https://github.com/lucidrains/DALLE2-pytorch
摘要
像CLIP这样的对比模型已经被证明可以学习稳健的图像表征,这些特征可以捕捉到语义和风格。为了利用这些表征来生成图像,我们提出了一个两阶段的模型:一个给定文本标题生成CLIP图像embedding的先验器,以及一个以图像embedding为条件生成图像的解码器。我们表明,明确地生成图像表征提高了图像的多样性,在逼真度和标题的相似度方面损失最小。我们以图像表征为条件的解码器也能产生图像的变化,保留其语义和风格,同时改变图像表征中不存在的非必要细节。此外,CLIP的联合嵌入空间使语言指导下的图像操作能够以zreo-shot的方式进行。我们对解码器使用扩散模型,并对先验的自回归和扩散模型进行实验,发现后者在计算上更有效率,并产生更高质量的样本。
介绍
最近计算机视觉的进展是由从互联网上收集的带标题的图像的大型数据集上的扩展模型推动的,在这个框架内,CLIP已经成为一个成功的图像表示学习者。CLIP embeddings有一些理想的特性:它们对图像分布的偏移是稳健的,有令人印象深刻的zero-shot能力,并已被微调以在各种视觉和语言任务上取得最先进的结果。
同时,扩散模型作为一个有前途的生成性建模框架出现,推动了图像和视频生成任务的最先进水平。
为了达到最佳效果,扩散模型利用了一种指导技术,它以样本的多样性为代价提高了样本的保真度(对于图像来说,就是逼真度)。
在这项工作中,我们将这两种方法结合起来,用于文本条件下的图像生成问题。我们首先训练一个扩散解码器来反转CLIP图像编码器,我们的反转器是非决定性的,可以产生对应于给定图像embedding的多个图像。编码器和它的近似反向(解码器)的存在允许超越文本到图像的翻译能力。编码器和它的近似反向(解码器)的存在允许超越文本到图像的翻译能力。正如在GAN反转中,对输入图像进行编码和解码会产生语义上相似的输出图像(图3)。我们还可以通过对输入图像的图像embeddings进行反转插值来实现输入图像之间的插值(图4)。
然而,使用CLIP潜在空间的一个显著优势是能够通过在任何编码文本向量的方向移动来对图像进行语义修改(图5),而在GAN潜在空间中发现这些方向涉及到运气和勤奋的人工检查。此外,对图像进行编码和解码也为我们提供了一个观察图像的哪些特征被CLIP识别或忽略的工具。

图1:从论文模型的生产版本中选取1024×1024的样本。
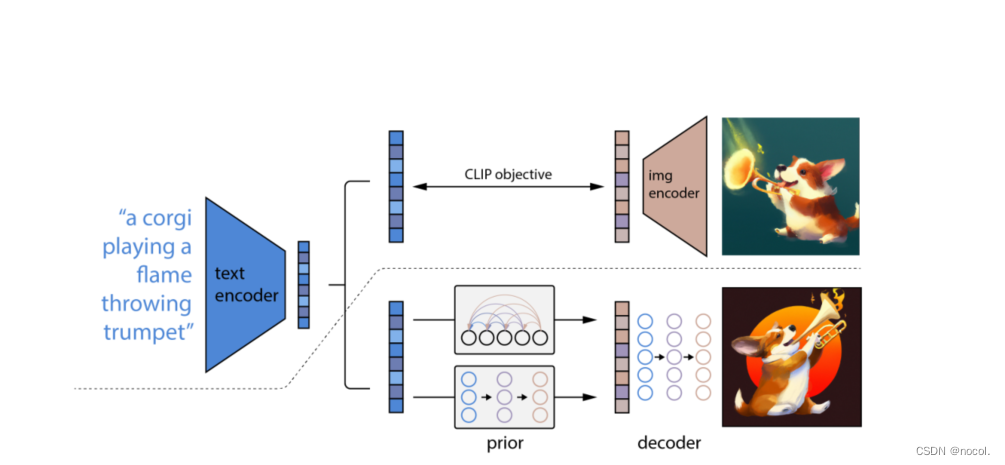
图2:unCLIP的概述。在虚线之上,我们描述了CLIP的训练过程,通过这个过程我们学习了文本和图像的联合表示空间。在虚线下面,我们描述了我们的文本到图像的生成过程:CLIP文本embedding首先被送入自回归或扩散prior,以产生一个图像embedding,然后这个embedding被用来调节扩散解码器,产生一个最终的图像。注意,在训练先验和解码器的过程中,CLIP模型被冻结。
对这张图的一点理解:
首先虚线上面是一个clip,这个clip是提前训练好的,在dalle2的训练期间不会再去训练clip,是个权重锁死的,在dalle2的训练时,输入也是一对数据,一个文本对及其对应的图像,首先输入一个文本,经过clip的文本编码模块(bert,clip对图像使用vit,对text使用bert进行编码,clip是基本的对比学习,两个模态的编码很重要,模态编码之后直接余弦求相似度了),
再输入一个图像,经过clip的图像编码模块,产生了图像的vector,这个图像vector其实是gt。产生的文本编码输入到第一个prior模型中,这是一个扩散模型,也可以用自回归的transformer,这个扩散模型输出一组图像vector,这时候通过经过clip产生的图像vector进行监督,此处其实是一个监督模型。
后面是一个decoder模块,在以往的dalle中,encoder和decoder是放在dvae中一起训练的,但是此处的deocder是单训的,也是一个扩散模型,其实虚线之下的生成模型,是将一个完整的生成步骤,变成了二阶段显式的图像生成,作者实验这种显式的生成效果更好。
这篇文章称自己为unclip,clip是将输入的文本和图像转成特征,而dalle2是将文本特征转成图像特征再转成图像的过程,其实图像特征到图像是通过一个扩散模型实现的。在deocder时既用了classifier-free guidence也用了clip的guidence,这个guidence指的是在decoder的过程中,输入是t时刻的一个带噪声的图像,最终输出是一个图像,这个带噪声的图像通过unet每一次得到的一个特征图可以用一个图像分类器去做判定,此处一般就用交叉熵函数做一个二分类,但是可以获取图像分类的梯度,利用这个梯度去引导扩散去更好的decoder。
为了获得一个完整的图像生成模型,我们将CLIP图像embeddings解码器与一个先验模型相结合,该模型从一个给定的文本标题中生成可能的CLIP图像embedding。我们将我们的文本到图像系统与其他系统如DALL-E和GLIDE进行比较,发现我们的样本在质量上与GLIDE相当,但在我们的生成中具有
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4676
4676

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









