




一、DDPM模型
多模态模型中的去噪扩散概率模型(Denoising Diffusion Probabilistic Models, DDPM)是一种基于扩散过程的生成模型,近年来在图像、音频、视频等多模态数据生成领域表现出色。以下从原理、流程、多模态应用及优缺点等方面详细解析DDPM。
1、DDPM核心思想
DDPM属于扩散模型(Diffusion Models),其灵感来源于物理学中的扩散过程(如热力学扩散)。核心思想是通过逐步加噪(前向过程)和去噪(反向过程)学习数据分布:
(1) 前向过程(Forward Process):
对输入数据 x0 逐步添加高斯噪声,经过 T 步后数据变为纯噪声 xT∼N(0,I)。
每一步的加噪通过固定方差调度 βt 控制:

(2) 反向过程(Reverse Process):
通过神经网络学习从噪声 xT 逐步去噪,恢复数据分布pθ( xt−1 ∣ xt):
2、训练与生成流程
(1)训练阶段
采样数据 x0∼q(x0)x0∼q(x0) 和时间步 t∼Uniform(1,T)t∼Uniform(1,T)。
生成噪声 ϵ∼N(0,I)ϵ∼N(0,I),计算加噪后的 xtxt。
训练神经网络 ϵθϵθ 预测噪声,优化损失函数:

(2)生成阶段
【1】从纯噪声 xT∼N(0,I)xT∼N(0,I) 开始。
【2】逐步去噪 TT 步:
预测噪声 ϵθ(xt,t)。
使用重参数化技巧计算 xt−1:
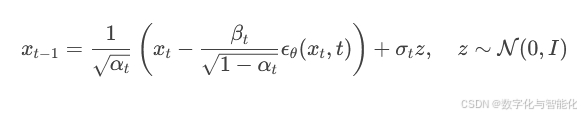
【3】最终得到生成数据 x0
3、多模态应用与扩展
DDPM的灵活性使其适用于多模态数据生成与跨模态转换:
(1)图像生成
经典案例:OpenAI的DALL·E 2、Stability AI的Stable Diffusion(结合CLIP文本编码器实现文本到图像生成)。
优势:生成质量高,细节丰富,支持渐进式编辑。
(2) 音频生成
如WaveGrad、DiffWave等模型,将音频波形或频谱图作为扩散目标。
(3) 视频生成
扩展为时空扩散模型(如Google的Imagen Video),逐帧生成连贯视频。
(4) 跨模态对齐
通过联合训练或条件扩散(Conditional DDPM)实现文本→图像、图像→音频等跨模态生成。例如:
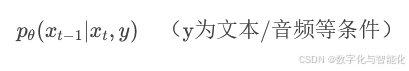
4、DDPM的优势与挑战
(1) 优势
生成质量高:相比GAN,DDPM生成的样本多样性更好,不易出现模式坍塌。
训练稳定性:无需对抗训练,损失函数简单。
渐进式生成:支持中间步骤的可控编辑(如插值、部分重构)。
(2) 挑战
采样速度慢:需迭代 TT 步(通常 T=1000T=1000),尽管有加速方法(DDIM、知识蒸馏),但仍比GAN慢。
计算成本高:尤其是高分辨率多模态数据(如4K视频)。
复杂条件控制:多模态条件融合(如文本+图像→3D生成)仍需改进。
5、关键改进与变体
(1) 加速采样
DDIM(Denoising Diffusion Implicit Models):将扩散过程重新参数化为非马尔可夫链,减少采样步数。
Progressive Distillation:将多步扩散蒸馏为少步模型。
(2) 条件生成
Classifier Guidance:利用分类器梯度增强条件控制。
CLIP-guided Diffusion:结合CLIP模型实现文本-图像对齐(如GLIDE)。
(3) 多模态统一架构
UniDiffuser:单一模型处理图像、文本、音频等多模态生成与转换。
二、SDXL模型
SDXL(Stable Diffusion XL) 是 Stability AI 推出的高性能多模态生成模型,属于 Stable Diffusion 系列的升级版本,专注于高质量图像生成和跨模态应用(如文本到图像、图像编辑等)。以下从架构设计、技术改进、多模态能力及应用场景等方面详细解析 SDXL。
1、SDXL 核心架构
SDXL 基于 扩散模型(Diffusion Model) 框架,但通过多项创新显著提升了生成质量和多模态兼容性。其核心架构分为以下几个模块:
(1) 双文本编码器(Dual Text Encoder)
CLIP ViT-L/14:继承自 Stable Diffusion 2.0,提供通用的文本特征表示。
OpenCLIP ViT-bigG/14:新增的更大规模文本编码器,增强对复杂语义的理解(如抽象概念、长文本描述)。
作用:双编码器融合后的文本特征能更精准地引导图像生成,解决传统模型对复杂提示词(prompt)理解不足的问题。
(2) 改进的 U-Net 主干网络
参数量扩大:SDXL 的 U-Net 比 SD 1.5/2.0 更大,包含约 2.6B 参数(SD 1.5 为 860M),网络深度和宽度增加。
多尺度训练:支持原生 1024×1024 分辨率生成(无需后期超分),同时兼容低分辨率输入。
微调设计:引入更多注意力层(Self-Attention 和 Cross-Attention),增强对全局结构和细节的控制。
(3) 多阶段扩散流程
SDXL 采用 两阶段生成策略 提升效率和质量:
【1】基础模型(Base Model):生成低分辨率潜变量(如 64×64)。
【2】精炼模型(Refiner Model):对潜变量进一步去噪,增强细节(如纹理、光影)。
两阶段分工减少计算负担,同时避免单阶段模型过平滑的问题。
2、关键技术改进
(1) 训练数据与预处理
数据规模:训练数据集包含数亿张高质量图像-文本对,覆盖艺术、摄影、设计等多领域。
数据过滤:通过 CLIP 分数和人工审核剔除低质量样本,减少生成偏差。
多模态对齐:文本-图像对经过严格对齐,提升条件生成的准确性。
(2) 条件控制机制
Classifier-Free Guidance(CFG)优化:默认 CFG 尺度调整为 5-7(SD 1.5 为 7.5),平衡生成多样性与提示词跟随性。
附加条件输入:支持深度图、边缘检测图等控制信号,实现可控生成(类似 ControlNet 功能但更轻量)。
(3) 采样效率提升
改进的调度器(Scheduler):采用 DPM++ 2M Karras 等高级采样算法,减少生成步数(约 20-30 步即可高质量输出)。
潜在空间优化:通过 VAE 的改进压缩率,降低计算复杂度。
3、多模态能力与应用场景
(1) 文本到图像生成
复杂提示词理解:支持长文本、抽象概念(如“赛博朋克风格的未来城市,霓虹灯下下雨的街道”)。
多语言支持:兼容英语、中文、日语等,非英语提示词生成质量显著提升。
(2) 图像编辑与扩展
Inpainting/Outpainting:基于掩码的局部修改或画布扩展。
风格迁移:通过文本提示调整图像风格(如“梵高风格的星空”)。
(3) 跨模态应用
文本+草图→图像:结合 ControlNet 实现草图引导生成。
图像→文本:通过反向编码器生成描述(需配合外部模型如 BLIP-2)。
(4) 与其他工具的集成
< 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











