




目录
一、快排扩展
1.1、快排三路划分
三路划分算法解析:
当⾯对有⼤量跟key相同的值时
,三路划分的核⼼思想有点类似hoare的左右指针和lomuto的前后指针的结合。核⼼思想是把数组中的数据分为三段【⽐key⼩的值】 【跟key相等的值】【⽐key⼤的
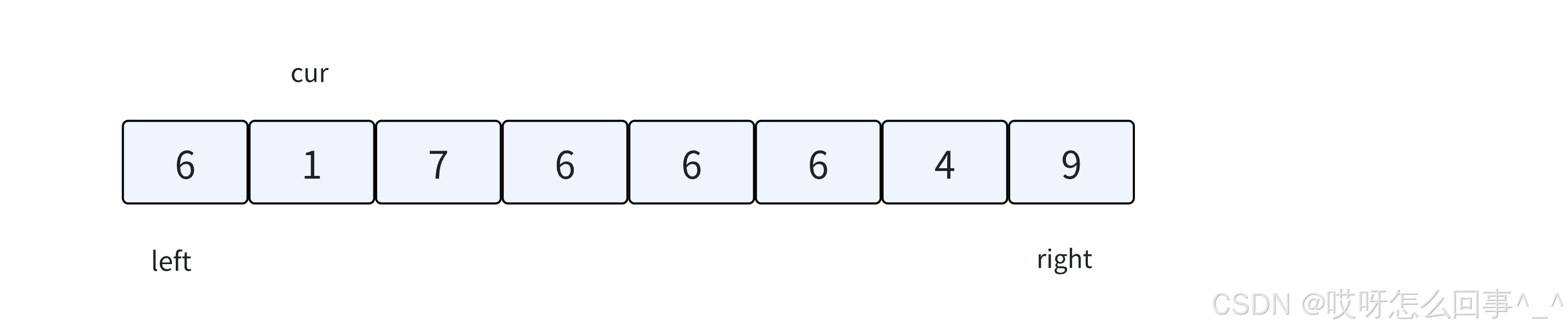
值】,所以叫做三路划分算法。结合下图,理解⼀下实现思想:
1.
key默认取left位置的值。
2.
left指向区间最左边,right指向区间最后边,cur指向left+1位置。
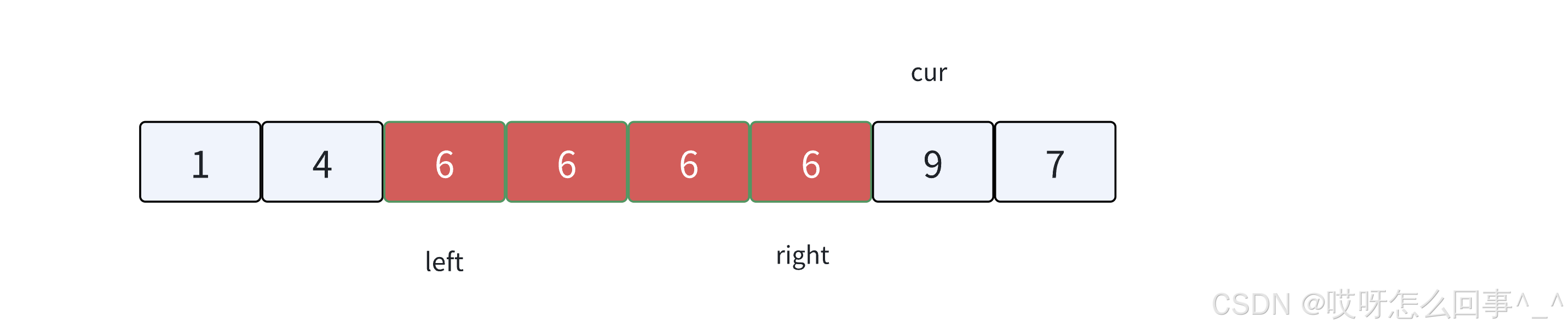
3.
cur遇到⽐key⼩的值后跟left位置交换,换到左边,left++,cur++。
4.
cur遇到⽐key⼤的值后跟right位置交换,换到右边,right--。
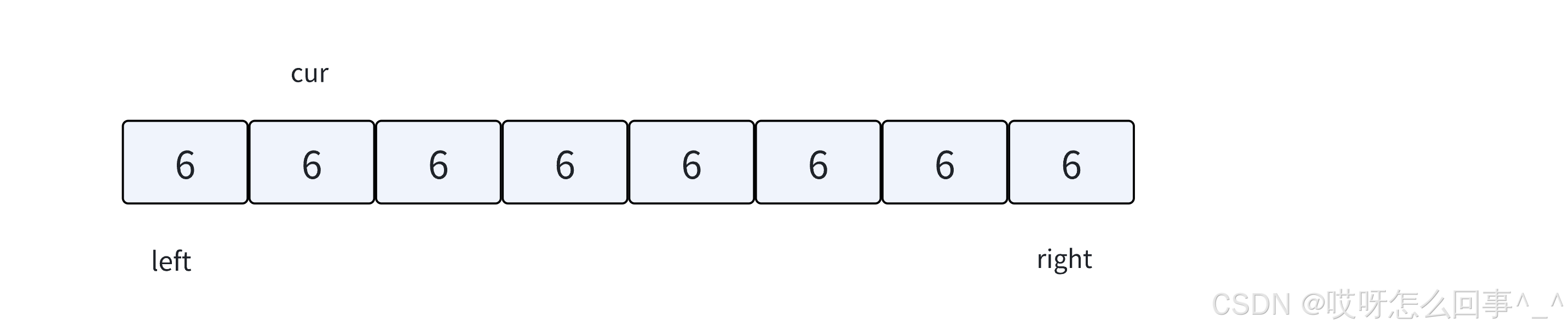
5.
cur遇到跟key相等的值后,cur++。
6.
直到cur > right结束

源代码:
void Quicksort_1(int* arr, int begin, int end)
{
if (begin >= end)
return;
int left = begin, right = end, key = arr[left];
int cur = left + 1;
while (cur <= right)
{
if (arr[cur] < key)
{
swap(arr[cur], arr[left]);
left++;
cur++;
}
else if (arr[cur] > key)
{
swap(arr[cur], arr[right]);
right--;
}
else cur++;
}
//递归
//单趟排序之后left 和 right 形成的闭区间全是和key相同的元素
Quicksort_1(arr, begin, left - 1);
Quicksort_1(arr, right + 1, end);
}1.2、快排自省排序
introsort是introspective sort采⽤了缩写,他的名字其实表达了他的实现思路,他的思路就是进⾏⾃我侦测和反省,快排递归深度太深(sgi stl中使⽤的是深度为2倍排序元素数量的对数值)那就说明在这种数据序列下,选key出现了问题,性能在快速退化,那么就不要再进⾏快排分割递归了,改换为堆排序进⾏排序。
处理递归深度过深的情况
源代码:
void Insertsort(int* arr, int size)
{
for (int i = 0; i < size - 1; i++)
{
int end = i;
int data = arr[end + 1];
while (end >= 0)
{
if (arr[end] > data)
{
arr[end + 1] = arr[end];
}
else
{
break;
}
end--;
}
arr[end + 1] = data;
}
}
void Adjustdown(int* arr, int parent, int size)
{
int child = parent * 2 + 1;
while (child < size)
{
if (child + 1 < size && arr[child + 1] > arr[child])
{
++child;
}
if (arr[child] > arr[parent])
{
swap(arr[child], arr[parent]);
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}
void Heapsort(int* arr, int size)
{
int start = (size - 1 - 1) / 2;//第一个根节点的下标
for (int i = start; i >= 0; i--)
{
Adjustdown(arr, i, size);//排升序,建大堆
}
for (int i = size - 1; i >= 0; i--)
{
swap(arr[i], arr[0]);//每次将最大的数据放到最后
Adjustdown(arr, 0, i);
}
}
void Introsort(int *arr, int begin, int end, int depth, int defaultDepth)
{
if (begin >= end)
return;
int left = begin, right = end;
if (right - left + 1 > 16)
{
Insertsort(arr + left, right - left + 1);
return;
}
if (depth > defaultDepth)
{
//堆排
Heapsort(arr + left, right - left + 1);
return;
}
depth++;
int prev = left, cur = left + 1;
int keyi = left + rand() % (right - left + 1);
swap(arr[left], arr[keyi]);
int key = arr[left];
while (cur <= right)
{
if (arr[cur] < key)
{
++prev;
swap(arr[prev], arr[cur]);
}
cur++;
}
swap(arr[prev], arr[left]);
Introsort(arr, begin, prev - 1, depth, defaultDepth);
Introsort(arr, prev + 1, end, depth, defaultDepth);
}二、外排序之文件归并排序
外排序介绍
外排序(External sorting)是指能够处理极⼤量数据的排序算法。通常来说,外排序处理的数据不能⼀次装⼊内存,只能放在读写较慢的外存储器(通常是硬盘)上。外排序通常采⽤的是⼀种“排序-归并”的策略。在排序阶段,先读⼊能放在内存中的数据量,将其排序输出到⼀个临时⽂件,依此进⾏,将待排序数据组织为多个有序的临时⽂件。然后在归并阶段将这些临时⽂件组合为⼀个⼤的有序⽂件,也即排序结果。
跟外排序对应的就是内排序,我们之前讲的常⻅的排序,都是内排序,他们排序思想适应的是数据在内存中,⽀持随机访问。归并排序的思想不需要随机访问数据,只需要依次按序列读取数据以归
并排序既是⼀个内排序,也是⼀个外排序。
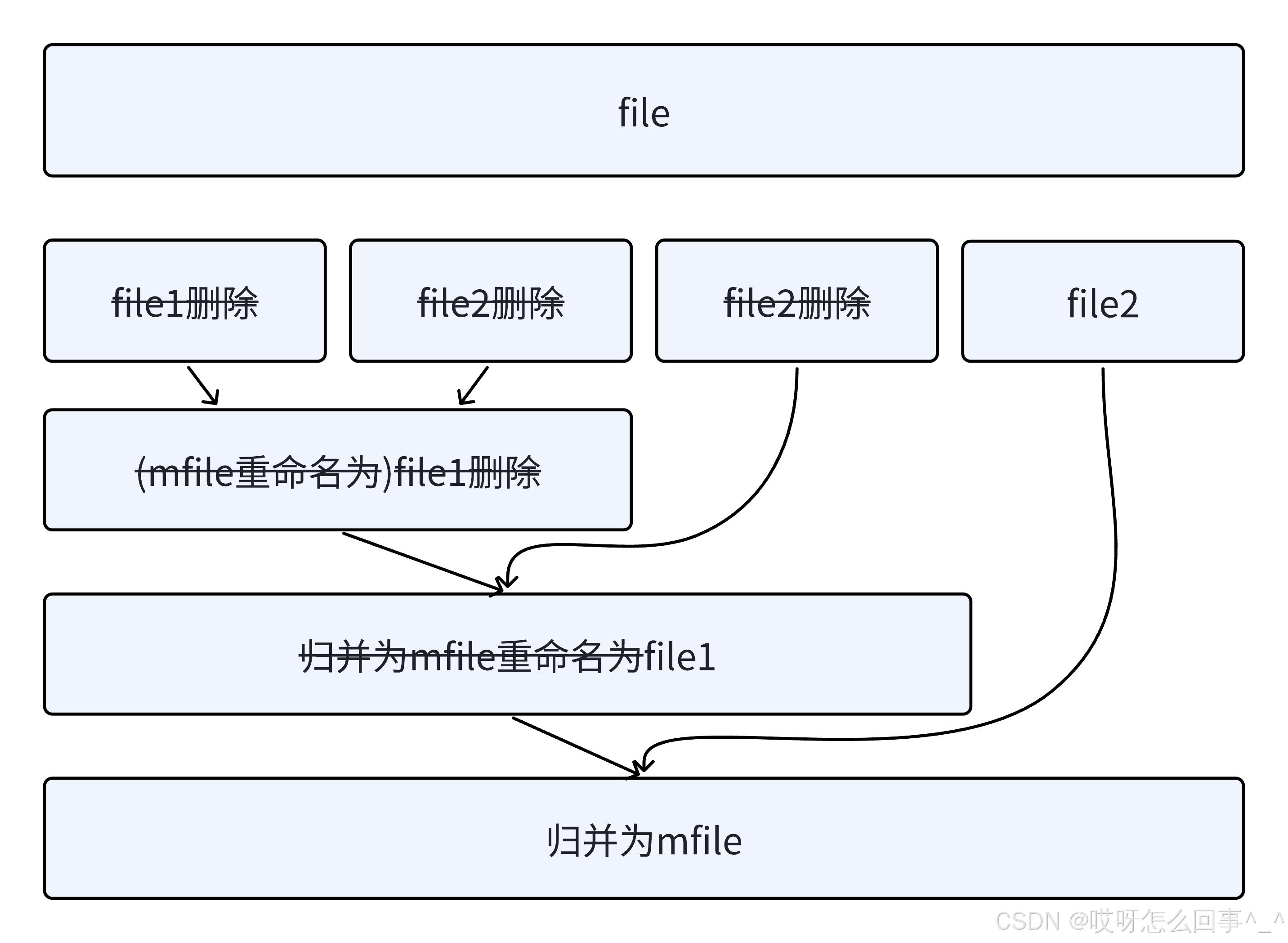
⽂件归并排序思路分析
1.
读取n个值排序后写到file1,再读取n个值排序后写到file2
2.
file1和file2利⽤归并排序的思想,依次读取⽐较,取⼩的尾插到mfile,mfile归并为⼀个有序⽂件
3.
将file1和file2删掉,mfile重命名为file1
4.
再次读取n个数据排序后写到file2
5.
继续⾛file1和file2归并,重复步骤2,直到⽂件中⽆法读出数据。最后归并出的有序数据放到了
file1中


// 外排序之文件归并排序
//思路:
//先创建随机数据,写到一个大文件里面,这个大文件就是需要被排序的文件
//但是文件太大,将其分为小文件进行排序之后归并
//每次从这个大文件中取出一定量数据,写到临时数组中,对这数组排序之后,将数组中有序的数据写到新文件中
//每次将这个新文件和下一次相同操作形成新文件进行归并形成更大的文件,一直到大文件被读取完成
//其中可能出现最后一次读取数据比一定量少的,此时需要特殊处理
void CreatData(const char* big_file)
{
srand((unsigned int)time(0));
int N = 1000000;
FILE* fin = fopen(big_file, "w");
if (fin == nullptr)
{
perror("fopen failed\n");
return;
}
for (int i = 0; i < N; i++)
{
int x = rand() % 10000 + i;
fprintf(fin, "%d\n", x);
}
fclose(fin);
}
int Compare(const void *a, const void *b)
{
return *(int*)a - *(int*)b;
}
//每次从大文件中读取n个数据进行排序之后放到新文件中
//返回值表示读取到的数据
int ReadnDataSort(const char* file, int n, FILE* fout)
{
//将数据写入数组
int* arr = (int*)malloc(sizeof(int) * n);
if (arr == nullptr)
{
free(arr);
perror("malloc failed\n");
return 0;
}
int x = 0, k = 0;//x为每次读取的数据,k为读取的个数
//读取完之后文件指针会记录这个位置,下次默认从这里读取
while (k < n && fscanf(fout, "%d", &x)!= EOF)
{
arr[k++] = x;
}
if (k == 0)//没有数据直接返回
{
free(arr);
return 0;
}
//排序
qsort(arr, k, sizeof(int), Compare);
//排序之后将有序的数据写到file文件
FILE* fin = fopen(file, "w");
if (fin == nullptr)
{
perror("fopen failed\n");
free(arr);
return 0;
}
for (int i = 0; i < k; i++)
{
fprintf(fin, "%d\n", arr[i]);
}
fclose(fin);
free(arr);
return k;
}
//两个文件归并为一个文件
void Mergefile(const char* file1, const char* file2, const char* myfile)
{
FILE* fout1 = fopen(file1, "r");
if (fout1 == nullptr)
{
perror("fopen failed\n");
return;
}
FILE* fout2 = fopen(file2, "r");
if (fout2 == nullptr)
{
perror("fopen failed\n");
return;
}
FILE* fin = fopen(myfile, "w");
if (fin == nullptr)
{
perror("fopen failed\n");
return;
}
int x1 = 0, x2 = 0;
int ret1 = fscanf(fout1, "%d", &x1);
int ret2 = fscanf(fout2, "%d", &x2);
//归并思路
while (ret1 != EOF && ret2 != EOF)
{
//只有写入fin了才去读取,否则只能读取100个
if (x1 < x2)
{
fprintf(fin, "%d\n", x1);
ret1 = fscanf(fout1, "%d", &x1);
}
else
{
fprintf(fin, "%d\n", x2);
ret2 = fscanf(fout2, "%d", &x2);
}
//这种写法只能读取100个,因为两个同时在走-----错误写法
//if (x1 < x2)
//{
// fprintf(fin, "%d\n", x1);
//}
//else
//{
// fprintf(fin, "%d\n", x2);
//}
//ret1 = fscanf(fout1, "%d", &x1);
//ret2 = fscanf(fout2, "%d", &x2);
}
while (ret1 != EOF)
{
fprintf(fin, "%d\n", x1);
ret1 = fscanf(fout1, "%d", &x1);
}
while (ret2 != EOF)
{
fprintf(fin, "%d\n", x2);
ret2 = fscanf(fout2, "%d", &x2);
}
fclose(fout1);
fclose(fout2);
fclose(fin);
}
int main()
{
const char* big_file = "data.txt";
CreatData(big_file);
int n = 100;//每次读取的个数
const char* file1 = "file1.txt";
const char* file2 = "file2.txt";
const char* myfile = "myfile.txt";
//打开大文件,准备读取
FILE* fout = fopen(big_file, "r");
if (fout == nullptr)
{
perror("fopen failed\n");
return 0;
}
ReadnDataSort(file1, n, fout);
ReadnDataSort(file2, n, fout);
//不能这样写,因为这样写每次都是新打开的big_file,那么文件指针一直从开头开始,会出现死循环
//并且file1和file2的内容完全相同,所以要在ReadnDataSort外面打开要读的文件
//ReadnDataSort(file1, n, big_file);
//ReadnDataSort(file2, n, big_file);
//进行合并
while (1)
{
Mergefile(file1, file2, myfile);
remove(file1);
remove(file2);
rename(myfile, file1);//最终排序的总结果在file1.txt里面
int k = 0;//读取到的数据
if ((k = ReadnDataSort(file2, n, fout)) == 0)
{
printf("文件读取并排序完毕\n");
break;
}
}
fclose(fout);
return 0;
}

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









