




- 对象池
- 单例模式 以及 手动实现
委托,事件相关
滥用委托的缺点:
缺点 1: 把多个方法绑定给委托时如果不小心把 “+=” 写成 “=”,会把委托之前绑定的方法全覆盖掉,这样会使程序的安全性降低。
缺点 2: 过度使用委托可能会导致内存泄漏。因为委托会引用一个方法,如果这个方法是实例方法(非静态),那么这个方法必定隶属于一个对象。拿一个委托绑定这个方法,那么这个方法所属的对象就必定存在于内存中。即使没有其他引用变量引用这个对象了,这个对象的内存也不能被释放,因为一旦释放了对象的内存,委托就不能间接调用对象的方法了。除非这个实例方法和委托解绑,方法所属的对象才会在没用的时候被释放掉。随着泄露的内存越来越多,程序的性能会下降。
缺点3: 过度使用委托会使可读性下降。
原文:C# 委托 (结合Unity)_onvaluechangedevent 赋值-优快云博客
委托的赋值
public delegate void MyDelegate();
class Program{
public static void Test(){}
static void Main(string[] args)
{
MyDelegate myDelegate;
myDelegate += Test; //这行会报错
}
}
因为此时这个委托变量是在方法中定义,是个局部变量,它并不会被默认初始化,也就是还未被赋值。那么我们这时也就不能用 += 为委托变量绑定方法了。除非把 myDelegate 显式地赋值成 null,这样就不会报错
MyDelegate myDelegate = null;
myDelegate += Test;C# 提供的内置委托
Action
Action委托可以封装void返回类型的方法
Action //可封装无参无返回值类型的方法
Action<T> //可封装有一个参数,无返回值类型的方法
Action<T1,T2>
Action<T1,T2 .... T16>
之前我们自定义委托时要先声明再实例化,但Action可以直接实例化。因为Action可指向的方法类型系统已经定义好了,我们可通过泛型来限定方法传入的参数类型
public delegate void Mydelegate();
Mydelegate myDelegate;
//等同于
Action myDelegate;
Func
Func可以封装带有一个返回值的方法,它可以传递0或者多到16个参数类型(参数类型要和指定的方法的参数列表顺序一致),和一个返回类型(泛型中的最后一个类型)
Func<out TResult>
Func<T,out TResult>
Func<T1,T2....T16,out TResult>
//例如
Func<int,float,string> func;
//可封装第一个参数是int,第二个参数是float,返回值是string的方法
委托的好处:
复用性:把重复使用的代码封装成方法
可扩展性:遵循 “开闭原则”,即面向修改关闭,面向扩展开放。尽量保证面对新的需求时不去修改原有的代码,而是在原有代码的基础上进行扩展。
事件
如果一个委托是为事件准备的,那么它有一个命名规范:在事件名后加上 EventHandler
public delegate void OnOrderEventHandler(float price);
//声明一个委托字段
private OnOrderEventHandler onOrderEventHandler;
//声明事件的完整格式。可以看出事件是委托字段的一个包装器,正如属性是字段的包装器一样
//因为要让其他类能够访问这个私有委托,所以事件声明为public
public event OnOrderEventHandler OnOrder
{
add //添加事件处理器
{
onOrderEventHandler += value; //value是关键字,指代之后传进来的事件处理器
}
remove //移除事件处理器
{
onOrderEventHandler -= value;
}
}
事件的声明是为委托字段提供 add 和 remove 构造器,相当于提供添加和移除方法的功能。也就是说,事件相当于委托的包装器。
事件较于委托的区别
事件是委托字段的包装器。包装器为委托提供了保护和限制作用。我们拿到了一个委托字段后,可以在任何地方去绑定与之类型兼容的方法,也可以在任何地方调用。可是将委托封装进事件之后,事件就只对外提供添加和移除的操作。也就是其他类只能通过 “+=” 和 "-="来为包装的委托添加和移除方法,但是不再有权利去调用这个委托了。

//声明一个委托字段
private OnOrderEventHandler onOrderEventHandler;
//声明事件的完整格式。可以看出事件是委托字段的一个包装器,正如属性是字段的包装器一样
public event OnOrderEventHandler OnOrder
{
add //添加事件处理器
{
onOrderEventHandler += value; //value是关键字,指代之后传进来的事件处理器
}
remove //移除事件处理器
{
onOrderEventHandler -= value;
}
}
//简略
public event OnOrderEventHandler OnOrder;
Unity多线程
参考:Unity多线程知识点记录_unity 多线程-优快云博客
线程其实是同时(并行)执行的,在Unity中虽然有协程可以协助主线程进行计算,但是协程的计算还是在主线程中的,如果协程要计算的数据过大,需要等待,这时候就会影响主线程的其他方法执行
Unity可以使用多线程,但是要避免使用线程
在 Unity 中,你不能直接使用传统的线程同步和并发机制,因为 Unity 是基于单线程的执行模型的。Unity 的主要执行线程是主线程(也称为渲染线程),它负责处理游戏逻辑、渲染和用户输入等。直接在 Unity 中创建和操作线程是不安全的,会导致不可预测的结果,可能会破坏 Unity 的执行流程,甚至导致程序崩溃。
Unity自己本身UnityEngine所使用的API是不能被多线程调用的,所以Unity是不能使用多线程的,但是C#中可以使用多线程,Unity使用C#进行脚本编辑,故而Unity也可以通过C#来调用多线程。
Unity使用多线程时要注意几点:
- 变量都是共享的(都能指向相同的内存地址)
- UnityEngine 的 API 不能在分线程运行
- UnityEngine 定义的基本结构(int, float, struct 定义的数据类型)可以在分线程计算,如 Vector3(struct)可以, 但 Texture2d(class,根父类为 Object) 不可以。
- UnityEngine 定义的基本类型的函数可以在分线程运行
线程的生命周期
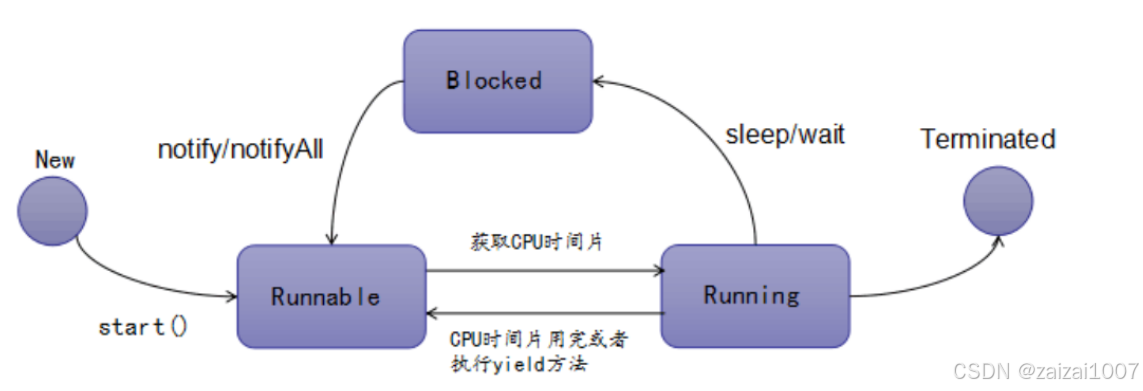
线程的生命周期包含5个阶段,包括:新建、就绪、运行、阻塞、销毁。
- 新建:就是刚使用new方法,new出来的线程;
- 就绪:就是调用的线程的start()方法后,这时候线程处于等待CPU分配资源阶段,谁先抢的CPU资源,谁开始执行;
- 运行:当就绪的线程被调度并获得CPU资源时,便进入运行状态,run方法定义了线程的操作和功能;
- 阻塞:在运行状态的时候,可能因为某些原因导致运行状态的线程变成了阻塞状态,比如sleep()、wait()之后线程就处于了阻塞状态,这个时候需要其他机制将处于阻塞状态的线程唤醒,比如调用notify或者notifyAll()方法。唤醒的线程不会立刻执行run方法,它们要再次等待CPU分配资源进入运行状态;
- 销毁:如果线程正常执行完毕后或线程被提前强制性的终止或出现异常导致结束,那么线程就要被销毁,释放资源;
- new Thread():创建一个线程
- start():开启创建的线程
- join():当前线程等待另一个线程结束后,在执行
- Sleep();等待N毫秒后继续执行
- Suspend():该方法并不终止未完成的线程,它仅仅挂起当前线程,以后还可恢复;
- Resume():恢复被Suspend()方法挂起的线程的执行。
- Abort():结束线程
Suspend(挂起)、Resume(恢复)已经过时,其中Suspend(挂起)方法被认为是不安全的,因为它可能会导致线程死锁、死活锁或其他不可预测的行为。
欧拉角,旋转矩阵,四元数
参考:四元数(Quaternion)和旋转 +欧拉角 - Jerry_Jin - 博客园
- 矩阵旋转
- 优点:
- 旋转轴可以是任意向量;
- 缺点:
- 旋转其实只需要知道一个向量+一个角度,一共4个值的信息,但矩阵法却使用了16个元素;
- 而且在做乘法操作时也会增加计算量,造成了空间和时间上的一些浪费;
- 优点:
- 欧拉旋转
- 优点:
- 很容易理解,形象直观;
- 表示更方便,只需要3个值(分别对应x、y、z轴的旋转角度);但按我的理解,它还是转换到了3个3*3的矩阵做变换,效率不如四元数;
- 缺点:
- 优点:
- 四元数旋转
- 优点:
- 可以避免万向节锁现象;
- 只需要一个4维的四元数就可以执行绕任意过原点的向量的旋转,方便快捷,在某些实现下比旋转矩阵效率更高;
- 可以提供平滑插值;
- 缺点:
- 比欧拉旋转稍微复杂了一点点,因为多了一个维度;
- 理解更困难,不直观;
- 优点:
C# 数组,ArrayList ,List 的区别
数组
数组在C#中最早出现的。在内存中是连续存储的,所以它的索引速度非常快,而且赋值与修改元素也很简单。
但是数组存在一些不足的地方。在数组的两个数据间插入数据是很麻烦的,而且在声明数组的时候必须指定数组的长度,数组的长度过长,会造成内存浪费,过段会造成数据溢出的错误。如果在声明数组时我们不清楚数组的长度,就会变得很麻烦。
针对数组的这些缺点,C#中最先提供了ArrayList对象来克服这些缺点。
ArrayList
ArrayList是命名空间System.Collections下的一部分,在使用该类时必须进行引用,同时继承了IList接口,提供了数据存储和检索。ArrayList对象的大小是按照其中存储的数据来动态扩充与收缩的。所以,在声明ArrayList对象时并不需要指定它的长度。
//ArrayList
ArrayList list1 = new ArrayList();
//新增数据
list1.Add("cde");
list1.Add(5678);
//修改数据
list[2] = 34;
//移除数据
list.RemoveAt(0);
//插入数据
list.Insert(0, "qwe");ArrayList会把所有插入其中的数据当作为object类型来处理,在我们使用ArrayList处理数据时,很可能会报类型不匹配的错误,也就是ArrayList不是类型安全的。在存储或检索值类型时通常发生装箱和取消装箱操作,带来很大的性能耗损。
装箱与拆箱的概念:
简单的说:
装箱:就是将值类型的数据打包到引用类型的实例中
比如将string类型的值abc赋给object对象obj
String i=”abc”;
object obj=(object)i;拆箱:就是从引用数据中提取值类型
比如将object对象obj的值赋给string类型的变量i
object obj=”abc”;
string i=(string)obj;泛型List
因为ArrayList存在不安全类型与装箱拆箱的缺点,所以出现了泛型的概念。List类是ArrayList类的泛型等效类,它的大部分用法都与ArrayList相似,因为List类也继承了IList接口。最关键的区别在于,在声明List集合时,我们同时需要为其声明List集合内数据的对象类型。
List<string> list = new List<string>();
//新增数据
list.Add(“abc”);
//修改数据
list[0] = “def”;
//移除数据
list.RemoveAt(0);单例模式
如果不使用某个类,那么那个类中的静态字段不会被初始化。
静态成员仅在其所在类首次被使用时初始化
饿汉模式 ,饱汉模式



















 2019
2019

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









