



 本文解析了LeetCode上一道经典题目——求解字符串中最长无重复字符子串的长度。通过两种算法实现,一种使用string操作,另一种采用双指针技巧,详细分析了每种方法的时间复杂度及优劣。
本文解析了LeetCode上一道经典题目——求解字符串中最长无重复字符子串的长度。通过两种算法实现,一种使用string操作,另一种采用双指针技巧,详细分析了每种方法的时间复杂度及优劣。
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/longest-substring-without-repeating-characters
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
题目描述:给定一个字符串,请你找出其中不含有重复字符的 最长子串 的长度。
示例 1:
输入: “abcabcbb”
输出: 3
解释: 因为无重复字符的最长子串是 “abc”,所以其长度为 3。
示例 2:
输入: “bbbbb”
输出: 1
解释: 因为无重复字符的最长子串是 “b”,所以其长度为 1。
示例 3:
输入: “pwwkew”
输出: 3
解释: 因为无重复字符的最长子串是 “wke”,所以其长度为 3。
请注意,你的答案必须是 子串 的长度,“pwke” 是一个子序列,不是子串。
思路如下:
用空string依次读s的每个字符,如果这个字符不在string里,则将这个字符追加到string末尾。如果这个字符出现在这个string里,则将当前s。size()与当前最长子串的长度进行比较,然后用find()返回这个字符在string中的位置pos,并将string的第一个字符到位置pos的字符清除掉,将该字符追加到string末尾。
算法只遍历了一次s,但是循环中多次调用了库函数,所以效率不是很高。
if (0 == s.size())
return 0;
string str;
auto it = s.begin();
int count = 0;
int pos = 0;
int tempCount = 0;
while (s.end() != it)
{
pos = str.find(*it);
if (-1 != pos)
{
tempCount = str.size();
if (tempCount > count)
count = tempCount;
str.erase(str.begin(), str.begin()+pos+1);
}
str += *it;
++it;
}
tempCount = str.size();
if (tempCount > count)
count = tempCount;
return count;
评论中别的同学答案如下,虽然时间复杂度是O(N^2),但是没有调用库函数,所以我认为效率是高于上面我写的代码。
int size = s.size();
int i = 0,j,k,max = 0;
for (k = 0; k < size; ++k)
{
for (j = i; j < k; ++j)
{
if (s[j] == s[k])
{
i = j+1;
break;
}
}
if (k-i+1 > max)
max = k-i+1;
}
return max;
}
分析:
i标记当前无重复字符的子串中的第一个元素。k则标记是这个子串的末尾。
j是从当前无重复字符的子串开始与k所指的元素进行比较,如果s[j] == s[k] ,则当前子串中出现了重复字符,则应重置当前的子串,这一步将i置在j的后面位置,从而使当前标记的子串中无重复字符。
每次重置i的位置时,将当前的子串长度k-i+1与max比较。
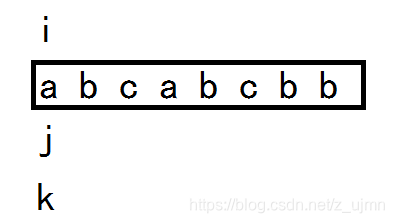
刚开始i,j,k都在字符串“abcabcbb”的0位置。
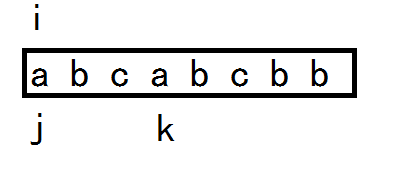
当k走到a时,当前子串i-k中出现了第一个重复字符:s[j] == s[k];
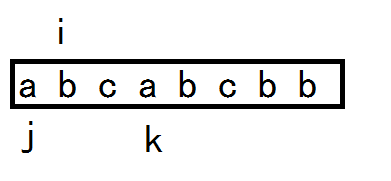
将i重置,置于j+1的位置。当前子串再次成为无重复字符串。记录下子串长度,与max比较。
依次类推,不难得出结果。

















 715
715

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









