




一、索引是什么?
索引是数据库中用来提高性能的最常用工具。
索引用于快速找出在某个列中有一特定值的行。如果不使用索引,MySQL 必须从第 1条记录开始然后读完整个表直到找出相关的行。表越大,花费的时间越多。如果表中查询的列有一个索引,MySQL 能快速到达一个位置去搜寻数据文件的中间,没有必要看所有数据。如果一个表有 1000 行,这比顺序读取至少快 100 倍。注意如果需要访问大部分行,顺序读取要快得多,因为此时应避免磁盘搜索。大多数 MySQL 索引(如 PRIMARY KEY、UNIQUE、INDEX 和 FULLTEXT 等)在 BTREE 中存储。只是空间列类型的索引使用 RTREE,并且 MEMORY 表还支持 HASH 索引。
数据库索引好比是一本书前面的目录,能加快数据库的查询速度。
例如这样一个查询:select * from table1 where id=44。如果没有索引,必须遍历整个表,直到ID等于44的这一行被找到为止;有了索引之后(必须是在ID这一列上建立的索引),直接在索引里面找44(也就是在ID这一列找),就可以得知这一行的位置,也就是找到了这一行。可见,索引是用来定位的。
索引分为聚簇索引和非聚簇索引两种,聚簇索引 是按照数据存放的物理位置为顺序的,而非聚簇索引就不一样了;显然在一个基本表上最多只能建立一个聚簇索引。建立聚簇索引后,更新该索引列上的数据时,往往导致表中记录的物理顺序的变更,代价较大,因此对于经常更新得列不宜建立聚簇索引,聚簇索引能提高多行检索的速度,而非聚簇索引对于单行的检索很快。建立一个聚簇索引如:
create cluster index id on Student(id);
总结:
建立索引的目的是加快对表中记录的查找或排序。
为表设置索引要付出代价的:一是增加了数据库的存储空间,二是在插入和修改数据时要花费较多的时间(因为索引也要随之变动)。
二、为什么要建立索引:
创建索引可以大大提高系统的性能。
第一,通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。
第二,可以大大加快数据的检索速度,这也是创建索引的最主要的原因。
第三,可以加速表和表之间的连接,特别是在实现数据的参考完整性方面特别有意义。
第四,在使用分组和排序子句进行数据检索时,同样可以显著减少查询中分组和排序的时间。
第五,通过使用索引,可以在查询的过程中,使用优化隐藏器,提高系统的性能。
也许会有人要问:增加索引有如此多的优点,为什么不对表中的每一个列创建一个索引呢?因为,增加索引也有许多不利的方面。
第一,创建索引和维护索引要耗费时间,这种时间随着数据量的增加而增加。
第二,索引需要占物理空间,除了数据表占数据空间之外,每一个索引还要占一定的物理空间,如果要建立聚簇索引,那么需要的空间就会更大。
第三,当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,这样就降低了数据的维护速度。
二、在哪里建立索引:
索引是建立在数据库表中的某些列的上面。在创建索引的时候,应该考虑在哪些列上可以创建索引,在哪些列上不能创建索引。一般来说,应该在这些列上创建索引:
在经常需要搜索的列上,可以加快搜索的速度;
在作为主键的列上,强制该列的唯一性和组织表中数据的排列结构;
在经常用在连接的列上,这些列主要是一些外键,可以加快连接的速度;在经常需要根据范围进行搜索的列上创建索引,因为索引已经排序,其指定的范围是连续的;
在经常需要排序的列上创建索引,因为索引已经排序,这样查询可以利用索引的排序,加快排序查询时间;
在经常使用在WHERE子句中的列上面创建索引,加快条件的判断速度。
同样,对于有些列不应该创建索引。一般来说,不应该创建索引的的这些列具有下列特点:
第一,对于那些在查询中很少使用或者参考的列不应该创建索引。这是因为,既然这些列很少使用到,因此有索引或者无索引,并不能提高查询速度。相反,由于增加了索引,反而降低了系统的维护速度和增大了空间需求。
第二,对于那些只有很少数据值的列也不应该增加索引。这是因为,由于这些列的取值很少,例如人事表的性别列,在查询的结果中,结果集的数据行占了表中数据行的很大比例,即需要在表中搜索的数据行的比例很大。增加索引,并不能明显加快检索速度。
第三,对于那些定义为text, image和bit数据类型的列不应该增加索引。这是因为,这些列的数据量要么相当大,要么取值很少,不利于使用索引。
第四,当修改性能远远大于检索性能时,不应该创建索引。这是因为,修改性能和检索性能是互相矛盾的。当增加索引时,会提高检索性能,但是会降低修改性能。当减少索引时,会提高修改性能,降低检索性能。因此,当修改操作远远多于检索操作时,不应该创建索引。
精简来说,索引是一种结构.在SQL Server中,索引和表(这里指的是加了聚集索引的表)的存储结构是一样的,都是B树,B树是一种用于查找的平衡多叉树.理解B树的概念如下图:
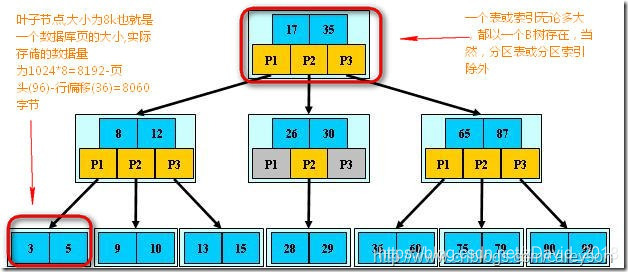
理解为什么使用B树作为索引和表(有聚集索引)的结构,首先需要理解SQL Server存储数据的原理.
在SQL SERVER中,存储的单位最小是页(PAGE),页是不可再分的。就像细胞是生物学中不可再分的,或是原子是化学中不可再分的最小单位一样.这意味着,SQL SERVER对于页的读取,要么整个读取,要么完全不读取,没有折中.
在数据库检索来说,对于磁盘IO扫描是最消耗时间的.因为磁盘扫描涉及很多物理特性,这些是相当消耗时间的。所以B树设计的初衷是为了减少对于磁盘的扫描次数。如果一个表或索引没有使用B树(对于没有聚集索引的表是使用堆heap存储),那么查找一个数据,需要在整个表包含的数据库页中全盘扫描。这无疑会大大加重IO负担.而在SQL SERVER中使用B树进行存储,则仅仅需要将B树的根节点存入内存,经过几次查找后就可以找到存放所需数据的被叶子节点包含的页!进而避免的全盘扫描从而提高了性能.
下面,通过一个例子来证明:
在SQL SERVER中,表上如果没有建立聚集索引,则是按照堆(HEAP)存放的,假设我有这样一张表:
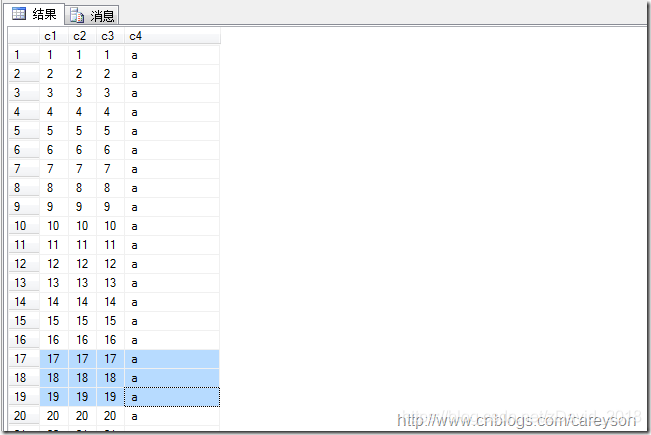
现在这张表上没有任何索引,也就是以堆存放,我通过在其上加上聚集索引(以B树存放)来展现对IO的减少:
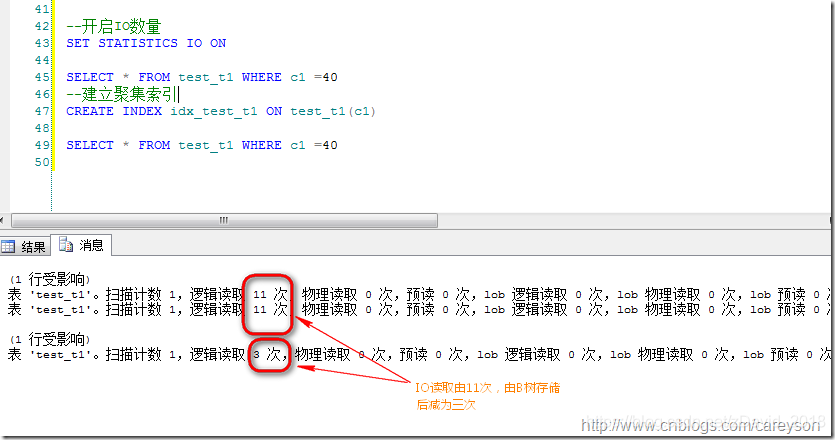
三、理解聚集索引和非聚集索引
在SQL SERVER中,最主要的两类索引是聚集索引和非聚集索引。可以看到,这两个分类是围绕聚集这个关键字进行的.那么首先要理解什么是聚集.
聚集在索引中的定义:
为了提高某个属性(或属性组)的查询速度,把这个或这些属性(称为聚集码)上具有相同值的元组集中存放在连续的物理块称为聚集。
简单来说,聚集索引就是:
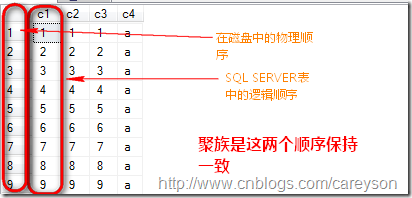
在SQL SERVER中,聚集的作用就是将某一列(或是多列)的物理顺序改变为和逻辑顺序相一致,比如,我从adventureworks数据库的employee中抽取5条数据:
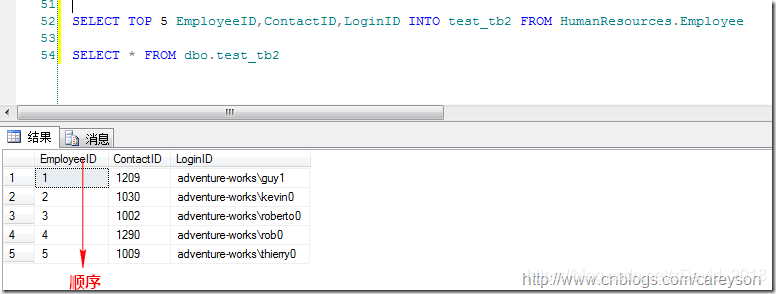
当我在ContactID上建立聚集索引时,再次查询:
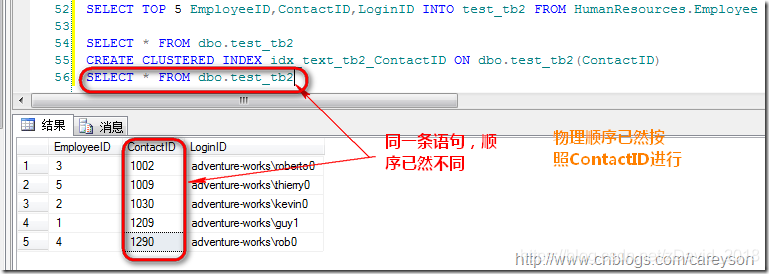
在SQL SERVER中,聚集索引的存储是以B树存储,B树的叶子直接存储聚集索引的数据:
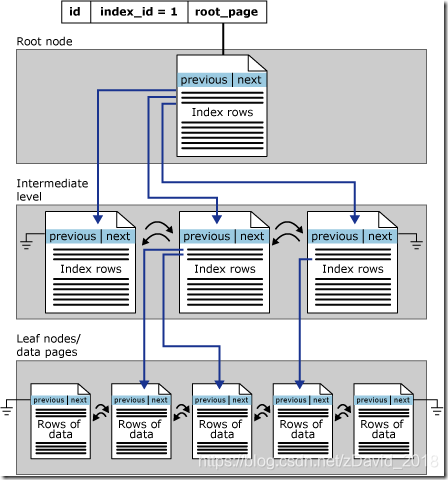
非聚集索引
因为每个表只能有一个聚集索引,如果我们对一个表的查询不仅仅限于在聚集索引上的字段。我们又对聚集索引列之外还有索引的要求,那么就需要非聚集索引了.
非聚集索引,本质上来说也是聚集索引的一种.非聚集索引并不改变其所在表的物理结构,而是额外生成一个聚集索引的B树结构,但叶子节点是对于其所在表的引用,这个引用分为两种,如果其所在表上没有聚集索引,则引用行号。如果其所在表上已经有了聚集索引,则引用聚集索引的页.
一个简单的非聚集索引概念如下:
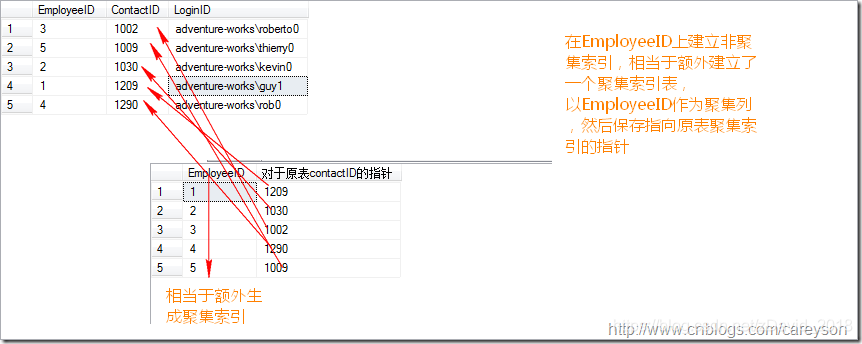
可以看到,非聚集索引需要额外的空间进行存储,按照被索引列进行聚集索引,并在B树的叶子节点包含指向非聚集索引所在表的指针.
MSDN中,对于非聚集索引描述图是:
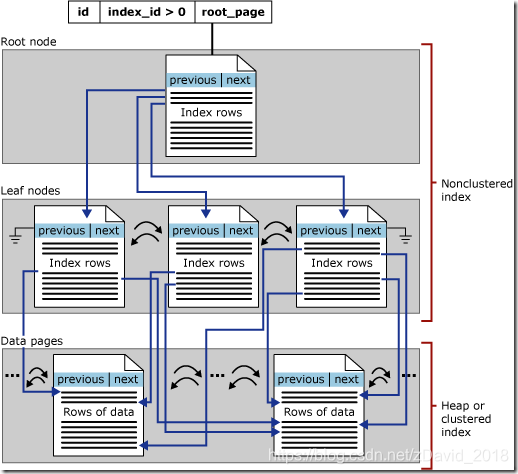
可以看到,非聚集索引也是一个B树结构,与聚集索引不同的是,B树的叶子节点存的是指向堆或聚集索引的指针.
通过非聚集索引的原理可以看出,如果其所在表的物理结构改变后,比如加上或是删除聚集索引,那么所有非聚集索引都需要被重建,这个对于性能的损耗是相当大的。所以最好要先建立聚集索引,再建立对应的非聚集索引.
因为聚集索引改变的是其所在表的物理存储顺序,所以每个表只能有一个聚集索引.
聚集索引 VS 非聚集索引
前面通过对于聚集索引和非聚集索引的原理解释.我们不难发现,大多数情况下,聚集索引的速度比非聚集索引要略快一些.因为聚集索引的B树叶子节点直接存储数据,而聚集索引还需要额外通过叶子节点的指针找到数据.
还有,对于大量连续数据查找,非聚集索引十分乏力,因为非聚集索引需要在非聚集索引的B树中找到每一行的指针,再去其所在表上找数据,性能因此会大打折扣.有时甚至不如不加非聚集索引.
因此,大多数情况下聚集索引都要快于非聚集索引。但聚集索引只能有一个,因此选对聚集索引所施加的列对于查询性能提升至关紧要.
四、数据库优化
此外,除了数据库索引之外,在LAMP结果如此流行的今天,数据库(尤其是MySQL)性能优化也是海量数据处理的一个热点。下面就结合自己的经验,聊一聊MySQL数据库优化的几个方面。
首先,在数据库设计的时候,要能够充分的利用索引带来的性能提升,至于如何建立索引,建立什么样的索引,在哪些字段上建立索引,上面已经讲的很清楚了,这里不在赘述。另外就是设计数据库的原则就是尽可能少的进行数据库写操作(插入,更新,删除等),查询越简单越好。
其次,配置缓存是必不可少的,配置缓存可以有效的降低数据库查询读取次数,从而缓解数据库服务器压力,达到优化的目的,一定程度上来讲,这算是一个“围魏救赵”的办法。可配置的缓存包括索引缓存(key_buffer),排序缓存(sort_buffer),查询缓存(query_buffer),表描述符缓存(table_cache)。
第三,切表,切表也是一种比较流行的数据库优化方法。分表包括两种方式:横向分表和纵向分表,其中,横向分表比较有使用意义,故名思议,横向切表就是指把记录分到不同的表中,而每条记录仍旧是完整的(纵向切表后每条记录是不完整的),例如原始表中有100条记录,我要切成2个表,那么最简单也是最常用的方法就是ID取摸切表法,本例中,就把ID为1,3,5,7。。。的记录存在一个表中,ID为2,4,6,8,。。。的记录存在另一张表中。虽然横向切表可以减少查询强度,但是它也破坏了原始表的完整性,如果该表的统计操作比较多,那么就不适合横向切表。横向切表有个非常典型的用法,就是用户数据:每个用户的用户数据一般都比较庞大,但是每个用户数据之间的关系不大,因此这里很适合横向切表。最后,要记住一句话就是:分表会造成查询的负担,因此在数据库设计之初,要想好是否真的适合切表的优化:
第四,日志分析,在数据库运行了较长一段时间以后,会积累大量的LOG日志,其实这里面的蕴涵的有用的信息量还是很大的。通过分析日志,可以找到系统性能的瓶颈,从而进一步寻找优化方案。
以上讲的都是单机MySQL的性能优化的一些经验,但是随着信息大爆炸,单机的数据库服务器已经不能满足我们的需求,于是,多多节点,分布式数据库网络出现了。

















 10万+
10万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









