




这里写目录标题
- 1.instanceOf什么时候会用到
- 2.对依赖注入的理解
- 3.递归查询和迭代查询
- 4.dns解析的详细过程
- 5.count(列名)与count(*)与count(1)
- 6.数据库关键字in和exist的特点和区别
- 7.HTTP里面有个keep alive,TCP信息里也有个keep alive
- 8.TCP三次握手
- 9.TCP四次挥手
- 10.慢查询优化
- 11.equals与==与hashcode
- 12.Spring Spring boot和Spring MVC
- 13.MySQL设计三范式
- 14.http协议报文的各部分内容
- 15.Spring cloud及其组件
- 16.聚簇索引
- 17.线程的状态
- 18.MyIsam和InnoDB的区别
- 19.Java中final、finally和finalize的区别
- 20.hashmap和hashtable
- 21.Spring boot事务
1.instanceOf什么时候会用到
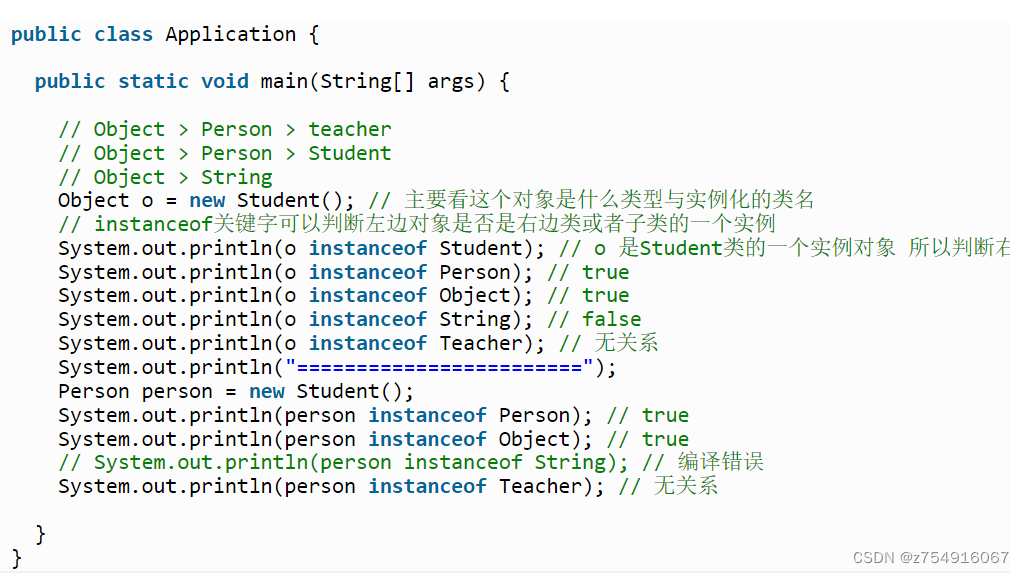
instanceof是Java中的二元运算符,左边是对象,右边是类;
当对象是右边类或子类所创建对象时,返回true;否则,返回false。
2.对依赖注入的理解
IoC的一个重点是在系统运行中,动态的向某个对象提供它所需要的其他对象。这一点是通过DI(Dependency Injection,依赖注入)来实现的。比如对象A需要操作数据库,以前我们总是要在A中自己编写代码来获得一个Connection对象,告诉依赖注入框架,A中需要一个Connection,至于这个Connection怎么构造,何时构造,A不需要知道。
在系统运行时,依赖注入框架会在适当的时候制造一个Connection,然后像打针一样,注射到A当中,这样就完成了对各个对象之间关系的控制。A需要依赖 Connection才能正常运行,而这个Connection是由依赖注入框架注入到A中的,依赖注入的名字就这么来的。
3.递归查询和迭代查询
递归查询: 如果 A 请求 B,那么 B 作为请求的接收者一定要给 A 想要的答案
迭代查询: 如果接收者 B 没有请求者 A 所需要的准确内容,接收者 B 将告诉请求者 A,如何去获得这个内容,但是自己并不去发出请求。
客户端向本地DNS服务器发出的查询过程是递归查询,这个查询是客户端以自己的名义向本地DNS服务器请求想要的IP映射,并且本地DNS服务器直接返回映射结果给到客户端。
后面的三次查询是迭代查询,包括:本地DNS服务器向根DNS服务器发送查询请求,本地DNS服务器向顶级域DNS服务器(TLD)发送查询请求,本地DNS服务器向权威DNS服务器发送查询请求,所有的请求都是由本地DNS服务器发出,所有响应都是直接返回给本地DNS服务器
4.dns解析的详细过程
- 输入URL,操作系统会先查hosts文件是否有记录,有的话就把相应映射的IP返回,没有就去本地DNS服务器,客户端发送一个DNS请求,并发送给本地DNS服务器(就是在客户端的TCP/IP设置中填写的DNS服务器地址)
- 本地域名服务器如果能在缓存中找到直接返回IP地址,如果没有则会去询问根域名服务器。根域名通过观察www.server.com告诉本地DNS服务器对应.com的顶级域DNS服务器的地址
- 本地DNS又去询问顶级域服务器,顶级域告诉本地服务器对应server.com的权威服务器的地址,权威服务器将查询后的IP地址告诉本地DNS
- 本地DNS再将IP地址返回客户端,客户端和目标建立连接。
5.count(列名)与count(*)与count(1)

6.数据库关键字in和exist的特点和区别
in 是把外表和内表作hash join,而exists是对外表作loop,每次loop再对内表进行查询。
如果两个表中一个较小,一个是大表,则子查询表大的用exists,子查询表小的用in:
7.HTTP里面有个keep alive,TCP信息里也有个keep alive
TCP的keepalive是侧重在保持客户端和服务端的连接,一方会不定期发送心跳包给另一方,当一方端掉的时候,没有断掉的定时发送几次心跳包,如果间隔发送几次,对方都返回的是RST,而不是ACK,那么就释放当前链接。设想一下,如果tcp层没有keepalive的机制,一旦一方断开连接却没有发送FIN给另外一方的话,那么另外一方会一直以为这个连接还是存活的,几天,几月。那么这对服务器资源的影响是很大的。
HTTP的keep-alive一般我们都会带上中间的横杠,主要功能是保活和复用。普通的http连接是客户端连接上服务端,然后结束请求后,由客户端或者服务端进行http连接的关闭。下次再发送请求的时候,客户端再发起一个连接,传送数据,关闭连接。这么个流程反复。但是一旦客户端发送connection:keep-alive头给服务端,且服务端也接受这个keep-alive的话,两边对上暗号,这个连接就可以复用了,一个http处理完之后,另外一个http数据直接从这个连接走了。减少新建和断开TCP连接的消耗。
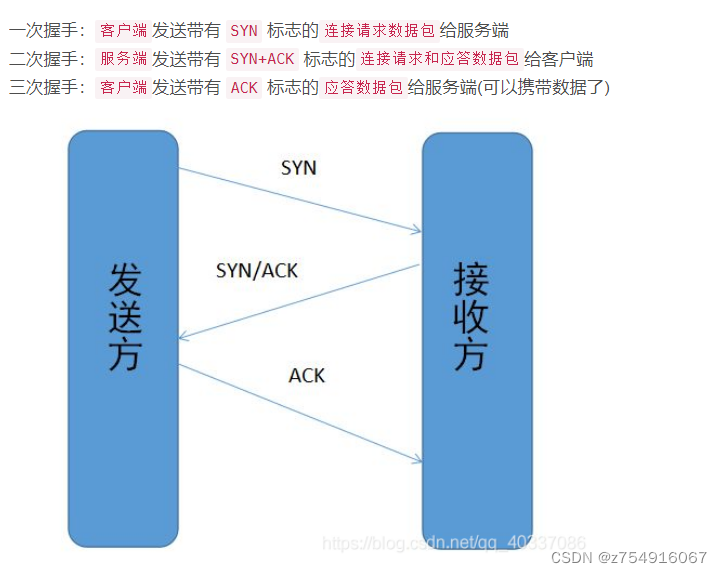
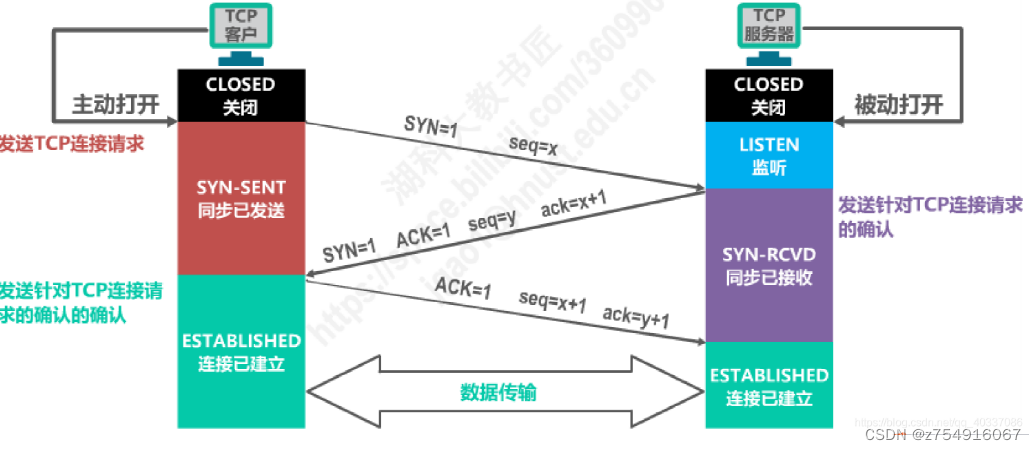
8.TCP三次握手
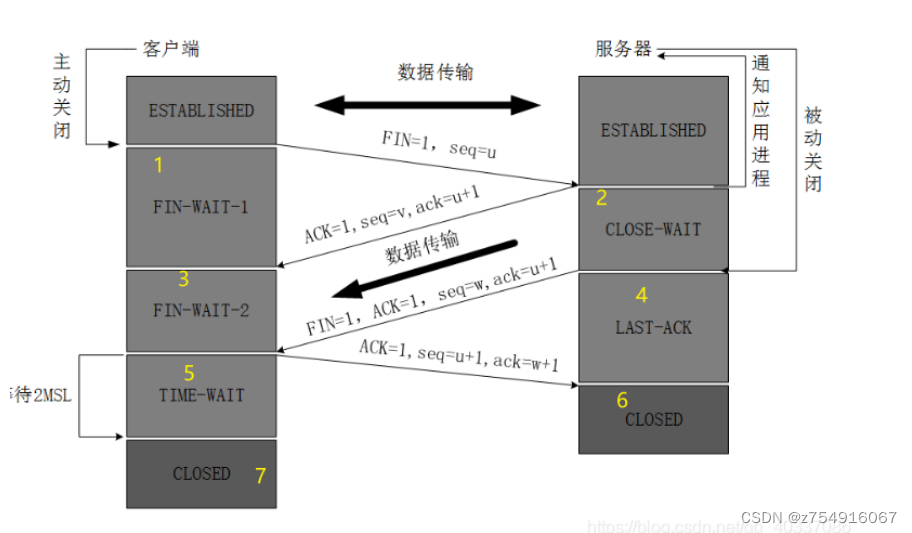
9.TCP四次挥手
10.慢查询优化
sql优化的场景应该是查询比较慢,首先做归因,可以用explain关键字查询到该sql的执行计划,比如该语句有无使用索引,有无做全表扫描等。
优化的方法就是1.避免进行全表扫描,可以在常用的where和order by涉及的列上做索引。2.避免使用in(使用exist替代) not in !=这些都会进行全表扫描。3.避免子查询,可以用连接查询。4.避免null,使用默认值代替null,否则也会进行全表扫描。
11.equals与==与hashcode
==:
对于基本类型是值比较,对于引用类型来说是引用比较。
equals:
equals是原始类Object的方法,即所有对象都有equals方法,默认情况下(即没有重写)是引用比较,但是JDK中类很多重写了equals方法(一般是先进行 =.= 比较,再判断是否要进行值比较),所以一般情况下是值比较。
注:基本类型不能使用equals比较,而是用 == ,因为基本类型没有equals方法.
hashcode():
hashcode()也是Object的方法,是一个本地方法,用C/C++语言实现的,由java去调用返回的对象的地址值。但JDK中很多类都对hashcode()进行了重写。比如Boolean的表示true则哈希值为1231,表示false则哈希值为1237,

12.Spring Spring boot和Spring MVC
spring是一个一站式的轻量级的java开发框架,核心是控制反转(IOC)和面向切面(AOP)
springMvc是spring基础之上的一个MVC框架,主要处理web开发的路径映射和视图渲染,是WEB开发的MVC框架,涵盖面包括前端视图开发、文件配置、后台接口逻辑开发等
springBoot框架相对于springMvc框架来说,更专注于开发微服务后台接口,不开发前端视图,同时遵循默认优于配置,简化了插件配置流程,不需要配置xml,相对springmvc,大大简化了配置流程;
13.MySQL设计三范式
1、第一范式
要求任何一张表必须有主键,每一个字段原子性不可再分。【最核心最重要的范式】
2、第二范式
建立在第一范式的基础上,要求所有非主键字段完全依赖主键,不要产生部分依赖。
3、第三范式
建立在第二范式的基础之上,要求所有非主键字段直接依赖主键,不要产生传递依赖。
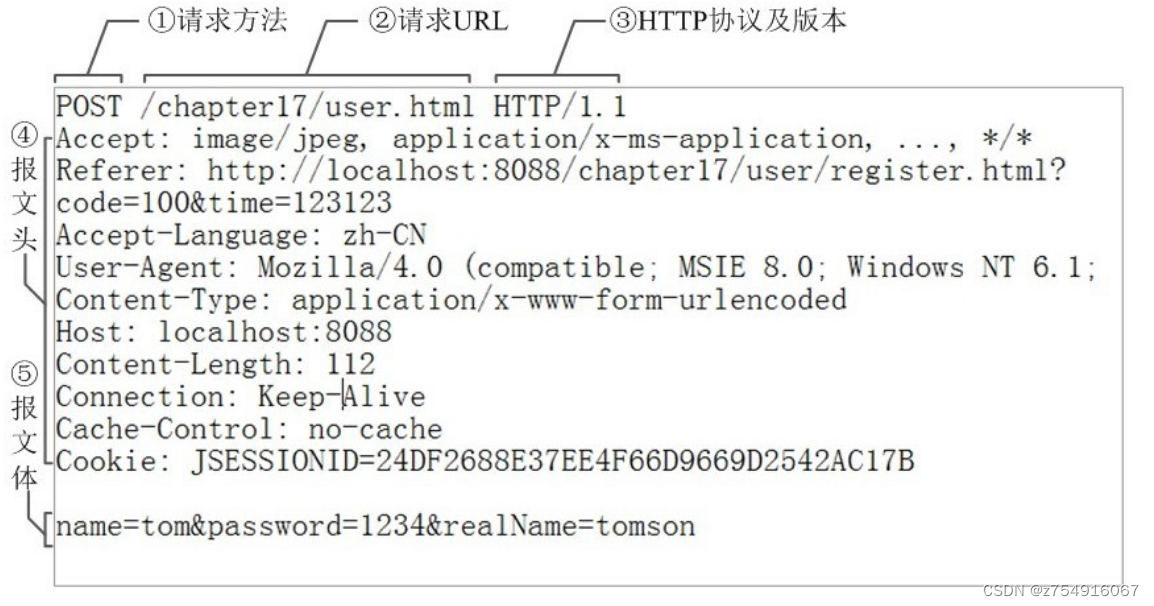
14.http协议报文的各部分内容
请求报文由四个部分组成:
请求行:包括请求方法、请求 URL、HTTP 协议和版本
请求头:一些键值对
空行:请求头之后是一个空行,通知服务器以下不再有请求头、空行后面的内容是请求体
请求体:数据部分,GET没有请求数据,POST有
响应报文由四个部分组成:
状态行:HTTP协议和版本、状态码、状态描述
响应头
空行
响应体

15.Spring cloud及其组件
16.聚簇索引
聚集索引:指索引项的排序方式和表中数据记录排序方式一致的索引。聚簇索引并不是一种单独的索引类型,而是一种数据存储方式。术语“聚簇”表示数据行和相邻的键值紧凑的存储在一起。
也就是说聚集索引的顺序就是数据的物理存储顺序。它会根据聚集索引键的顺序来存储表中的数据,即对表的数据按索引键的顺序进行排序,然后重新存储到磁盘上。因为数据在物理存放时只能有一种排列方式,所以一个表只能有一个聚集索引。
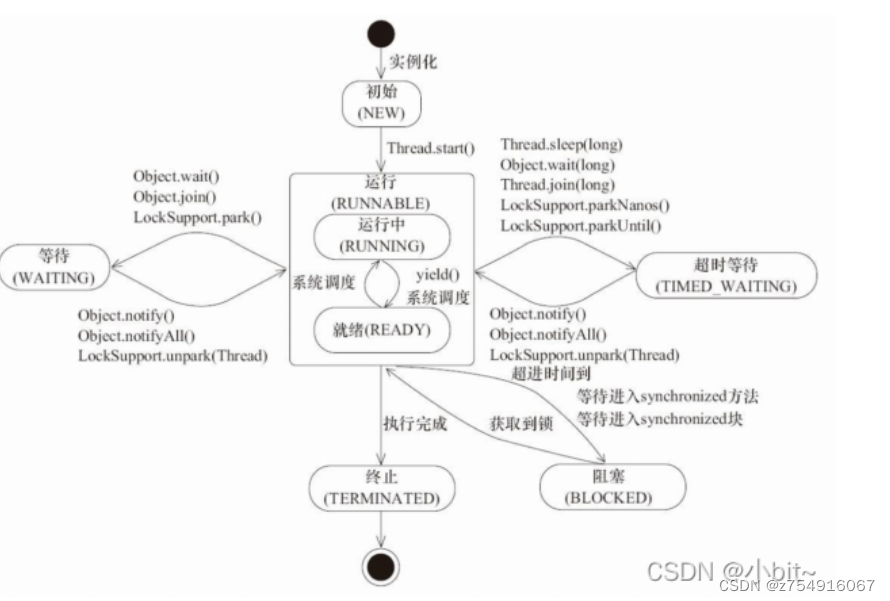
17.线程的状态
-
New 新建状态(线程刚被创建,start方法之前的状态)
-
Runnable 运行状态(得到时间片运行中状态)(Ready就绪,未得到时间片就绪状态)
-
Blocked 阻塞状态(如果遇到锁,线程就会变为阻塞状态等待另一个线程释放锁)
比如线程A进入了一个synchronized方法,线程B也想进入这个方法,但是这个方法的锁已经被线程A获取了,这个时候线程B就处于BLOCKED状态 -
Waiting 等待状态(无限期等待)
-
Time_Waiting 超时等待状态(有明确结束时间的等待状态)
-
Terminated 终止状态(当线程结束完成之后就会变成此状态)
18.MyIsam和InnoDB的区别
-
InnoDB支持事务,MyISAM不支持,对于InnoDB每一条SQL语言都默认封装成事务,自动提交,这样会影响速度,所以最好把多条SQL语言放在begin和commit之间,组成一个事务;
-
InnoDB支持外键,而MyISAM不支持。对一个包含外键的InnoDB表转为MYISAM会失败;
-
InnoDB是聚集索引,使用B+Tree作为索引结构,数据文件是和(主键)索引绑在一起的(表数据文件本身就是按B+Tree组织的一个索引结构),必须要有主键,通过主键索引效率很高。但是辅助索引需要两次查询,先查询到主键,然后再通过主键查询到数据。因此,主键不应该过大,因为主键太大,其他索引也都会很大。
19.Java中final、finally和finalize的区别

20.hashmap和hashtable
相同点:hashmap和Hashtable都实现了map、Cloneable(可克隆)、Serializable(可序列化)这三个接口
不同:1.Hashtable是线程安全的也是synchronized,HashMap不安全(concurrentHashMap),所以HashMap效率也高于Hashtable。 2.hashTable的key和value不支持NULL,而hashMap是支持的。3.hashTable的初始长度是11,hashMap的初值是16,且负载因子都是0.75 ,hashTable的扩容是两倍+1 ,hashMap的扩容是两倍。
21.Spring boot事务
@Transactional 是SpringBoot开启事务的注解,可以用于修饰方法或类,被修饰的方法和类将默认开启数据库事务。
在加注解的类中,我们对同一数据表的增删改查就成了原子性的了。假设我们对三个表执行删除操作,假设有一个删除失败,则另外执行成功的删除操作也会回到未删除之前的状态。

















 7610
7610

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









