




 本文通过使用sklearn库创建一个包含1000个样本、10个特征的数据集,并采用10折交叉验证的方式训练并评估了三种不同的机器学习算法:高斯朴素贝叶斯、支持向量机及随机森林。主要关注模型的准确性、F1得分及AUC等性能指标。
本文通过使用sklearn库创建一个包含1000个样本、10个特征的数据集,并采用10折交叉验证的方式训练并评估了三种不同的机器学习算法:高斯朴素贝叶斯、支持向量机及随机森林。主要关注模型的准确性、F1得分及AUC等性能指标。
sklearn
题目

解题过程
1. Create a classification dataset (n samples 1000, n features 10)

2. Split the dataset using 10-fold cross validation
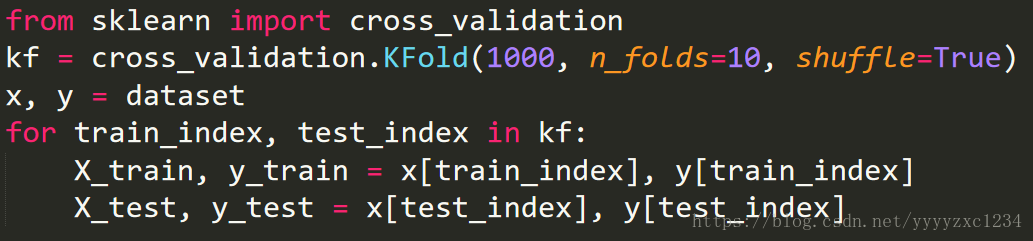
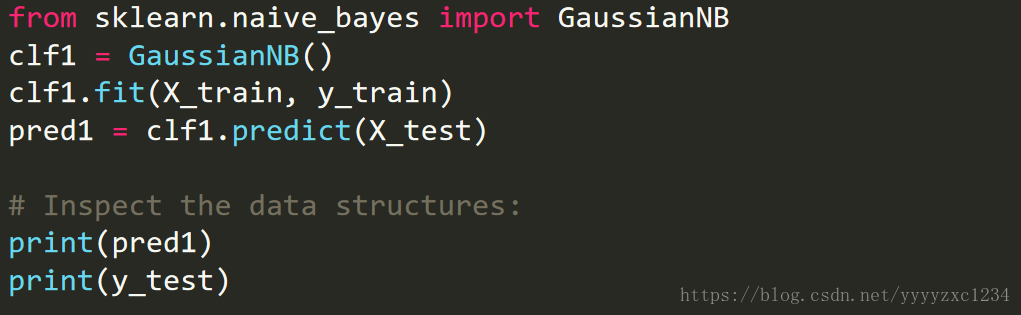
3. Train the algorithms
GaussianNB

SVC (possible C values [1e-02, 1e-01, 1e00, 1e01, 1e02], RBF kernel)


RandomForestClassifier (possible n estimators values [10, 100, 1000])
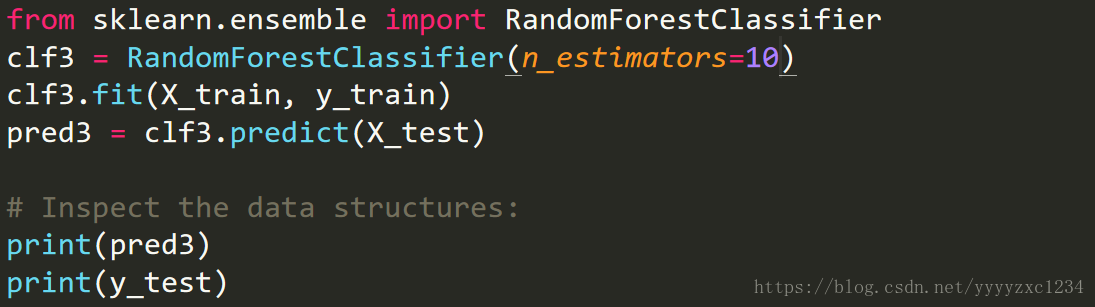

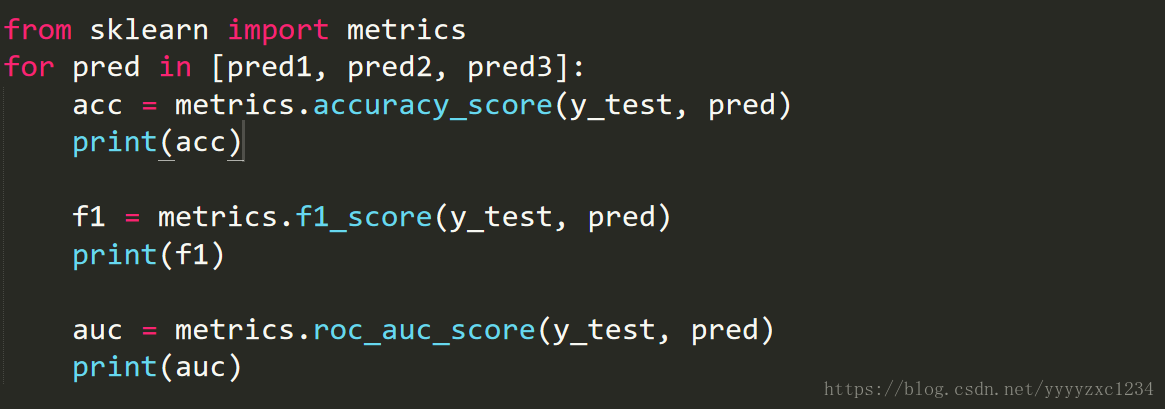
4. Evaluate the cross-validated performance
- Accuracy
- F1-score
- AUC
- ROC



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









