




湖南大学2018-2019秋季学期专业任选《机器学习》课程项目(20190104)
任务说明
提供2000张标注了的车辆场景分类信息的高分辨率图片,请使用这些数据,建立并训练模型,并将此模型运用于测试数据集的图像分类标注。
提示
该题目主要考核各位同学使用较小的模型和小规模的训练数据下的模型设计和训练的能力。需要同学充分利用迁移学习等方法,以解决训练数据少的问题,同时需要思考和解决深度学习中过拟合的问题。所提供的场景定义为比较单一的车辆场景,一定程度上平衡了难度系数。
标签信息
0,巴士,bus
1,出租车,taxi
2,货车,truck
3,家用轿车,family sedan
4,面包车,minibus
5,吉普车,jeep
6,运动型多功能车,SUV
7,重型货车,heavy truck
8,赛车,racing car
9,消防车,fire engine
数据集下载
链接:https://pan.baidu.com/s/1COLohBbj1Z8VFANMqLYoQg
密码:653r
训练模型构建过程(基于Keras库)
本次实验中采用的深度学习模型主要是卷积神经网络,卷积神经网络的原理如下:
卷积层:
图中不同颜色的神经元对不同区域进行取样,但其权值矩阵是共享的,即使用相同的一组权值在图像的不同区域进行采样,以提取特定的特征,通过增加卷积核的个数,能够增加提取的特征种类,利用这种方法可以大量减少需要训练的参数,并且也能对图像的特征进行有效的提取。
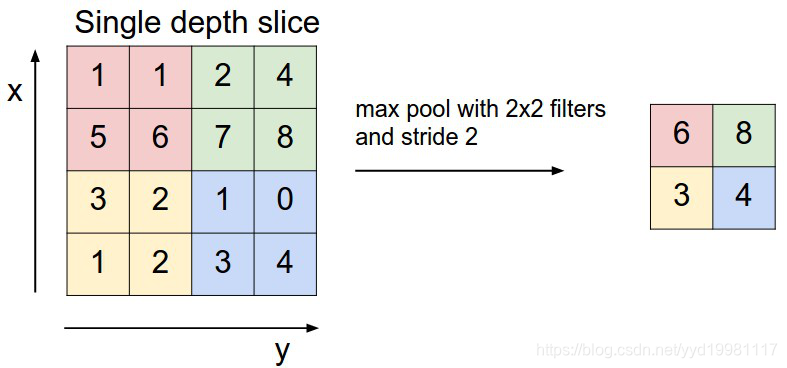
池化层:(上图为最大值池化的示意图)
池化操作实际上是对数据规模的一个压缩的过程,经过卷积后得到的特征图包括很多特征值,由于卷积的范围一般会有交叉覆盖,实际上一些相邻的特征值是可以舍去的,池化层就是在一个较小的范围内将数据进行压缩,常见的有最大值池化,均值池化等,本次实验中使用的池化均为最大值池化。
为了避免梯度弥散,本次实验使用的激活函数均为Relu函数,在每层卷积层之后还添加了规范化层和dropout层,规范化层的作用是将输入作规整化处理,使输出的均值趋向1,方差趋向0。Dropout层的作用是令输入神经元以给定的概率失效(变为0),这样每次训练的时候可以随机屏蔽掉一部分神经元,从而防止过拟合现象的产生
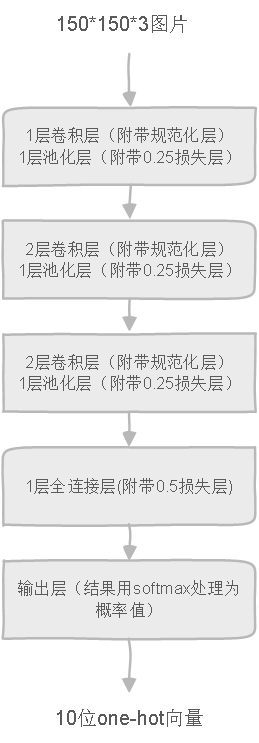
本次实验的网络结构图如下:
先通过数次卷积提取特征,再经过全连接层到输出层,做softmax处理。转化为one-hot向量输出。
模型构建代码
# In[6]:
# 搭建神经网络模型
chanDim = -1
model = Sequential()
'''
添加一层卷积层
卷积核的数目:32
卷积核的宽度:3
卷积核的长度:3
激活函数:relu(线性整流函数f(x) = max(0, x))
输入规模:之前给定的
'''
model 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 545
545

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









