




 本文分析了BERT的340M参数训练策略,涉及单字替换、NextSentencePrediction等技术。讨论了BERT在不同任务中的应用,如预训练和GPT的生成预测。关注点在于seq_to_seq模型的损坏修复和词向量的实际应用。
本文分析了BERT的340M参数训练策略,涉及单字替换、NextSentencePrediction等技术。讨论了BERT在不同任务中的应用,如预训练和GPT的生成预测。关注点在于seq_to_seq模型的损坏修复和词向量的实际应用。
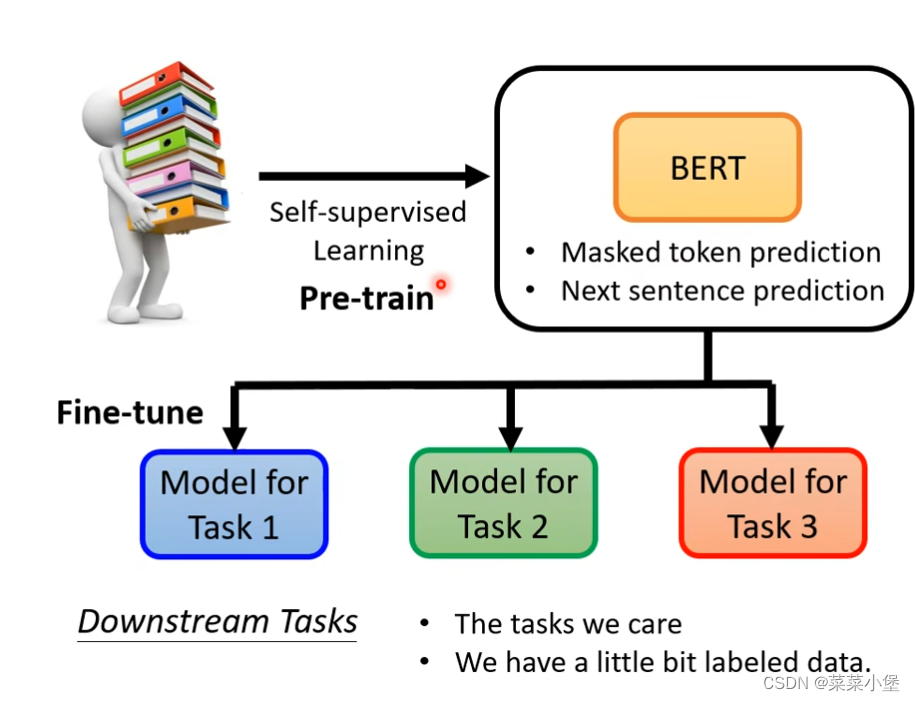
Self-Supervised Learning
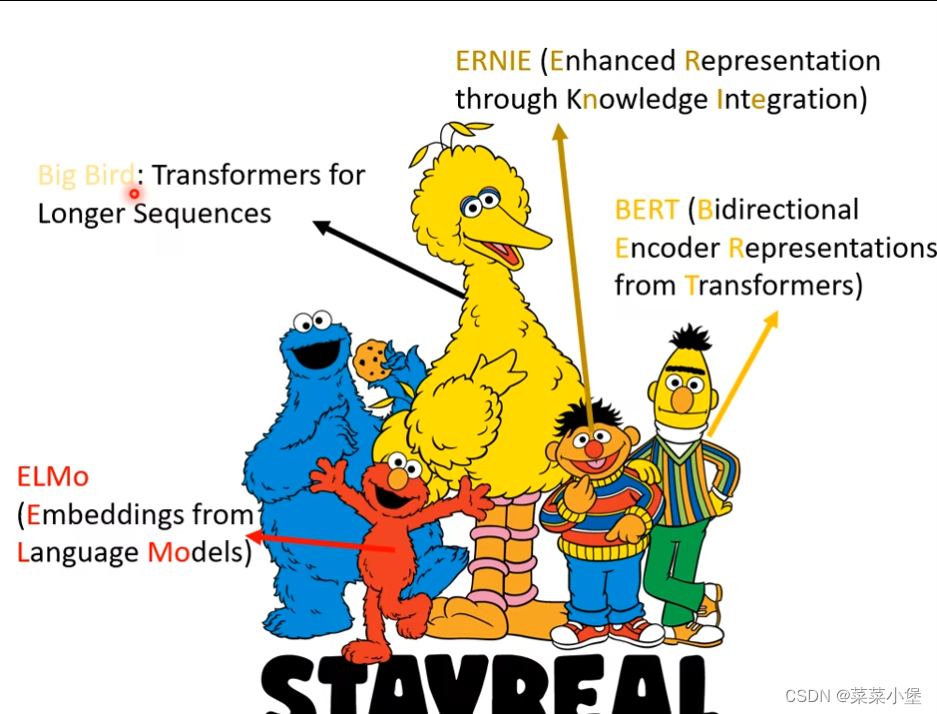
Bert 的数据是 340M parameters

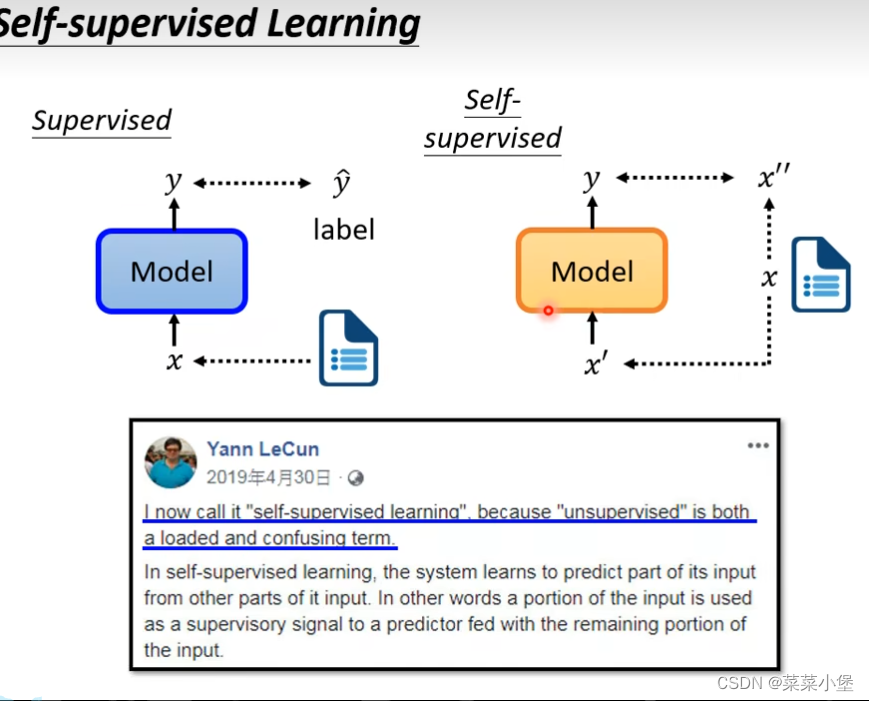
抽象解释👆
Bert
实现参考思路读懂bert
单个字的预测
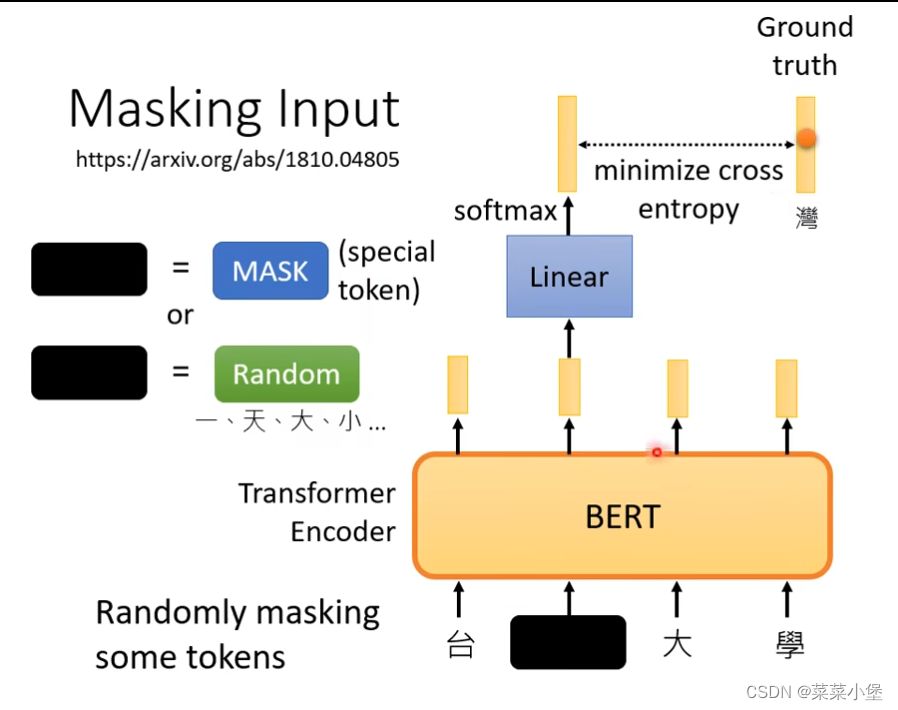
把一个字盖住:
1、把一个字替换成特殊字符(MASK)。
2、替换成随机的一个字,进行训练。
next sentence prediction
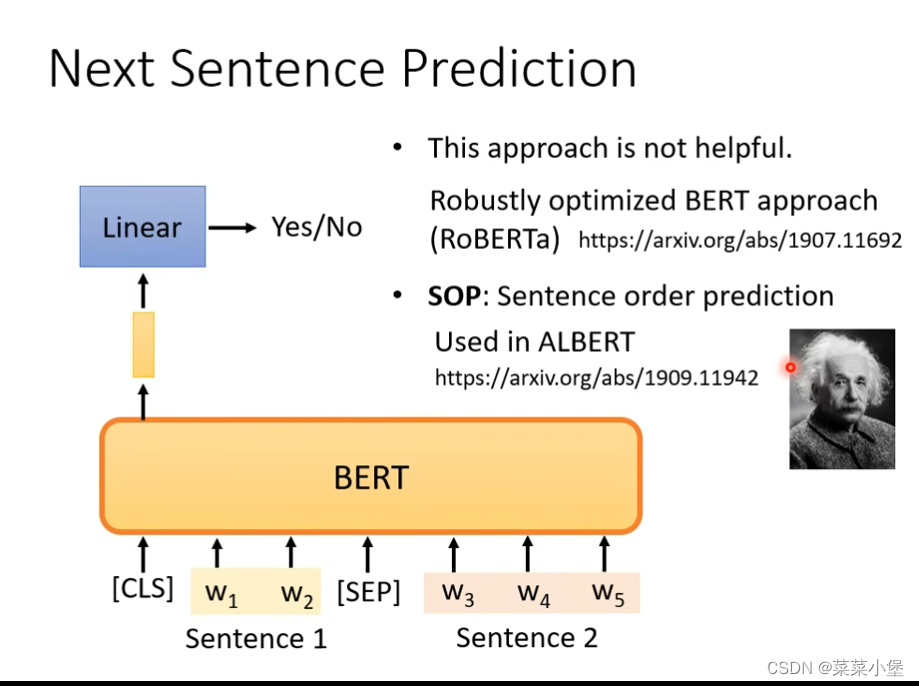
通过变换两个连起来的句子的顺序,或者加符号来训练。
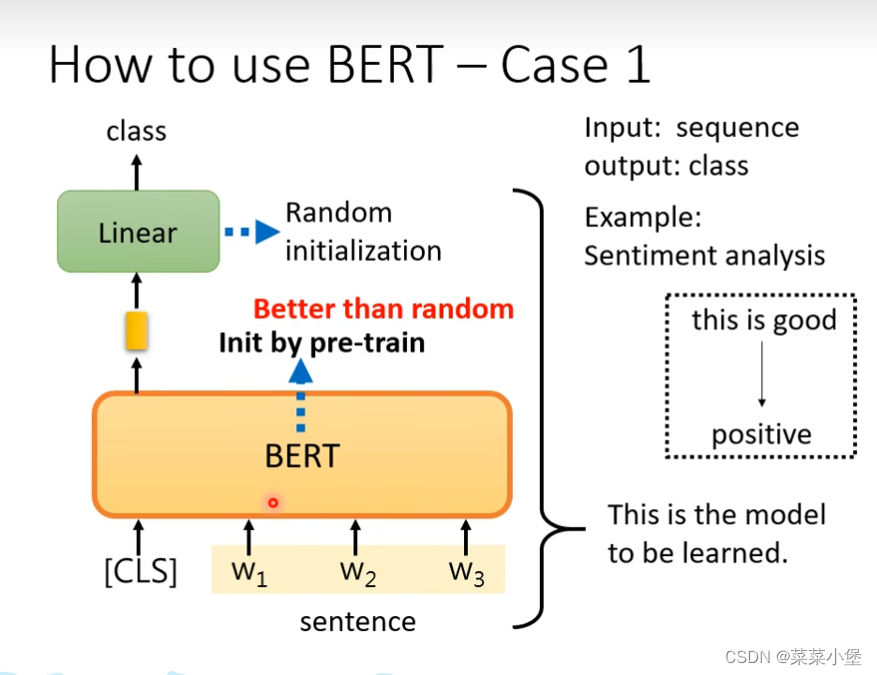
case1用做填空的bert(训练好的模型)做pre-train(下面的case2 3 4 也是用填空获得的bert来做的),用来训练新的分类。
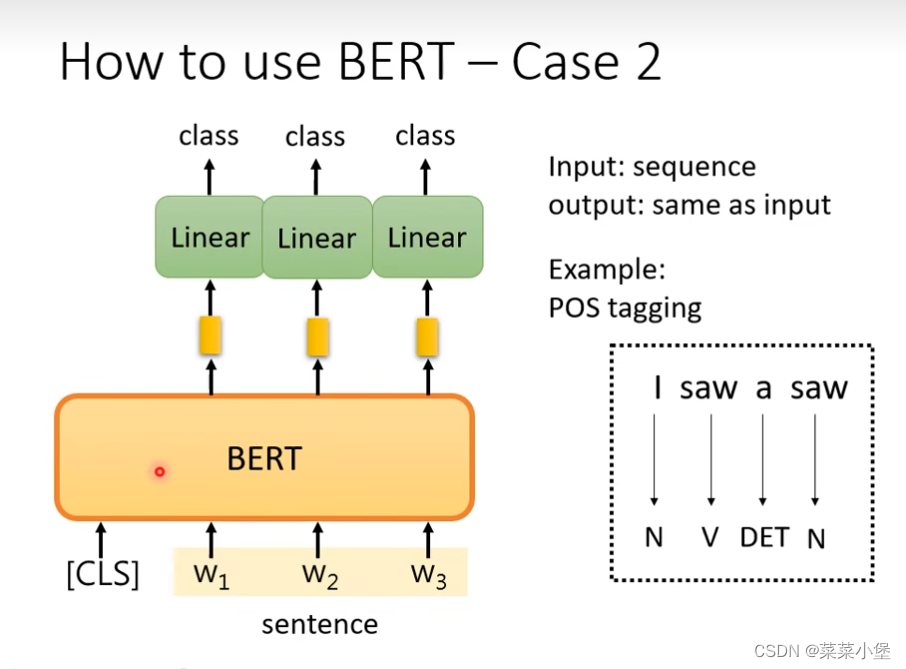
case2 也是做初始化的pre-train的问题
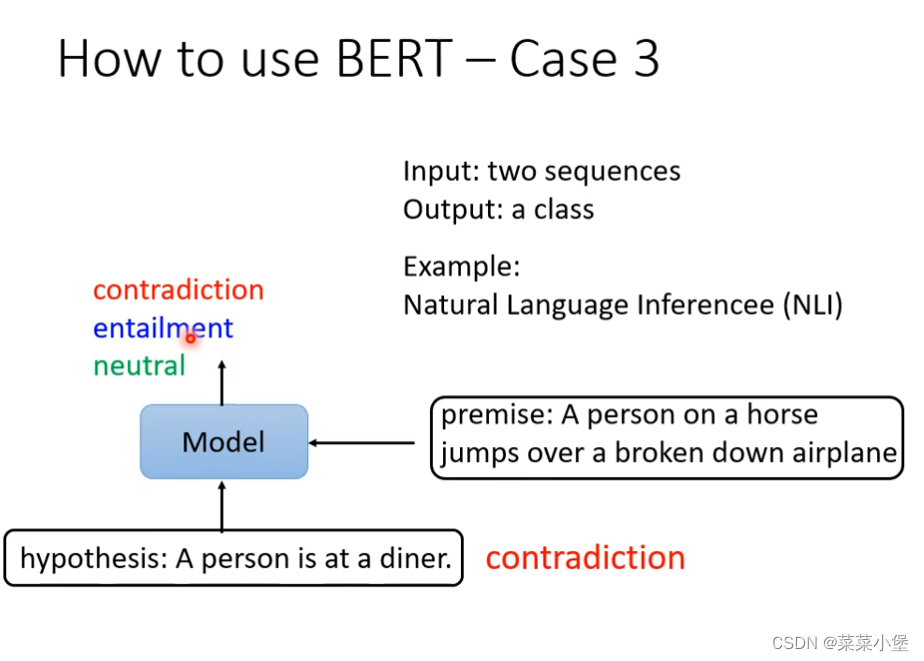
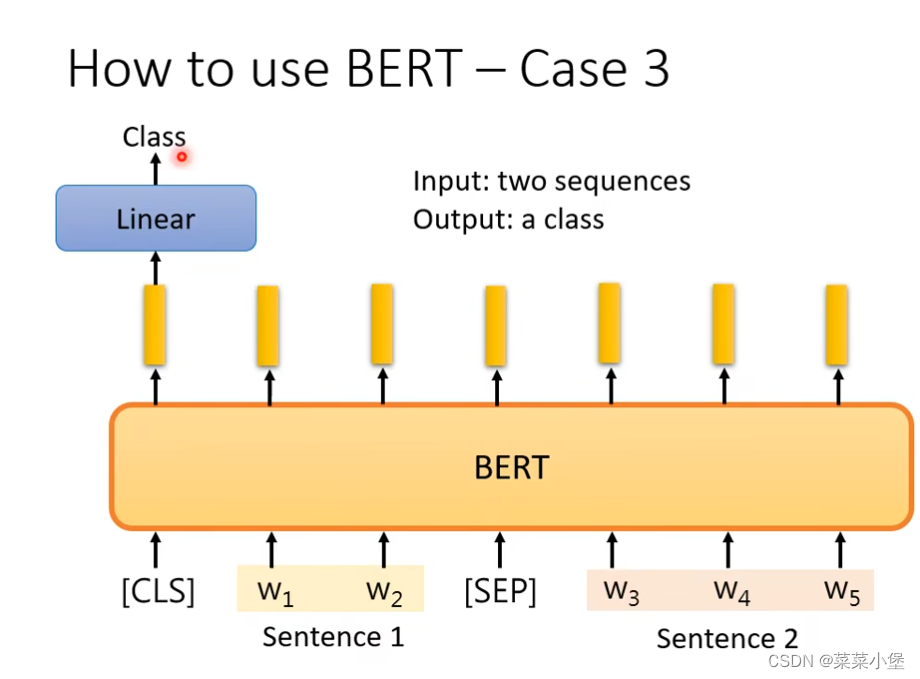
case3是给两个句子 判断两个句子之间的关系(矛盾、蕴含、对立)

给两个文段D、Q通过训练得到两个整数s、e答案就是原文D中第s到第e个词组。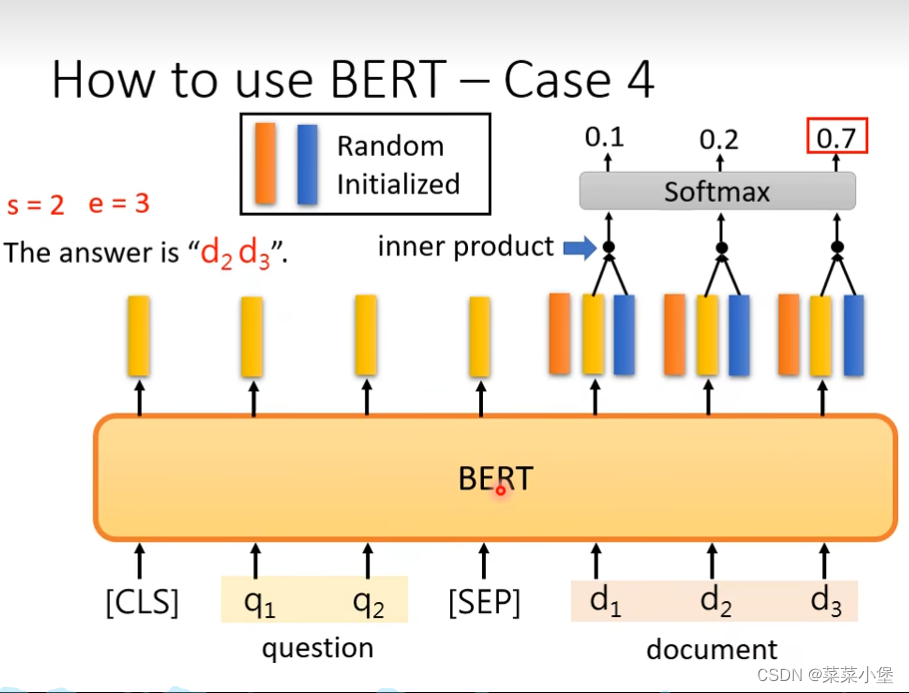
上图中 通过
1、橙色的向量和黄色的内积+softmax获得的是answer的开始位置。
2、蓝色的向量和黄色的内积+softmax获得的是answer的结束的位置。
其中黄色的向量是bert中pre-train获得的向量,而橙色和蓝色是随机初始化后得到的向量。
所以这种训练模式需要一定的训练数据来完成对于橙色和蓝色的向量的训练。
bert胚胎学👆可以进行详细研究。
回归我们需要的研究方向👇,seq_to_seq方向
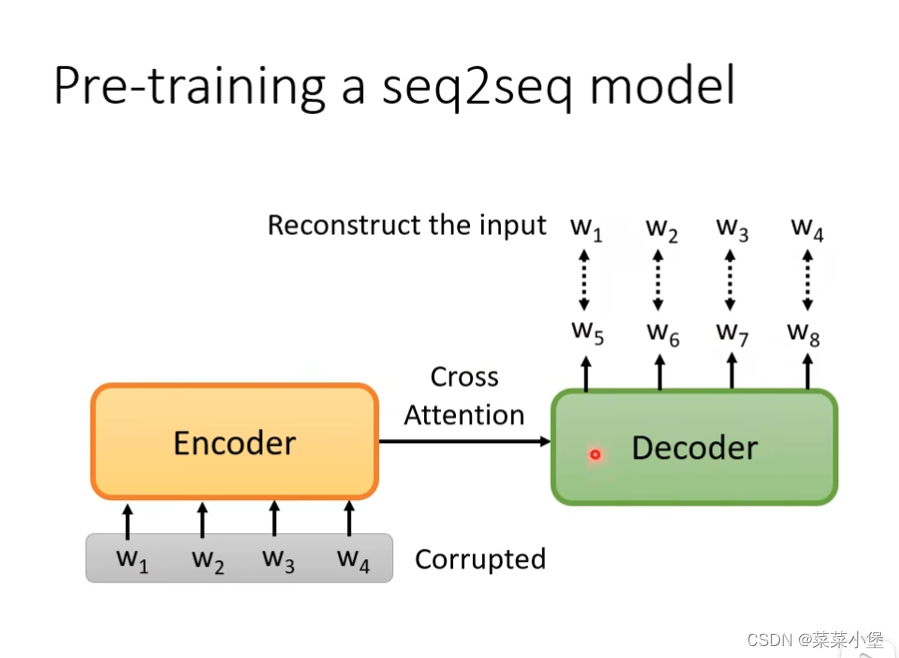
这里要做到的是把w1,w2·····损坏(mass)之后,也要输出对的w5,w6·····值。
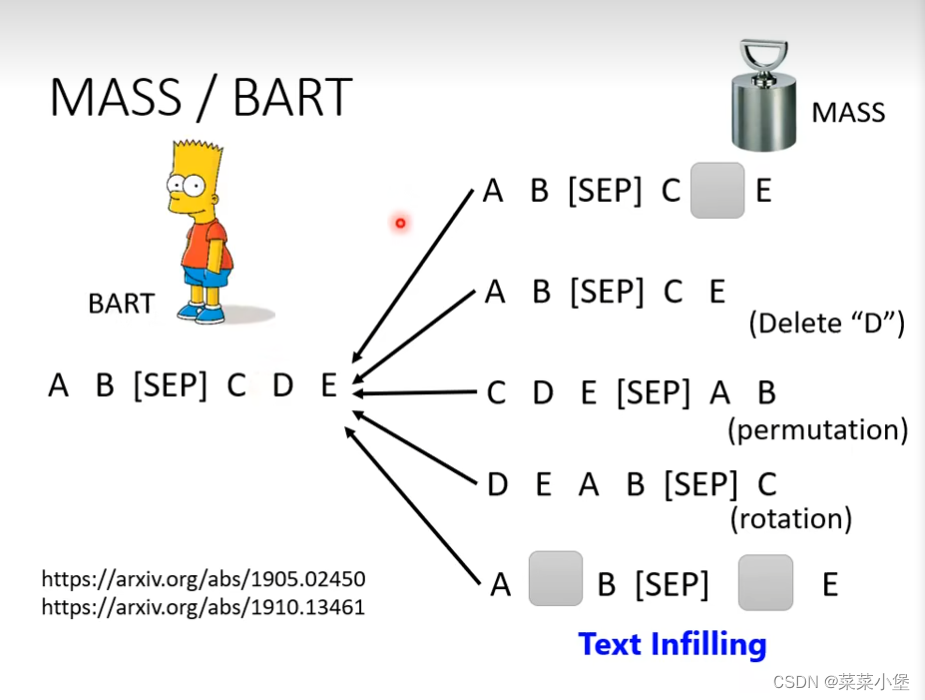
👆就是各种损坏(mass)的方法。
以‘果’为例子感受bert的词向量的应用状态
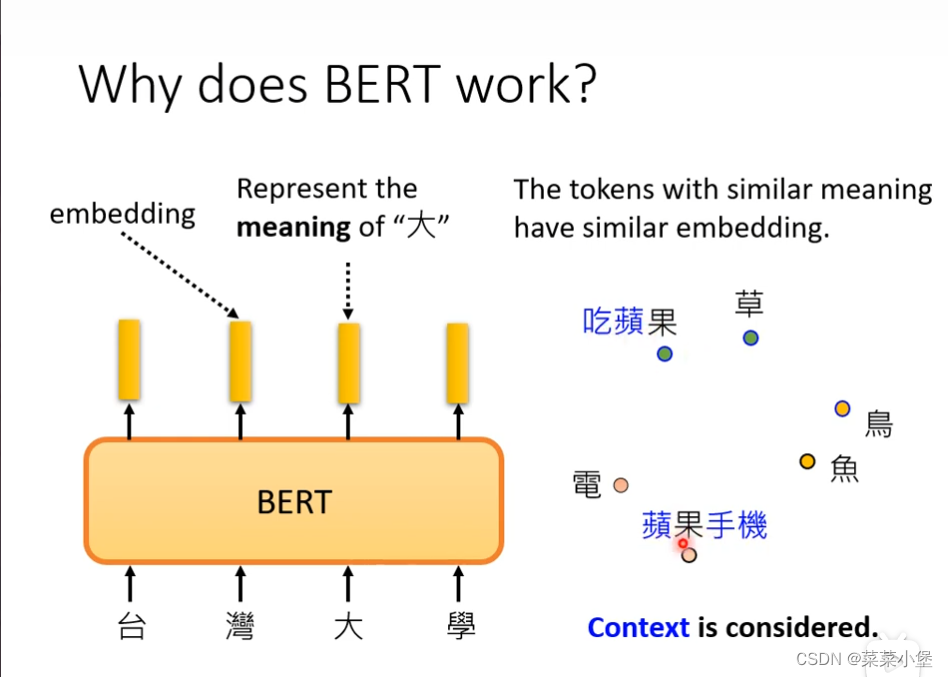
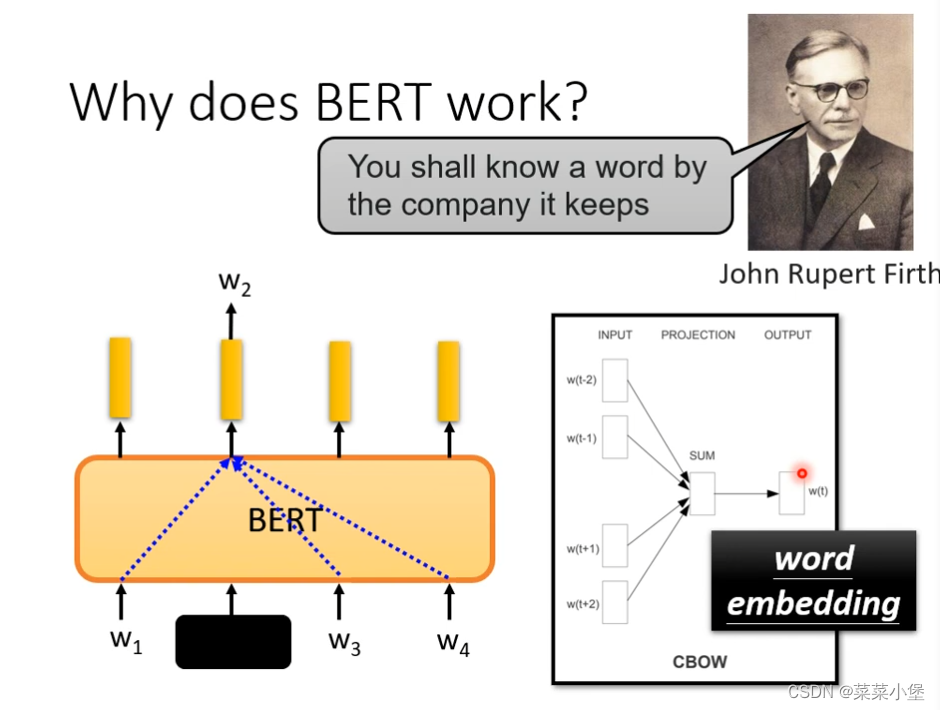
word embedding通过被masked单词的上下文就可以进行预测。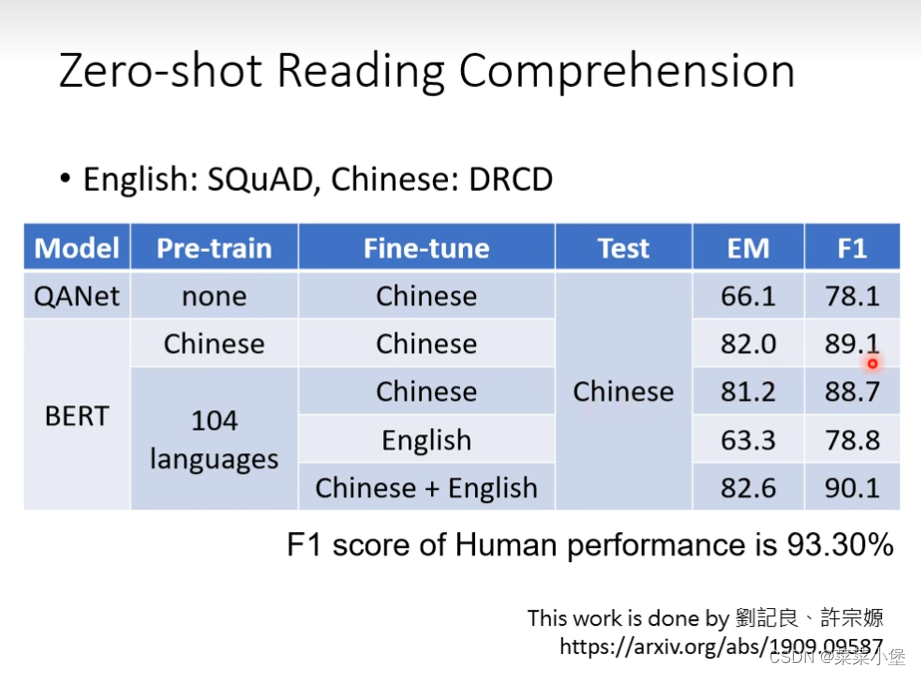
把bert的英文QA问题训练好之后,放到中文去(pre-train)模型,居然有78的正确率,bert的预训练模型非常神奇。
bert其实一直做的是填空题
GPT模型
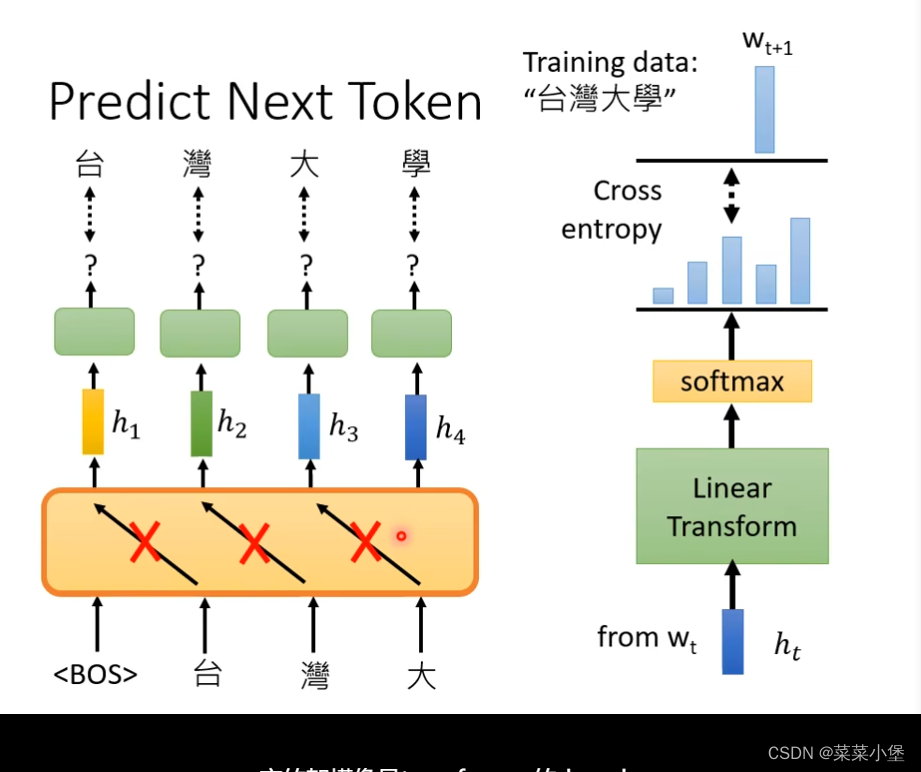
像是transformer的decoder

GPT做的东西是 给上一段文字,输出预测下一段,👆这种例子,居然可以翻译cheese!这就是GPT做的大模型的预测问题。


















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









