






 本文详细介绍了在Flink实时数仓项目中,如何设计和实现订单宽表功能,包括订单表和订单明细表的双流Join,以及针对维度表的优化策略。优化主要包括使用旁路缓存(Redis)和异步查询以提升性能,确保数据一致性和处理效率。
本文详细介绍了在Flink实时数仓项目中,如何设计和实现订单宽表功能,包括订单表和订单明细表的双流Join,以及针对维度表的优化策略。优化主要包括使用旁路缓存(Redis)和异步查询以提升性能,确保数据一致性和处理效率。
Flink实时数仓项目—DWD层设计与实现
前言
前面已经完成了两个功能,下面实现订单宽表的功能,比较复杂,所以单独列出来。
一、功能三:订单宽表
1.需求描述
订单在电商中属于比较重要的分析对象,关于订单也有许多的维度统计需求,比如用户、地区、商品、品类、品牌等等。
为了方便以后的统计,减少表的关联,所以提前在DWM层将订单相关的数据整合成一张订单的宽表。
2.需求分析
首先,要思考到底要将哪些数据和订单整合在一起?
订单表和订单明细表具有非常强烈的关联关系,这是两张事实表,这两张表中还有一些维度外键,所以还需要整合这些维度表,如下图:
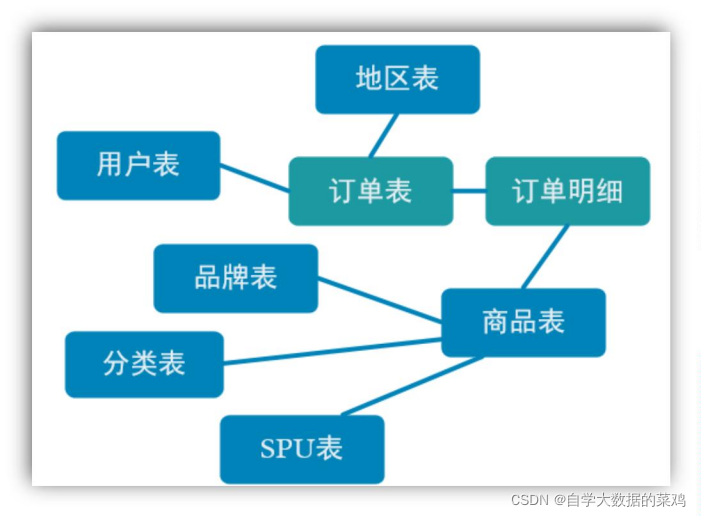
上图中,订单表和订单明细表属于事实数据,它们存放在Kafka的DWD相关主题中。地区表、用户表、品牌表、分类表、SPU表和商品表属于维度数据,它们存放在HBase中。
从上面可以看出来,我们总共需要做两件事:
1)将两张事实表关联起来(实际上就是流与流之间的关联)
2)将事实表关联后的数据跟维度表关联起来(实际上就是流计算中去HBase中查询相关的数据)
3.思路分析与代码实现
3.1 实体类的创建
我们从Kafka中读取出来订单表和订单明细表的数据需要用一个类型来接受,如果还用JSON对象来处理,就比较麻烦,所以为这两个表分别创建一个对应的实体类。
同时,订单表关联形成的宽表也需要建一个对应的实体类。
订单表实体类如下:
因为后面要提取时间戳生成水位线,所以为了方便起见,在实体类中增加了一个时间戳字段
@Data
public class OrderInfo {
//订单id
Long id;
//订单省份id
Long province_id;
//订单状态
String order_status;
//用户的id
Long user_id;
//实付总金额
BigDecimal total_amount;
//活动减免金额
BigDecimal activity_reduce_amount;
//优惠券减免金额
BigDecimal coupon_reduce_amount;
//原始总金额
BigDecimal original_total_amount;
//运输费用
BigDecimal feight_fee;
//到期时间
String expire_time;
//创建时间,格式为 yyyy-MM-dd HH:mm:ss
String create_time;
//修改时间
String operate_time;
//创建日期(通过创建时间格式化得到,格式为:yyyy-MM-dd)
String create_date; // 把其他字段处理得到
//创建的小时
String create_hour;
//时间戳,方便提取时间戳生成水位线
Long create_ts;
}
订单明细表实体类如下:
同理,有一个时间戳字段
@Data
public class OrderDetail {
//明细id
Long id;
//订单id
Long order_id;
//商品id
Long sku_id;
//该订单项总价格
BigDecimal order_price;
//商品数量
Long sku_num;
//商品名称
String sku_name;
//创建时间
String create_time;
//分摊的优惠总金额
BigDecimal split_total_amount;
//分摊的活动优惠金额
BigDecimal split_activity_amount;
//分摊的优惠券优惠金额
BigDecimal split_coupon_amount;
//时间戳,方便提取水位线
Long create_ts;
}
订单宽表实体类如下:
//订单宽表需要订单表、订单明细表以及一些维度表中的数据
@Data
@AllArgsConstructor
public class OrderWide {
//从订单表提取出来的字段,一般都是id
Long detail_id;
Long order_id;
Long sku_id;
BigDecimal order_price;
Long sku_num;
String sku_name;
Long province_id;
String order_status;
Long user_id;
//跟金额有关的字段
BigDecimal total_amount;
BigDecimal activity_reduce_amount;
BigDecimal coupon_reduce_amount;
BigDecimal original_total_amount;
BigDecimal feight_fee;
BigDecimal split_feight_fee;
BigDecimal split_activity_amount;
BigDecimal split_coupon_amount;
BigDecimal split_total_amount;
//跟时间有关的字段
String expire_time;
String create_time; //yyyy-MM-dd HH:mm:ss
String operate_time;
String create_date; // 把其他字段处理得到
String create_hour;
//跟省份有关,属于维度信息
String province_name;//查询维表得到
String province_area_code;
String province_iso_code;
String province_3166_2_code;
//跟用户有关
Integer user_age;
String user_gender;
//sku的维度信息
Long spu_id; //作为维度数据 要关联进来
Long tm_id;
Long category3_id;
String spu_name;
String tm_name;
String category3_name;
//特殊的构造函数,传入订单表对象和订单明细表对象,先把实时表中的字段给填充进去
public OrderWide(OrderInfo orderInfo, OrderDetail orderDetail) {
mergeOrderInfo(orderInfo);
mergeOrderDetail(orderDetail);
}
public void mergeOrderInfo(OrderInfo orderInfo) {
if (orderInfo != null) {
this.order_id = orderInfo.id;
this.order_status = orderInfo.order_status;
this.create_time = orderInfo.create_time;
this.create_date = orderInfo.create_date;
this.create_hour = orderInfo.create_hour;
this.activity_reduce_amount = orderInfo.activity_reduce_amount;
this.coupon_reduce_amount = orderInfo.coupon_reduce_amount;
this.original_total_amount = orderInfo.original_total_amount;
this.feight_fee = orderInfo.feight_fee;
this.total_amount = orderInfo.total_amount;
this.province_id = orderInfo.province_id;
this.user_id = orderInfo.user_id;
}
}
public void mergeOrderDetail(OrderDetail orderDetail) {
if (orderDetail != null) {
this.detail_id = orderDetail.id;
this.sku_id = orderDetail.sku_id;
this.sku_name = orderDetail.sku_name;
this.order_price = orderDetail.order_price;
this.sku_num = orderDetail.sku_num;
this.split_activity_amount = orderDetail.split_activity_amount;
this.split_coupon_amount = orderDetail.split_coupon_amount;
this.split_total_amount = orderDetail.split_total_amount;
}
}
}
3.2 读取Kafka订单数据和订单明细数据
读取Kafka的订单数据的和订单明细数据,因为数据可能发生乱序,而间隔连结支持处理时间语义的乱序,所以在读取时提取数据的时间戳并生成水位线,方便处理乱序数据。
//2、读取Kafka的数据 转换为JavaBean对象并提取时间戳
String orderInfoSourceTopic = "dwd_order_info";
String orderDetailSourceTopic = "dwd_order_detail";
String orderWideSinkTopic = "dwm_order_wide";
String groupId = "order_wide_group";
//读取Kafka中订单主题的数据
SingleOutputStreamOperator<OrderInfo> orderInfoDS = env.addSource(MyKafkaUtil.getKafkaSource(orderInfoSourceTopic, groupId))
.map(data -> {
OrderInfo orderInfo = JSON.parseObject(data, OrderInfo.class);
//获取创建时间,它的格式为yyyy-MM-dd HH:mm:ss
String create_time = orderInfo.getCreate_time();
String[] fields = create_time.split(" ");
//获取yyyy-MM-dd部分
orderInfo.setCreate_date(fields[0]);
//获取HH部分
orderInfo.setCreate_hour(fields[1].split(":")[0]);
//将创建时间格式化为时间戳
SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd");
orderInfo.setCreate_ts(simpleDateFormat.parse(create_time).getTime());
return orderInfo;
}).assignTimestampsAndWatermarks(WatermarkStrategy.<OrderInfo>forMonotonousTimestamps()
.withTimestampAssigner(new SerializableTimestampAssigner<OrderInfo>() {
@Override
public long extractTimestamp(OrderInfo orderInfo, long l) {
return orderInfo.getCreate_ts();
}
}));
//读取订单明细主题的数据
SingleOutputStreamOperator<OrderDetail> orderDetailDS = env.addSource(MyKafkaUtil.getKafkaSource(orderDetailSourceTopic, groupId))
.map(data -> {
OrderDetail orderDetail = JSON.parseObject(data, OrderDetail.class);
String create_time = orderDetail.getCreate_time();
//将创建时间格式化为时间戳
SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd");
orderDetail.setCreate_ts(simpleDateFormat.parse(create_time).getTime());
return orderDetail;
}).assignTimestampsAndWatermarks(WatermarkStrategy.<OrderDetail>forMonotonousTimestamps()
.withTimestampAssigner(new SerializableTimestampAssigner<OrderDetail>() {
@Override
public long extractTimestamp(OrderDetail orderDetail, long l) {
return orderDetail.getCreate_ts();
}
}));
3.3 双流Join—关联事实表
在获得了订单流和订单明细流之后,我们要通过订单表的id字段和订单明细里的order_id字段进行连结,这样才能形成一张宽表。
这里选择使用间隔连结的方式,因为如果使用窗口的话,很容易发生对应数据不在一个窗口的情况。比如一个订单数据在A窗口的结束的前1s,它对应的订单项数据在A窗口下一个窗口开始的前1s,这就发生了错位。而间隔连结是根据一个数据看这个数据的前后一段时间内有没有匹配的数据,很明显,这样的方式更有保证。
使用间隔连结,时间设置为前后5s,最后生成的是缺少了维度数据的订单宽表,代码如下:
//3、进行双流join,采用连结join
//先把订单表和订单明细表进行连结,获取需要的事实表的字段,维度表以后再连结
SingleOutputStreamOperator<OrderWide> orderWideDS = orderInfoDS.keyBy(data -> data.getId())
.intervalJoin(orderDetailDS.keyBy(data -> data.getOrder_id()))
.between(Time.seconds(-5), Time.seconds(5)) //生产环境中给最大延迟时间
.process(new ProcessJoinFunction<OrderInfo, OrderDetail, OrderWide>() {
@Override
public void processElement(OrderInfo orderInfo, OrderDetail orderDetail, ProcessJoinFunction<OrderInfo, OrderDetail, OrderWide>.Context context, Collector<OrderWide> collector) throws Exception {
collector.collect(new OrderWide(orderInfo, orderDetail));
}
});
3.4 关联维度表
维度数据存放在HBase中,我们可以通过Phoenix来查询唯独数据。因为我们这里就总共需要查询6张维度表,如果我们一张维度表写一个查询的方法,那就需要写6个,通用性太差,因此可以进行封装。
这里对Phoenix的查询进行了封装,参数只需要查询语句、返回值类型即可,这样可以返回一个泛型的集合,不管是查询单条结果还是多条结果都是可以的,代码如下:
public class PhoenixUtil {
private static Connection connection;
static {
try {
//建立connection的连接
Class.forName(GmallConfig.PHOENIX_DRIVER);
connection= DriverManager.getConnection(GmallConfig.PHOENIX_SERVER);
} catch (ClassNotFoundException | SQLException e) {
e.printStackTrace();
}
}
public static <T> List<T> queryList(String sql,Class<T> cls) throws SQLException, InstantiationException, IllegalAccessException, InvocationTargetException {
//创建一个返回结果的集合
ArrayList<T> result = new ArrayList<>();
//直接去查询sql
PreparedStatement preparedStatement = connection.prepareStatement(sql);
ResultSet resultSet = preparedStatement.executeQuery();
//获取元数据信息,即列名
ResultSetMetaData metaData = resultSet.getMetaData();
//获取列的个数
int columnCount = metaData.getColumnCount();
while(resultSet.next()){
//创建泛型对象
T t = cls.newInstance();
//获取对应的列名和列值,并依次添加到泛型对象中去
for (int i = 1; i < columnCount + 1; i++) {
BeanUtils.setProperty(t,metaData.getColumnName(i),resultSet.getObject(i));
}
//将泛型对象放到结果集合中
result.add(t);
}
preparedStatement.close();
return result;
}
}
同时,在维度连接中,因为六张表的查询语句只有表名和id不同,所以,可以对sql的拼接也进行一个封装,代码如下:
public class DimUtil {
//需要查询6张维度表,查询之间的不同只有表名和id不同,所以只需要传递这两个参数即可
public static JSONObject getSingleDimInfo(String tableName,String id) throws SQLException, InvocationTargetException, InstantiationException, IllegalAccessException {
//在这里拼接查询语句
//一个sql语句例子:select * from db.tn where id='18'
String query="select * from "+ GmallConfig.HBASE_SCHEMA+"."+tableName+" where id='"+id+"'";
List<JSONObject> queryList = PhoenixUtil.queryList(query, JSONObject.class);
//这里是返回一个对象,所以获取第一个结果即可
return queryList.get(0);
}
}
二、优化:关联维度表优化—旁路缓存
1.旁路缓存选型
在3.4中是直接用Phoenix查询的HBase,HBase这种外部数据源的查询从表面上来看是比较快的,但是实际上在大数据中如果遇到了大量数据的查询,可能会遇到性能瓶颈,产生背压,所以需要在这种查询的基础上进行一定的优化,例如使用旁路缓存。
使用旁路缓存后,任何请求优先访问缓存,缓存命中,直接获得数据返回请求。如果请求未命中,就查询数据库,同时把结果写入缓存以备后续请求使用。
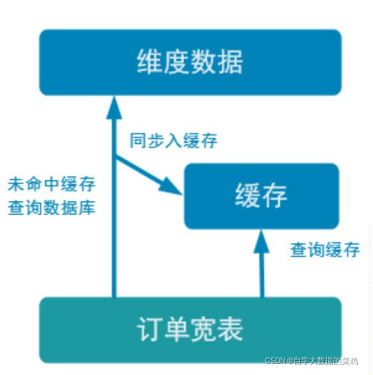
1)使用缓存要注意的地方:
缓存要设置过期时间,不然冷数据会常驻缓存,浪费资源。
要考虑维度数据是否会发生变化,如果发生变化要主动清除缓存。保证数据一致性。
2)缓存的选型:
堆缓存:性能更好,因为存放在堆内存中,访问数据的路径更短,减少过程消耗。但是管理性差,其他进程无法维护缓存中的数据。一个例子就是在代码中加一个Map的数据结构,id作为key,它对应的数据作为value,这样如果多个业务要访问同样的数据,就需要建立多个缓存,因为一个缓存只能让一个进程访问。
独立缓存服务(redis、memcache):性能也还不错,但是会有创建连接、网络IO等消耗。但是如果数据会发生变化,很明显独立缓存服务管理性更强,而且如果数据量特别大,独立缓存更容易扩展(可以搭建集群)。
结合本项目场景,因为维度数据是可变数据,同时某些维度数据量也不小,所以采用Redis管理缓存。
2.Redis设计
1)Redis中要存放什么类型的数据?
我们使用Phoenix从HBase中查询出来的数据用JSONObject封装了起来,但是存放到Redis时不能使用这个格式,要使用toString方法转化为String类型。
2)采用什么数据结构以及它的Key怎么设计?
String类型:key为tableName+id
Set类型:Key为tableName
Hash类型:Key为tableName,value中的key为id
综合起来看,首先,set是不行的,通过set的key,没办法直接获取到对应id的数据,需要遍历tableName对应的所有数据才能找到想要的数据。
相比之下,String类型和Hash类型都能快速的找到对应的数据。但是之前提到了一个问题:有些数据可能长时间不用,那么这就需要设置过期时间,对于set和hash来讲只能根据redis的key即tableName来进行设置,这样一次就把一个表的所有数据都清空了,可能会出现雪崩的现象,因此Hash也不合适。
同时,Redis是可以进行扩展集群的,一个Hash对应的key的数据放在一台服务器里。如果一个Hash里的数据量过大,或者说它是热点数据,那么就需要经常性的访问这个服务器,这个服务器的压力就会过大。而String类型就不会出现这种情况。
综上,数据结构选择String类型,key为tableName+id
3.代码实现
使用Redis做缓存有以下几个步骤:
1)首先,在通过Phoenix查询HBase维度信息前,先在Redis中查询,查询到了就直接返回,查询不到,就去HBase中查询,然后将结果写入Redis中,代码如下:
//需要查询6张维度表,查询之间的不同只有表名和id不同,所以只需要传递这两个参数即可
public static JSONObject getSingleDimInfo(String tableName,String id) throws SQLException, InvocationTargetException, InstantiationException, IllegalAccessException {
//在HBase中查询前,先在redis中查询
Jedis jedis=RedisUtil.getJedis();
String redisKey="DIM:"+tableName+":"+id;
String dimInfoJsonStr = jedis.get(redisKey);
//如果查询到了,说明redis中有,直接返回即可
if(dimInfoJsonStr!=null){
//归还连接
jedis.close();
//重新设置失效时间
jedis.expire(redisKey,24*60*60);
return JSON.parseObject(dimInfoJsonStr);
}
//在这里拼接查询语句
//一个sql语句例子:select * from db.tn where id='18'
String query="select * from "+ GmallConfig.HBASE_SCHEMA+"."+tableName+" where id='"+id+"'";
List<JSONObject> queryList = PhoenixUtil.queryList(query, JSONObject.class);
//到这里表示redis中不存在要查询的数据,那么就把查询到的数据保存到Redis中
jedis.set(redisKey,queryList.get(0).toString());
//同样需要设置失效时间
jedis.expire(redisKey,24*60*60);
//这里是返回一个对象,所以获取第一个结果即可
return queryList.get(0);
}
2)在Flink-CDC读取MySQL表中的维度数据的时候,如果操作类型为update类型,那么就发生了修改。为了保证数据一致性,需要在Redis中删除对应的数据,代码如下:
//在维度数据发生变化的时候,需要在Redis中删除对应key的数据
public static void delRedisDimInfo(String tableName,String id){
Jedis jedis=RedisUtil.getJedis();
String redisKey="DIM:"+tableName+":"+id;
jedis.del(redisKey);
jedis.close();
}
上面代码要放到DimSinkFunction类里面的invoke方法中,invoke负责执行upsert语句,即可能插入也可能修改,所以需要判断。
//如果更新了维度数据,就删除Redis中对应key的数据
if("update".equals(value.getString("operation"))){
//Phoenix中表名是大写
//即使redis中保存的数据超时了不存在了,进行删除也不会报错
DimUtil.delRedisDimInfo(value.getString("sinkTable").toUpperCase(),value.getJSONObject("after").getString("id"));
}
需要注意:Redis中还需要设置过期时间,但是这里过期时间的设置,在读取时需要重置,因为读取数据就代表数据的热度高,以后可能还会用,所以在读取时需要重置数据过期时间为24小时。
三、优化:关联维度表优化—异步查询
1.优化原因
在Flink流处理中,可能经常需要与外部系统进行交互,去关联维度表补全事实表的字段。例如,在电商场景中用订单宽表中的sku_id去关联商品的一些属性等。
默认情况下,Flink的mapFunction中,数据是一条一条处理的,对于一条订单宽表的信息,需要等它关联完它所需的所有的6个维度表后,返回了结果,才能去处理下一条数据,这是一种同步的方式,往往在网络等待上就耗费了大量的时间。一种解决办法是增加MapFunction的并行度,但这会消耗更多的资源。
2.优化方法
在Flink1.2中引入了Async I/O,这是一种异步的方式,单个MapFunction可以发送多个请求,哪个请求先返回就先处理,所以多个连续的请求间不需要阻塞式等待,大大提高了流处理效率。
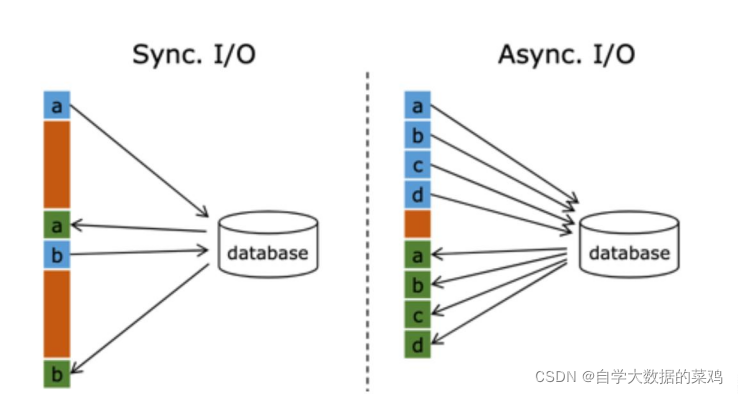
这种异步的方式实际上是把维度表的查询操作托管给单独的线程池完成,这样不会因为某一个查询造成阻塞,单个并行可以连续发送多个请求,提高并发效率。
3.代码实现
1)使用异步IO的方式有两种,一种是支持异步IO的数据库,一种是使用线程池的方式,这里使用线程池的方式,首先创建一个线程池,代码如下:
public class ThreadPoolUtil {
//声明线程池
public static ThreadPoolExecutor pool;
public ThreadPoolUtil() {
}
//单例对象
public static ThreadPoolExecutor getInstance(){
if(pool==null){
//锁住,防止创建多个
synchronized (ThreadPoolUtil.class){
if(pool==null){
/*
获取单例的线程池对象
corePoolSize:指定了线程池中的线程数量,它的数量决定了添加的任务是开辟新的线程
去执行,还是放到 workQueue 任务队列中去;
maximumPoolSize:指定了线程池中的最大线程数量,这个参数会根据你使用的
workQueue 任务队列的类型,决定线程池会开辟的最大线程数量;
keepAliveTime:当线程池中空闲线程数量超过 corePoolSize 时,多余的线程会在多长时间
内被销毁;
unit:keepAliveTime 的单位
workQueue:任务队列,被添加到线程池中,但尚未被执行的任务
*/
pool=new ThreadPoolExecutor(4,20,300L, TimeUnit.SECONDS,new LinkedBlockingDeque<Runnable>(Integer.MAX_VALUE));
}
}
}
return pool;
}
}
在创建的时候要加上锁,因为可能有多个进程访问,所以为了防止创建多个,使用加锁+二次判断的方式创建线程池。
2)继承RichAsyncFunction类,在生命周期open方法中初始化连接池,在asyncInvoke方法中发送请求并处理,代码如下:
public abstract class DimAsyncFunction<T> extends RichAsyncFunction<T,T> {
//自定义线程池对象
private ThreadPoolExecutor threadPoolExecutor;
private String tableName;
public DimAsyncFunction(String tableName) {
this.tableName = tableName;
}
@Override
public void open(Configuration parameters) throws Exception {
//初始化线程池,一个并行度要一个线程池就够了
threadPoolExecutor= ThreadPoolUtil.getInstance();
}
@Override
public void close() throws Exception {
super.close();
}
@Override
public void asyncInvoke(T t, ResultFuture<T> resultFuture) throws Exception {
//这个方法用于异步发送请求
threadPoolExecutor.submit(new Runnable() {
@SneakyThrows
@Override
public void run() {
//获取要查询的表的id
String id = getKey(t);
//去维度表查询维度信息
JSONObject singleDimInfo = DimUtil.getSingleDimInfo(tableName, id);
//关联维度表,补充维度信息
if(singleDimInfo!=null){
joinData(singleDimInfo,t);
}
//将数据输出
resultFuture.complete(Collections.singletonList(t));
}
});
}
//每次关联需要填充的字段不一样,所以也写一个抽象方法,具体使用时再实现
protected abstract void joinData(JSONObject singleDimInfo, T t);
@Override
public void timeout(T input, ResultFuture<T> resultFuture) throws Exception {
//对于查询响应时间超时的数据,直接打印一下算了
System.out.println("响应时间超时:"+input);
}
//因为针对不同的维度表,要获取的对应的id也不一样,所以写成抽象方法,在关联不同维度表时自己去实现
public abstract String getKey(T t);
}
我们关联6次维度信息,每次关联的表名不一样,要查询的id也不一样,所以需要这两个参数,表名在我们指定关联哪个维度的时候就可以当参数传进入,但是id没有办法从流中的数据拿到,还是需要根据关联哪张表获取哪张表的id,所以在类中定义了抽象方法,在具体实现的时候再去实现获取id的方法;查询出来的数据如何放到orderwide中?思路也是一样的,因为每个维度要填充的内容不同,所以也定义抽象方法,在具体要关联某张表的时候再去实现。
3)关联维度表
//4、进行维度表的关联
//关联用户维度表
SingleOutputStreamOperator<OrderWide> orderWideWithUserDS = AsyncDataStream.unorderedWait(orderWideDS,
new DimAsyncFunction<OrderWide>("DIM_USER_INFO") {
@Override
protected void joinData(JSONObject singleDimInfo, OrderWide orderWide) {
//这里是关联用户维度,所以填充对应的用户信息即可
orderWide.setUser_age(singleDimInfo.getInteger("AGE"));
orderWide.setUser_gender(singleDimInfo.getString("GENDER"));
}
@Override
public String getKey(OrderWide orderWide) {
//这里是关联用户维度,所以找到用户维度的id
return String.valueOf(orderWide.getUser_id());
}
},
60,
TimeUnit.SECONDS);
//关联地区维度
SingleOutputStreamOperator<OrderWide> orderWideWithProvinceDS = AsyncDataStream.unorderedWait(orderWideWithUserDS,
new DimAsyncFunction<OrderWide>("DIM_BASE_PROVINCE") {
@Override
protected void joinData(JSONObject singleDimInfo, OrderWide orderWide) {
//提取维度信息并设置进 orderWide
orderWide.setProvince_name(singleDimInfo.getString("NAME"));
orderWide.setProvince_area_code(singleDimInfo.getString("AREA_CODE"));
orderWide.setProvince_iso_code(singleDimInfo.getString("ISO_CODE"));
orderWide.setProvince_3166_2_code(singleDimInfo.getString("ISO_3166_2"));
}
@Override
public String getKey(OrderWide orderWide) {
return orderWide.getProvince_id().toString();
}
}, 60,
TimeUnit.SECONDS);
//关联SKU维度
SingleOutputStreamOperator<OrderWide> orderWideWithSkuDS = AsyncDataStream.unorderedWait(orderWideWithProvinceDS,
new DimAsyncFunction<OrderWide>("DIM_SKU_INFO") {
@Override
protected void joinData(JSONObject singleDimInfo, OrderWide orderWide) {
orderWide.setSku_name(singleDimInfo.getString("SKU_NAME"));
orderWide.setCategory3_id(singleDimInfo.getLong("CATEGORY3_ID"));
orderWide.setSpu_id(singleDimInfo.getLong("SPU_ID"));
orderWide.setTm_id(singleDimInfo.getLong("TM_ID"));
}
@Override
public String getKey(OrderWide orderWide) {
return orderWide.getSku_id().toString();
}
}, 60,
TimeUnit.SECONDS);
//关联SPU维度
SingleOutputStreamOperator<OrderWide> orderWideWithSpuDS = AsyncDataStream.unorderedWait(orderWideWithSkuDS, new DimAsyncFunction<OrderWide>("DIM_SPU_INFO") {
@Override
protected void joinData(JSONObject singleDimInfo, OrderWide orderWide) {
orderWide.setSpu_name(singleDimInfo.getString("SPU_NAME"));
}
@Override
public String getKey(OrderWide orderWide) {
return orderWide.getSpu_id().toString();
}
}, 60, TimeUnit.SECONDS);
//关联品牌维度
SingleOutputStreamOperator<OrderWide> orderWideWithTmDS = AsyncDataStream.unorderedWait(orderWideWithSpuDS, new DimAsyncFunction<OrderWide>("DIM_BASE_TRADEMARK") {
@Override
protected void joinData(JSONObject singleDimInfo, OrderWide orderWide) {
orderWide.setTm_name(singleDimInfo.getString("TM_NAME"));
}
@Override
public String getKey(OrderWide orderWide) {
return orderWide.getTm_id().toString();
}
}, 60, TimeUnit.SECONDS);
//关联品类维度
SingleOutputStreamOperator<OrderWide> orderWideWithCatagory3DS = AsyncDataStream.unorderedWait(orderWideWithTmDS, new DimAsyncFunction<OrderWide>("DIM_BASE_CATEGORY3") {
@Override
protected void joinData(JSONObject singleDimInfo, OrderWide orderWide) {
orderWide.setCategory3_name(singleDimInfo.getString("NAME"));
}
@Override
public String getKey(OrderWide orderWide) {
return orderWide.getCategory3_id().toString();
}
}, 60, TimeUnit.SECONDS);
4)将关联完维度信息后的数据发送到Kafka中
//5、将关联完成的数据写入Kafka
orderWideWithCatagory3DS.map(data->JSON.toJSONString(data))
.addSink(MyKafkaUtil.getKafkaSink(orderWideSinkTopic));

















 8316
8316

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









