




 本文详细介绍了如何通过Flume从Kafka收集用户行为日志并存储到HDFS的过程,包括Flume的Source、Channel、Sink选型,重点解决了零点漂移问题,并提供了具体配置文件和启动运行的步骤。最后讨论了采用此方案的原因及后续的File Channel优化和HDFS小文件处理问题。
本文详细介绍了如何通过Flume从Kafka收集用户行为日志并存储到HDFS的过程,包括Flume的Source、Channel、Sink选型,重点解决了零点漂移问题,并提供了具体配置文件和启动运行的步骤。最后讨论了采用此方案的原因及后续的File Channel优化和HDFS小文件处理问题。
数据采集模块—行为日志采集
用户行为日志采集
这里接着上一部分,具体说明如何实现kafka到HDFS这一步骤。
一、架构图
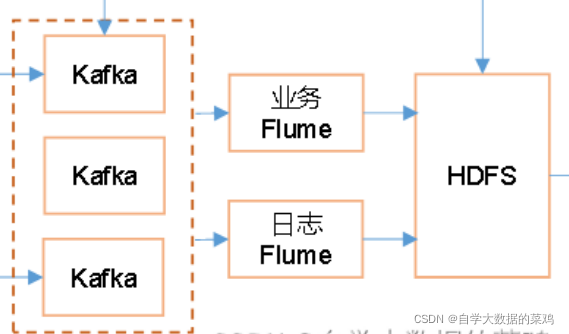
kafka到HDFS这一部分对应整体架构图中的上图部分。
二、Kafka—Flume—HDFS规划
这里说明如何实现从Kafka读取数据通过Flume传输数据到HDFS中。
1.Flume规划
hadoop102:不做处理
hadoop103:不做处理
hadoop104:Flume(作为消费者,从Kafka中读取数据)
2.Source选型
这里是从Kafka中读取数据,因此从原则上来说可以使用kafka channel中的无source有sink的类型,但是这里需要实现一个拦截器,因此必须要有source,因此这里不能使用kafka channle,这里的source选用kafka source
3.Channel选型
这里为了保障数据的安全性,采用File Channel
4.Sink选型
这里是要将数据传输到HDFS中,因此需要使用HDFS sink
5.Flume-HDFS配置规划
1.设计架构
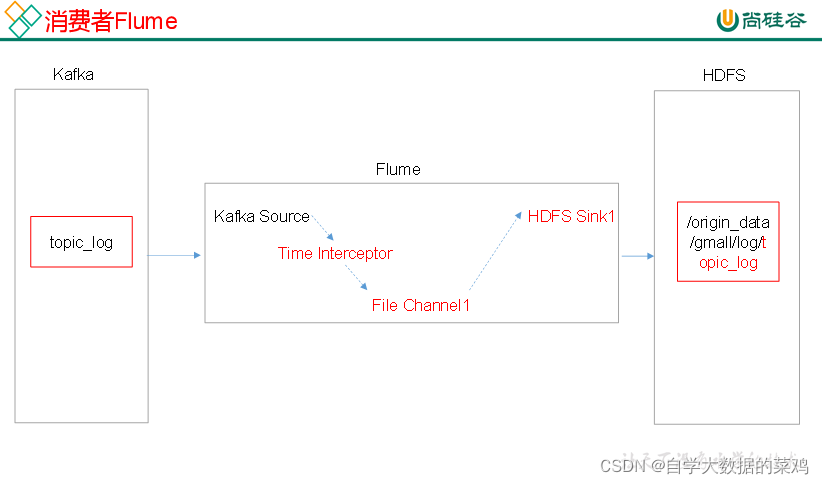
消费Flume配置关键点:
数据流程:Kafka中topic_log里的数据通过Kafka Source传输到File Channel,然后经过HDFS sink将数据存放到HDFS中。其中source和channel中间实现一个时间拦截器,解决零点漂移问题。
三、零点漂移问题
1.产生原因
在将Flume里的数据传输到HDFS里时,Flume默认会使用Linux系统时间作为输出到HDFS路径的时间,如果日志时间是23:59分,那么Flume消费kafka的数据时,可能已经是第二天了,所以必须要解决这种数据错乱的问题。
2.解决思路
在source和channel中使用拦截器,获取日志中真正的产生的时间,然后将这个时间写入到event的header头中,同时header里的key必须是timestamp,这样Flume框架会根据这个key的值自动识别为时间并在HDFS中创建对应的文件。
3.实现代码
编写TimeStampInterceptor类:
public class TimeStampInterceptor implements Interceptor {
private ArrayList<Event> events = new ArrayList<>();
@Override
public void initialize() {
}
@Override
public Event intercept(Event event) {
Map<String, String> headers = event.getHeaders();
String log = new String(event.getBody(), StandardCharsets.UTF_8);
JSONObject jsonObject = JSONObject.parseObject(log);
String ts = jsonObject.getString("ts");
headers.put("timestamp", ts);
return event;
}
@Override
public List<Event> intercept(List<Event> list) {
events.clear();
for (Event event : list) {
events.add(intercept(event));
}
return events;
}
@Override
public void close() {
}
public static class Builder implements Interceptor.Builder {
@Override
public Interceptor build() {
return new TimeStampInterceptor();
}
@Override
public void configure(Context context) {
}
}
}
四、Kafka-Flume-HDFS具体实现
1.配置文件实现
## 组件
a1.sources=r1
a1.channels=c1
a1.sinks=k1
## source1
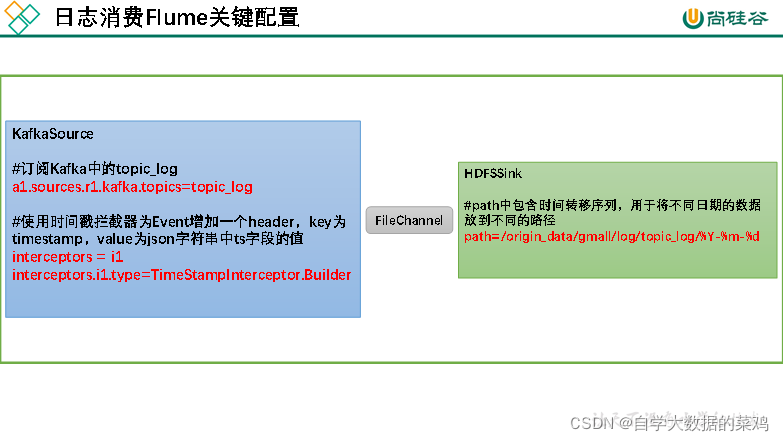
a1.sources.r1.type = org.apache.flume.source.kafka.KafkaSource
a1.sources.r1.batchSize = 5000 (一次消费读取5000条数据)
a1.sources.r1.batchDurationMillis = 2000 (条数不到,超过2000ms会去主动拉取数据)
a1.sources.r1.kafka.bootstrap.servers = hadoop102:9092,hadoop103:9092,hadoop104:9092
a1.sources.r1.kafka.topics=topic_log
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type =com.atguigu.flume.interceptor.TimeStampInterceptor$Builder
## channel1
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /opt/module/flume/checkpoint/behavior1 (检查点,保证断点续传)
a1.channels.c1.dataDirs = /opt/module/flume/data/behavior1/
a1.channels.c1.maxFileSize = 2146435071 (单个文件大小上限,可不写)
a1.channels.c1.capacity = 1000000 (file channel总的容量,1000000个event,可不写)
a1.channels.c1.keep-alive = 6 (event保存在磁盘的时间,可不写)
## sink1
a1.sinks.k1.type = hdfs
(Flume会识别%Y-%m-%d创建对应某年某月某日的HDFS文件夹)
a1.sinks.k1.hdfs.path = /origin_data/gmall/log/topic_log/%Y-%m-%d
(每一个生成的文件加一个前缀log-)
a1.sinks.k1.hdfs.filePrefix = log-
(上面是按照一天建立一个文件夹,round设置为true可以选择按小时、分钟建立文件夹)
a1.sinks.k1.hdfs.round = false
#控制生成的小文件
a1.sinks.k1.hdfs.rollInterval = 10
a1.sinks.k1.hdfs.rollSize = 134217728
a1.sinks.k1.hdfs.rollCount = 0
## 控制输出文件是原生文件。
(采用压缩流的方式)
a1.sinks.k1.hdfs.fileType = CompressedStream
(采用lzop的压缩方式)
a1.sinks.k1.hdfs.codeC = gzip (使用gzip是因为DataX只支持gzip)
## 拼装
a1.sources.r1.channels = c1
a1.sinks.k1.channel= c1
2.启动运行
将拦截器代码打包,放到hadoop104服务器flume/lib文件夹下,启动flume和对应文件
五、一些需要注意的地方:
1.整体流程的选择
选择1:
第一个选择是采用有source有sink的类型,使用一个Flume就可以实现从文件中拿数据,然后将数据一次传输到Kafka和HDFS中
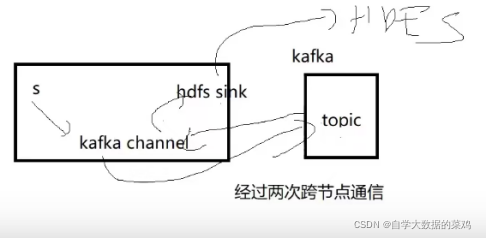
选择2:
第二个选择是本项目的选择,采用了两个Flume,前一个Flume作为生产者往Kafka中存放数据,后一个Flume作为消费者,从Kafka中拿数据然后将数据存放到HDFS中
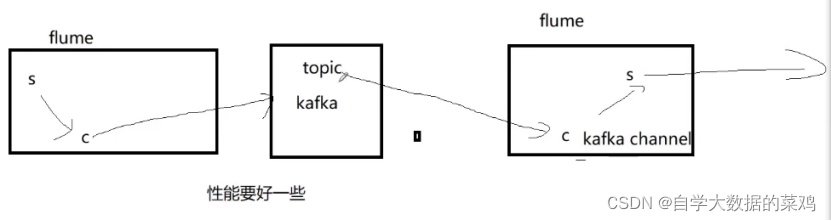
选择方式二的原因:
1)第一,方便后续进行流处理,将数据传输给Spark Streaming。如果Flume直接上传到HDFS中,后续流处理从HDFS中读取数据的速度是非常慢的,不方便。
2)到一个聚合的作用。因为这里有多台日志服务器,如果每一个日志服务器对应一个Flume直接上传文件到HDFS,那么一个Flume会单独在HDFS中创建一个文件夹,这样文件会被打散开,所有的文件夹拼到一起才算一天的数据;而先将所有的日志上传到Kafka中,再进行上传日志,这样一天的数据都在一个文件夹里。
六、总结
至此,用户日志数据传输过程全部完成!!!
5.File Channel优化
后面补充????????????????
6.HDFS sink小文件处理
后面补充????????????????

















 713
713

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









