



 本文概述了Linux云计算SRE工程师应掌握的核心技能,包括运维自动化工具(如shell、Ansible和Jenkins)、日志管理、监控自动化、消息队列(如Kafka)、K8S容器编排、ELK日志系统以及微服务架构。这些技能在招聘需求和培训课程大纲中至关重要。
本文概述了Linux云计算SRE工程师应掌握的核心技能,包括运维自动化工具(如shell、Ansible和Jenkins)、日志管理、监控自动化、消息队列(如Kafka)、K8S容器编排、ELK日志系统以及微服务架构。这些技能在招聘需求和培训课程大纲中至关重要。
首先上一张图,这是Linux云计算SRE工程师必备核心技能,也就是说图中提到的知识,SRE必须要掌握。
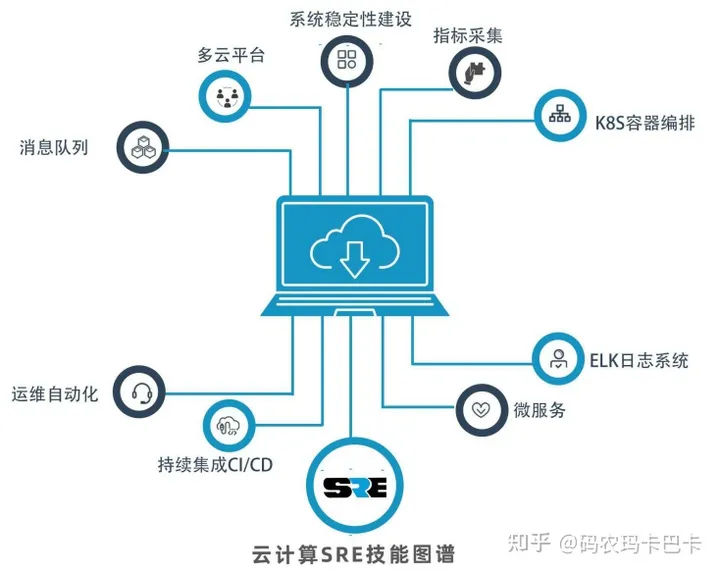
一、运维自动化
利用一些自动化工具,帮助运维解决重复性工作,掌握自动化工具,属于运维(SRE)必备的技能。
哪些自动化工具需要掌握呢?
自动化发布:shell,ansible、jenkins、gitlab等
自动化部署:shell、ansible、playbook等
日志管理:rsyslog管理日志等
监控自动化:zabbix、Prometheus等
二、消息队列
消息队列是一种应用程序对应用程序的通信方法,可以简单理解成:把要传输的数据放在队列中。
消息队列中间件是分布式系统中重要的组件,主要解决应用解耦,异步消息,流量削峰,消息通讯等问题,从而实现高性能,高可用,可伸缩和最终一致性的架构。
常见的消息队列开源软件有:
Kafka、abbitMQ、RockerMQ、ZeroMQ等等
三、K8S
K8S是面向企业的开源容器编排工具的事实标准,它提供了应用部署、扩展、容器管理和其他功能,使企业能够通过容错能力快速优化硬件资源利用率并延长生产环境运行时间。
四、ELK日志系统
ELK是Elasticsearch , Logstash, Kibana 三个开源软件的缩写。
Elasticsearch是个开源分布式搜索引擎,提供搜集、分析、存储数据三大功能
Logstash 主要是用来日志的搜集、分析、过滤日志的工具,支持大量的数据获取方式
Kibana 也是一个开源和免费的工具,Kibana可以为 Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面,可以帮助汇总、分析和搜索重要数据日志
五、微服务
微服务是一种用于构建应用的架构方案。微服务架构有别于更为传统的单体式方案,可将应用拆分成多个核心功能,可以单独构建和部署,这意味着各项服务在工作时不会相互影响。
目前国内企业使用的微服务框架主要是Spring Cloud和Dubbo。
看完图谱,我们可以再看看招聘JD
360:

陌陌:

快手:

综合来看,与我上面说到的SRE技能图谱中大部分还是重合的,这些重合的地方就是SRE必备知识,是核心,你可以不会其他的,但这些重合的技能必须要掌握。
另外可以去看看培训机构的SRE课程大纲,里面涉及到的内容就是SRE需要掌握的,但要注重掌握程度的深浅,还是以招聘JD和技能图谱为主,其他为辅。
这里可以分享一份SRE学习路线图,按照路线图学习,掌握必备知识就有头绪了。
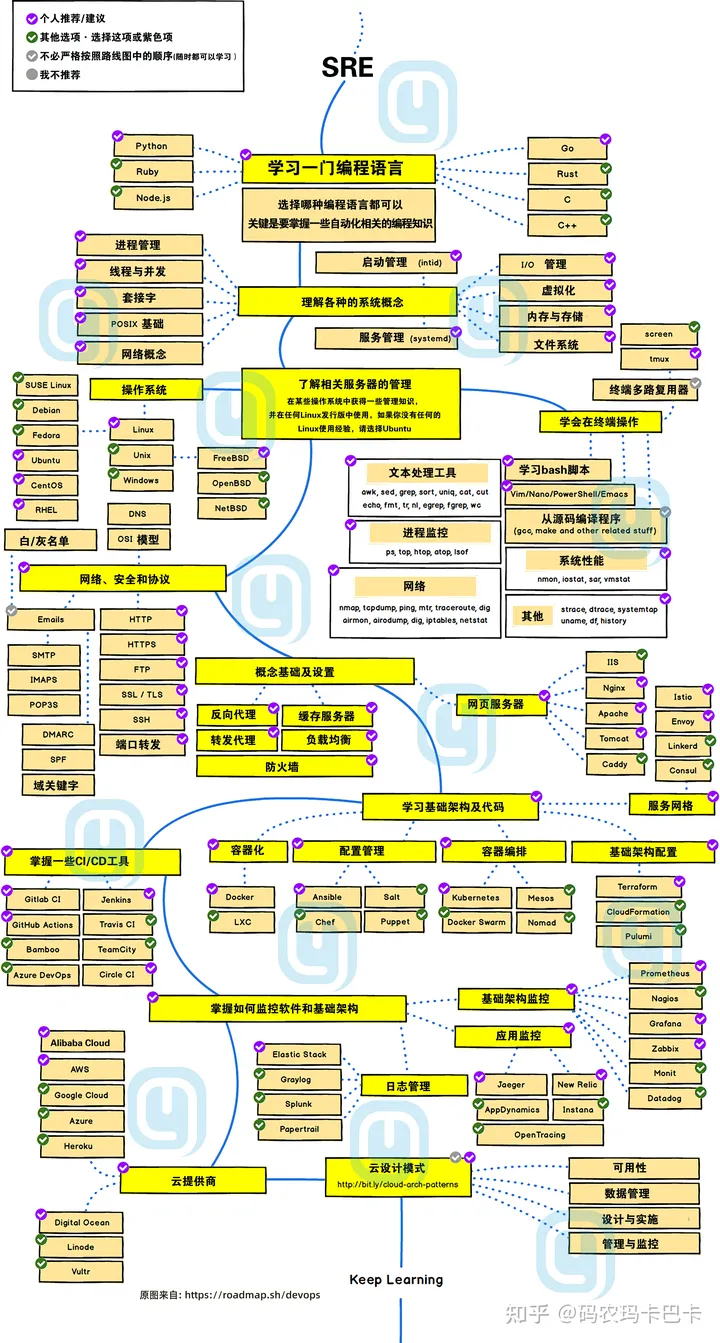

















 575
575

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









