






 本文介绍了一项使用机器学习技术,特别是循环神经网络(RNN),来模仿美国前总统特朗普独特说话风格的研究。通过收集特朗普的推特和演讲数据,并采用文本生成技术,实验成功生成了具有特朗普特色的文本。
本文介绍了一项使用机器学习技术,特别是循环神经网络(RNN),来模仿美国前总统特朗普独特说话风格的研究。通过收集特朗普的推特和演讲数据,并采用文本生成技术,实验成功生成了具有特朗普特色的文本。

I know words. I have the best words.
在 2015 年 12 月 30 日举行的南卡罗来纳州竞选会上,川普说出了上面这些话。这些「川普主义」的言论使得特朗普的粉丝更加喜欢他,但也使他成为其他人的笑柄。
无论每个人对他的看法如何,川普的说话方式毋庸置疑是十分独特的:他的言语十分随意且无视传统句子结构约束。这类特点使他的讲话十分具有辨识度。
正是这种独特的风格吸引了我,我尝试用机器学习来模仿它:生成看起来或听起来像川普会说的文本。
要学习川普的说话风格,首先要获取足够多的语言样本。我主要关注两个主要的数据来源。

与推特不同的是,虽然每一个字都是由特朗普本人所写或口述的,但这些文本还包含其他政治家或者记者所说的话。将川普所说的话与其他人的区分开来似乎是一项艰巨的任务。
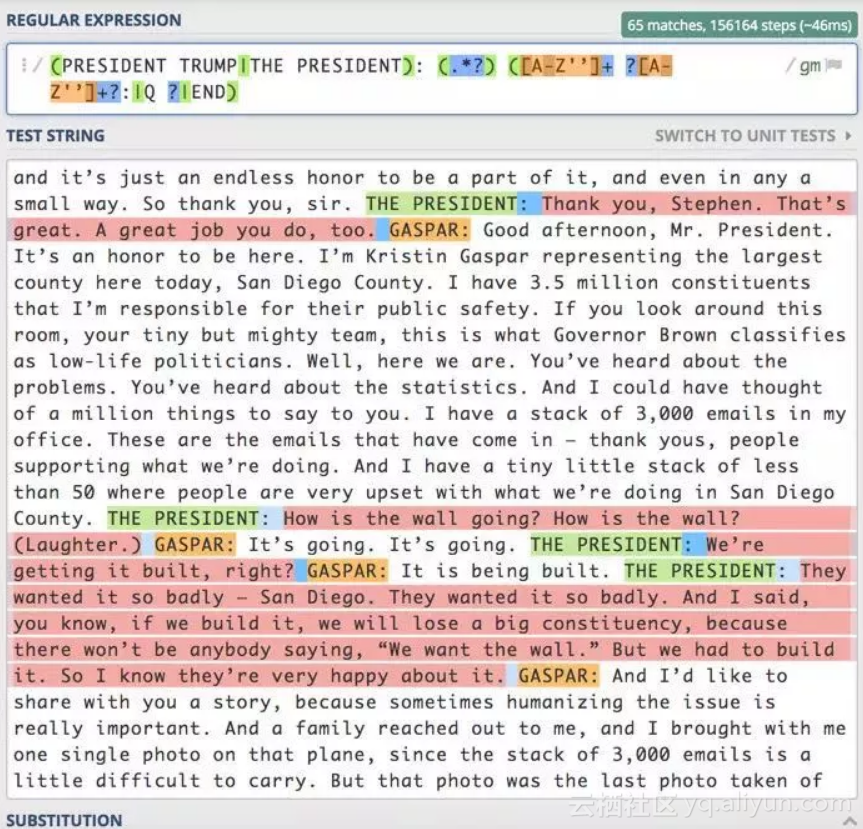
正则表达式允许你指定要搜索的模式;此模式可以包含任意数量的特定约束、通配符或其他限制,以保证返回的数据能够满足你的要求。
经过一些试验和调整,我生成了一个复杂的正则表达式,它只返回总统的言论,而不会返回其他的词或注释。
然而,对我而言,归一化过程中会丢失的具体特质和模式正是我需要保留的。所以,为了让我生成的文本更加可信和真实,我选择绕过大部分标准归一化工作流程。
马尔可夫链是快速且粗糙的,它只关注当前的词,以确定接下来的词是什么。这种算法每次只关注当前的词以及接下来可能会出现的词。下一个词是随机选择的,其概率与频率成正比。下面用一个简单的例子来说明:

简化的马尔可夫链例子,其中接着「taxes」出现的可以是「bigly」、「soon」或者句号。
之后马尔可夫链可能会不断的生成下去,或者直到句子结束才停止。
使用我有限的文本数据集,马尔可夫链的大部分输出是无意义的。但偶尔也会有「灵光一现」:
![]()
然而如果要训练得到更加真实的文本,需要一些更复杂的算法。循环神经网络(RNN)已经成为许多文本或基于序列的应用的首选架构。RNN 的详细内部工作原理不在本文的讨论范围之内。
这些神经元的显著特征是它们具有各种内部「记忆」。单词的选择和语法很大程度上依赖于上下文,而这些「记忆」能够跟踪时态、主语和宾语等,这对生成连贯的句子是非常有用的。
这类网络的缺点是它们的计算量非常大,在笔记本电脑上用模型将我的文本数据训练一次要一个多小时,考虑到要这样训练大约 200 次,这类网络不是很友好。
这里就需要云计算大展身手了。许多成熟的科技公司提供云服务,其中最大的是亚马逊、谷歌和微软。在需要大量 GPU 计算的实例中,之前需要一个小时的过程缩减为九十秒,时间减少大约四十倍!
California finally deserves a great Government to Make America Great Again! #Trump2016
我所实现的复杂版本的神经网络(在循环层之前和之后有隐藏的全连接层)能够在种子为 40 个或小于 40 个字符的情况下生成内部连贯的文本。
I want them all to get together and I want people that can look at the farms.
China has agreed to buy massive amounts of the world—and stop what a massive American deal.
而简化版本的网络在连贯性方面有所欠缺,但仍然能够捕捉到特朗普总统讲话的语言风格:
Obama. We'll have a lot of people that do we—okay? I'll tell you they were a little bit of it.

虽然没能一直产生足以欺骗你我的文本,但这种尝试让我看到了 RNN 的力量。简而言之,这些网络学习了拼写、语法的某些方面,以及在特定情况下如何使用井号标签和超链接。

















 2659
2659

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









