



Tensorflow是一种被广泛使用的实现机器学习和其他涉及大量数学运算的算法的库。Tensorflow是由Google开发的,是GitHub上最流行的机器学习库之一。Google几乎在所有应用程序中都使用Tensorflow来实现机器学习。例如,如果您正在使用Google照片或Google语音搜索,则您间接使用Tensorflow模型,它们可以在大型Google硬件集群上工作,并且在感知任务方面功能强大。
这篇文章的主要目的是为初学者提供TensorFlow入门介绍,在此我假设你对python已经有所了解。TensorFlow的核心组件是通过边缘遍历所有节点的计算图和张量。我们来简单介绍一下。
张量:
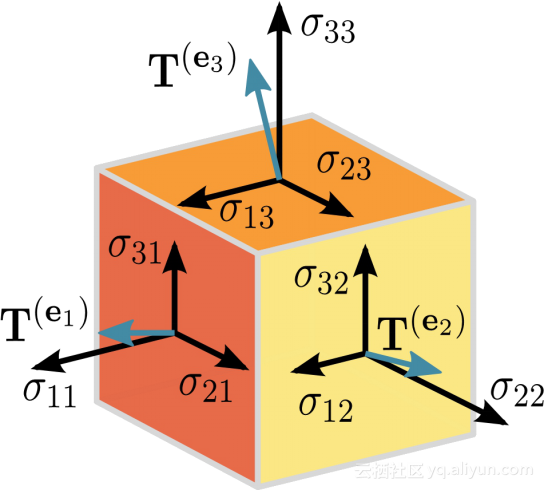
在数学上,张量是一个n维向量,意味着一个张量可以用来表示n维数据集。上面的图比较难以理解。我们来看看它的简化版。
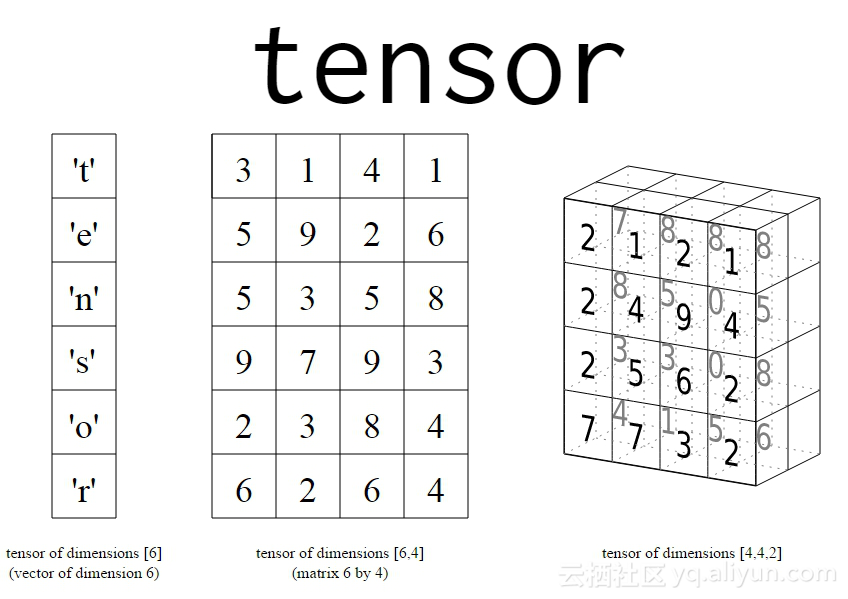
上面的图显示了一些简单的最小尺寸的张量。 随着维度的不断增加,数据表示变得越来越复杂。例如,如果我们拿一个(3x3)形式的张量,那么我可以简单地称它为一个3行和3列的矩阵。如果我选择另一个形式(1000x3x3)的张量,我可以将其作为一个矢量或一组1000个3x3矩阵。在这里我们称(1000x3x3)作为所得张量的形状或尺寸。张量可以是常量也可以是变量。
计算图(流):
现在我们明白了张量的真正含义,现在是了解流的时候了。这种流指的是一个计算图或简单的一个图,图不能循环,图中的每个节点代表加法、减法等运算,每个运算结果形成新的张量。
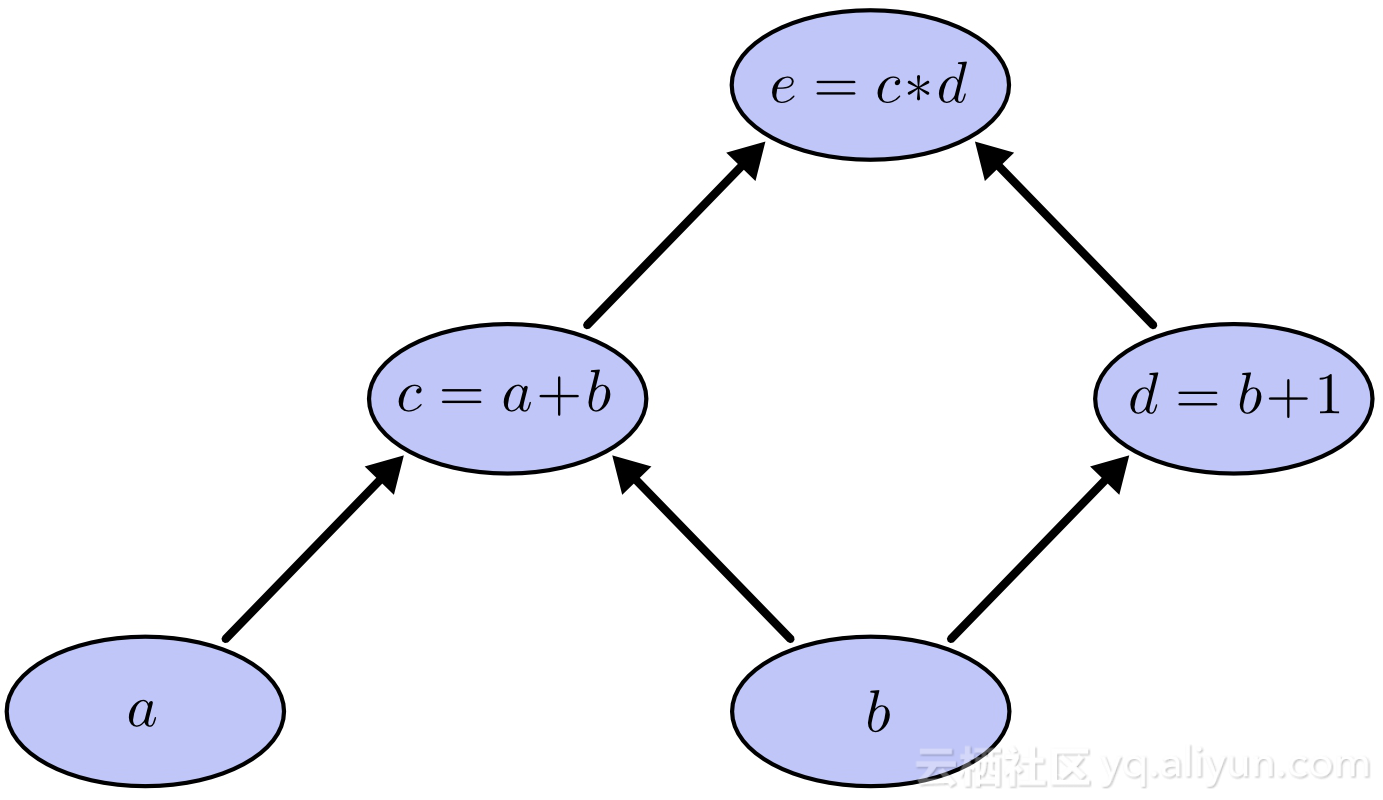
上图显示了一个简单的计算图。 计算图具有以下属性:
上图的表达式:
e=(a+b)x(b+1)
叶顶点或开始顶点始终是张量。 意思是,一个操作在图的开始处不会发生,因此我们可以推断图中的每个操作都应该接受一个张量并产生一个新的张量。 同样,张量不能作为非叶子节点出现,这意味着它们总是作为输入提供给操作/节点。
计算图总是以层次顺序表示复杂的操作。 上面的表达式可以按层次结构组织,通过将a + b表示为c,将b + 1表示为d。 所以我们可以把e写成:
e =(c)x(d)其中c = a + b和d = b + 1。
以相反的顺序遍历图形产生子表达式的组合,形成最终的表达式。
当我们向前运行时,我们遇到的顶点总是对下一个顶点有依赖关系,例如没有a和b就不能得到c,同样的,如果不解决c和d就不能得到e。
在同级节点中的操作是相互独立的。这是计算图的重要属性之一,当我们按照图中所示的方式构造一个图时,很自然的,例如c和d在同一层上的节点是相互独立的,意味着没有必要在评估d之前了解c。因此它们可以并行执行。
计算图中的并行性:
上面提到的最后一个属性当然是最重要的属性之一,它清楚地表明,同级别的节点是独立的,意味着在c被评估之前不需要被闲置,在c被评估的时候,可以并行计算d。Tensorflow极大地利用了这个属性。
分布式执行:
Tensorflow允许用户使用并行计算设备来更快地执行操作。 计算的节点或操作被自动调度用于并行计算。 这一切都发生在内部,例如在上面的图中,可以在CPU上调度操作c,并且可以在GPU上调度操作d。 下面的图显示了两个分布式执行的前景:
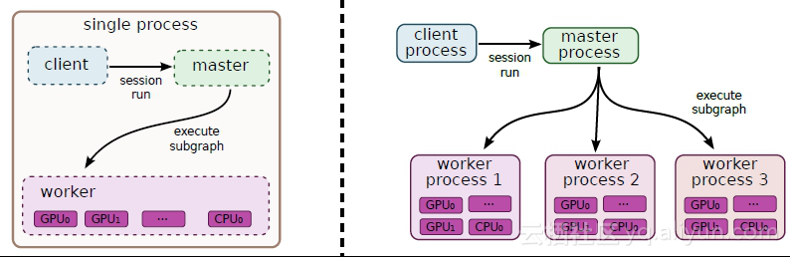
第一个是单个系统的分布式执行,其中单个Tensorflow会话(将在后面解释)创建一个单独的worker,而worker负责在各种设备上安排任务,在第二种情况下,有多个worker,他们可以在同一台机器上或不同的机器上,每个worker都在自己的环境中运行,在上面的图中,worker进程1在一台单独的机器上运行,并安排所有可用设备上的操作。
计算子图:
子图是主图的一部分,本身就是计算图。 例如,在上面的图中,我们可以获得许多子图,其中之一如下所示
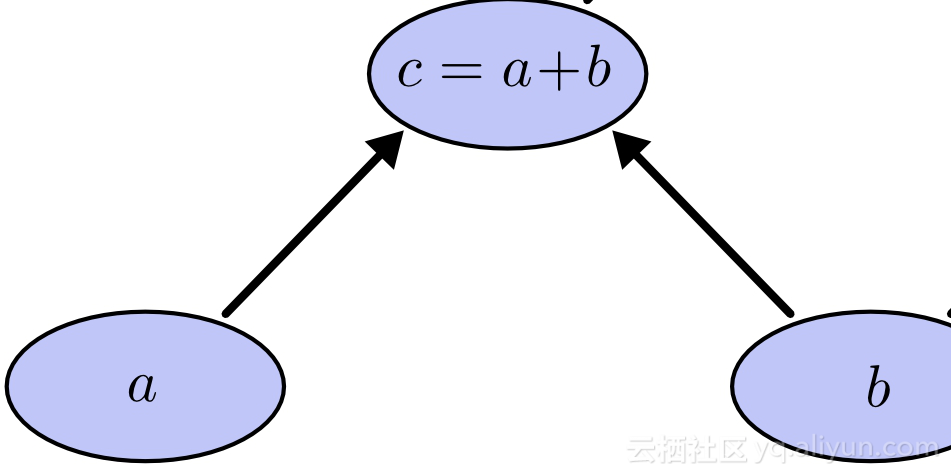
上面的图是主图的一部分,从属性2我们可以说子图总是表示一个子表达式,正如c是e的子表达式。 子图也满足最后一个属性。 同一级别的子图也是相互独立的,可以并行执行。因此,可以在一台设备上调度整个子图。
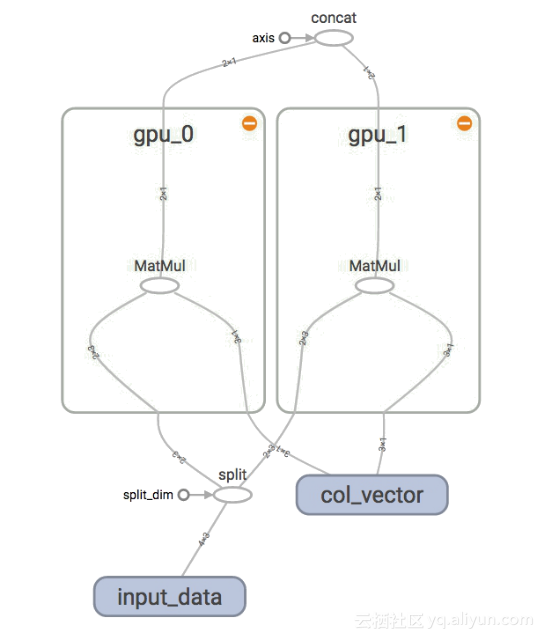
上面的图解释了子图的并行执行。这里有2个矩阵乘法运算,因为它们都在同一个层次上,它们是相互独立的,这和上一个属性是一致的。这些节点被安排在不同的设备gpu_0和gpu_1上,这是因为独立性。
在workers之间交换数据:
现在我们知道Tensorflow将其所有的操作分布在由worker管理的不同设备上。更常见的是,张量形式的数据在worker之间进行交换,例如在e =(c)*(d)的图中,一旦计算出c,就需要将其进一步传递给e,因此Tensorflows 从节点到节点向上操作。这个动作如图所示:
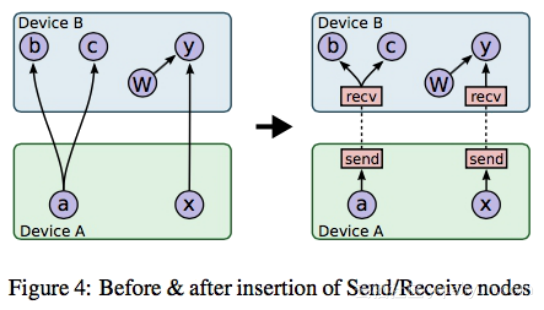
在这里,A设备的张量被传递给设备B,这会导致分布式系统中的一些性能延迟。延迟取决于一个重要的属性,那就是是张量的大小。设备B处于理想模式,直到它接收到设备A的输入。
压缩需求:
那么,显然在计算图中,张量在节点之间流动。在流到达可以处理的节点之前,减少流引起的延迟是非常重要的。减小尺寸的一个想法是使用有损压缩。
张量的数据类型起着重要的作用,让我们来了解为什么,很明显,我们在机器学习操作中要求更高的精度,例如,如果我们使用float32作为张量的数据类型,那么每个值都被表示 使用32位浮点数,所以每个值占用32位的大小,这同样适用于64位。 假设假设一个张量的形状(1000,440,440,3),如果数据类型是32位那么就是是这个大数字的32倍,张量中可以包含的值的数量将是1000 * 440 * 440 * 3,它占据内存中重要的空间,因而延迟流。压缩技术可以用来减小尺寸。我有几张阿里云幸运券分享给你,用券购买或者升级阿里云相应产品会有特惠惊喜哦!把想要买的产品的幸运券都领走吧!快下手,马上就要抢光了。https://promotion.aliyun.com/ntms/act/ambassador/sharetouser.html?userCode=n7gh3gne&utm_source=n7gh3gne
有损压缩:
有损压缩处理压缩数据的大小,并不关心它的值,意味着它的值可能会在压缩过程中损坏或不准确。但是,如果我们有一个像1.01010e-12这样的32位浮点数,那么重要性就不那么重要了。更改或删除这些值不会在我们的计算中造成太大的差别。因此,Tensorflow自动将32位的浮点数转换为16位表示,忽略所有可忽略的数字,如果它是一个64位的数字,则会减小近一半的数量,压缩到16位,这几乎缩小75%。因此张量所占据的空间可以被最小化。
一旦张量到达节点,16位表示可以通过追加0返回到它的原始形式。因此,一个32或64位表示在到达节点进行处理后返回。


















 1150
1150

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









