




背景
在MaxCompute查询中,Join是很常见的场景。例如以下Query,就是一个简单的Inner Join把t1表和t2表通过id连接起来:
SELECT t1.a, t2.b FROM t1 JOIN t2 ON t1.id = t2.id;
Join在MaxCompute内部主要有三种实现方法:
Broadcast Hash Join - 当Join存在一个很小的表时,我们会采用这种方式,即把小表广播传递到所有的Join Task Instance上面,然后直接和大表做Hash Join。
Shuffle Hash Join - 如果Join表比较大,我们就不能直接广播了。这时候,我么可以把两个表按照Join Key做Hash Shuffle,由于相同的键值Hash结果也是一样的,这就保证了相同的Key的记录会收集到同一个Join Task Instance上面。然后,每个Instance对数据量小的一路建Hash表,数据量大的顺序读取Join。
Sort Merge Join - 如果Join的表更大一些,#2的方法也用不了,因为内存已经不足以容纳建立一个Hash Table。这时我们的实现方法是,先按照Join Key做Hash Shuffle,然后再按照Join Key做排序,最后我们对Join双方做一个归并,具体流程如下图所示:
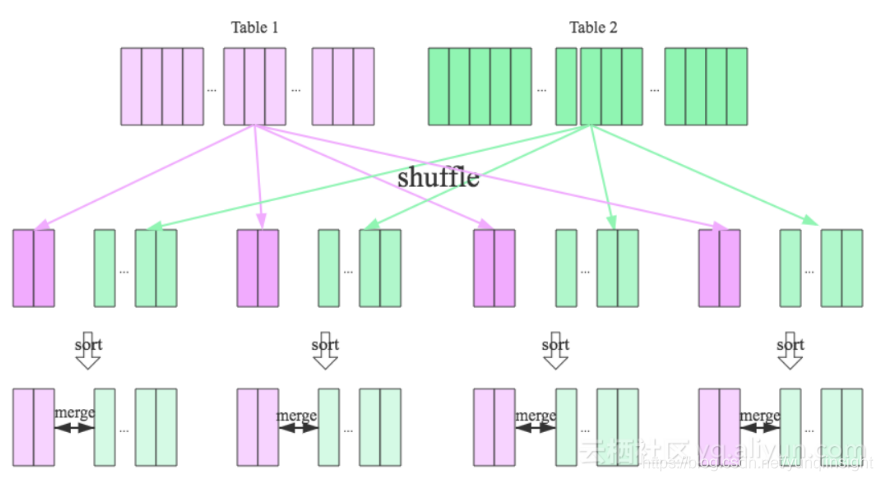
实际上对于MaxCompute今天的数据量和规模,我们绝大多数情况下都是使用的Sort Merge Join,但这其实是非常昂贵的操作。从上图可以看到,Shuffle的时候需要一次计算,并且中间结果需要落盘,后续Reducer读取的时候,又需要读取和排序的过程。对于M个Mapper和R个Reducer的场景,我们将产生M x R次的IO读取。对应的Fuxi物理执行计划如下所示,需要两个Mapper Stage,一个Join Stage,其中红色部分为Shuffle和Sort操作: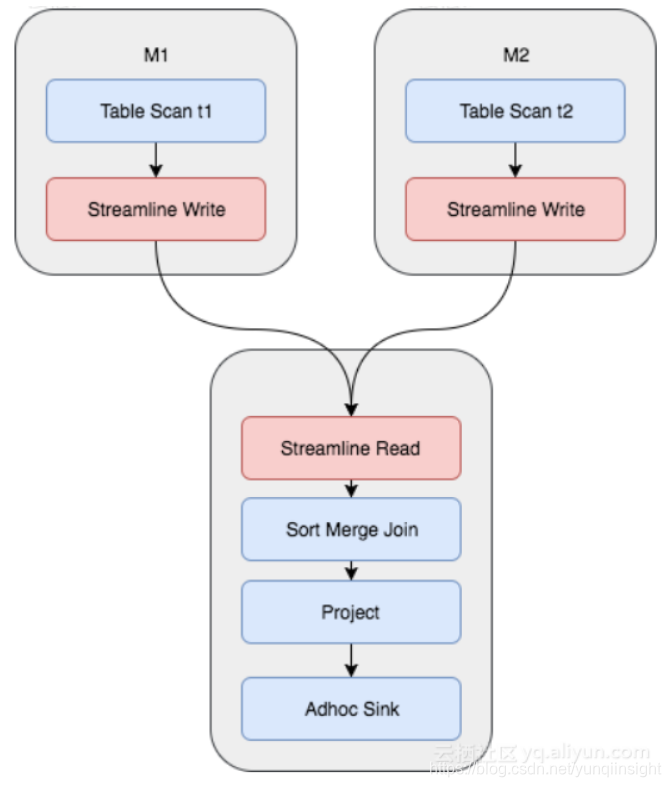
与此同时,我们观察到,有些Join是可能反复发生的,比如上面的Query改成了:SELECT t1.c, t2.d FROM t1 JOIN t2 ON t1.id = t2.id;
虽然,我们选择的列不一样了,但是底下的Join是完全一样的,整个Shuffle和Sort的过程也是完全一样的。
又或者:SELECT t1.c, t3.d FROM t1 JOIN t3 ON t1.id = t3.id;
这个时候是t1和t3来Join,但实际上对于t1而言,整个Shuffle和Sort过程还是完全一样。
于是,我们考虑,如果我们初始表数据生成时,按照Hash Shuffle和Sort的方式存储,那么后续查询中将避免对数据的再次Shuffle和Sort。这样做的好处是,虽然建表时付出了一次性的代价,却节省了将来可能产生的反复的Shuffle和Jo
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2027
2027

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









