





作为数据科学家,你最重要的技能之一应该是为你的问题选择正确的建模技术和算法。几个月前,我试图解决文本分类问题,即分类哪些新闻文章与我的客户相关。
我只有几千个标记的例子,所以我开始使用简单的经典机器学习建模方法,如TF-IDF上的Logistic回归,但这个模型通常适用于长文档的文本分类。
在发现了我的模型错误之后,我发现仅仅是理解词对于这个任务是不够的,我需要一个模型,它将使用对文档的更深层次的语义理解。
深度学习模型在复杂任务上有非常好的表现,这些任务通常需要深入理解翻译、问答、摘要、自然语言推理等文本。所以这似乎是一种很好的方法,但深度学习通常需要数十万甚至数百万的训练标记的数据点,几千的数据量显然是不够的。
通常,大数据集进行深度学习以避免过度拟合。深度神经网络具有许多参数,因此通常如果它们没有足够的数据,它们往往会记住训练集并且在测试集上表现不佳。为了避免没有大数据出现这种现象,我们需要使用特殊技术。
在这篇文章中,我将展示我在文章、博客、论坛、Kaggle上发现的一些方法,以便在没有大数据的情况下更好地完成目标。其中许多方法都基于计算机视觉中广泛使用的最佳实践。
正则化
正则化方法是在机器学习模型内部以不同方式使用的方法,以避免过度拟合,这个方法具有强大的理论背景并且可以以通用的方式解决大多数问题。
L1和L2正则化
这个方法可能是最古老的,它在许多机器学习模型中使用多年。在这个方法中,我们将权重大小添加到我们试图最小化的模型的损失函数中。这样,模型将尝试使权重变小,并且对模型没有帮助的权重将显着减小到零,并且不会影响模型。这样,我们可以使用更少数量的权重来模拟训练集。有关更多说明,你可以阅读这篇文章。
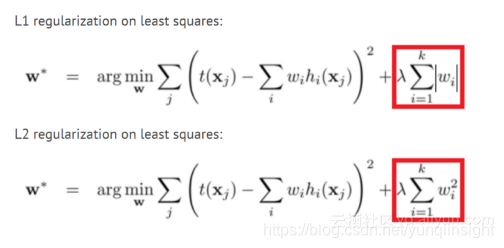
Dropout
Dropout是另一种较新的正则化方法,训练期间神经网络中的每个节点(神经元)都将被丢弃(权重将被设置为零),这种方式下
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2024
2024

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









