




 Java从JDK1.2开始提供类集框架解决数组长度固定问题,它是数据结构的实现。核心接口有Collection和Map,Collection有List、Set等子接口,各有常用子类;Map有HashMap、Hashtable等子类。文中还剖析了部分子类源码,并解答了相关面试题。
Java从JDK1.2开始提供类集框架解决数组长度固定问题,它是数据结构的实现。核心接口有Collection和Map,Collection有List、Set等子接口,各有常用子类;Map有HashMap、Hashtable等子类。文中还剖析了部分子类源码,并解答了相关面试题。
Java类集实际上属于动态对象数组,在实际开发应用中,数组使用的几率并不高,因为数组最大的缺陷就是:数组长度是固定的。由于此问题存在,Java从JDK1.2开始,为了解决数组长度问题,提供了动态的对象数组实现框架--Java类集框架。Java集合类框架实际上就是对数据结构的一种实现。
在Java的类集(java.util包)中提供了俩个最为的核心的接口:Collection、Map接口。
Collection接口
Collection是单个集合保存的最大父接口
定义如下:public interface Collection<E> extends Iterable<E>
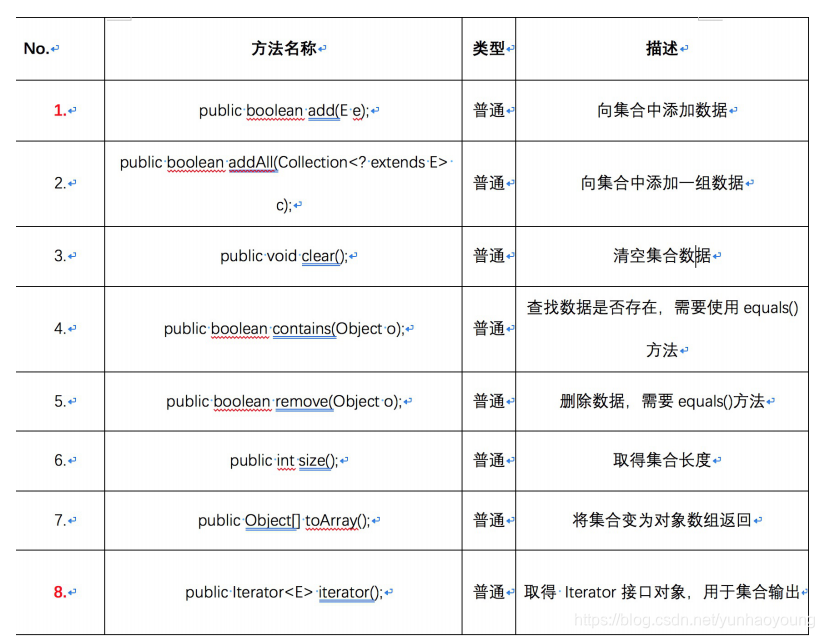
在JDK1.5中开始在Collection接口上追加了泛型,避免了ClassCastException,使保存的数据的类型相同
Collection接口中有add()、iterator()两个重要方法
Collection接口主要有List、Set、Queue、Iterator子接口。
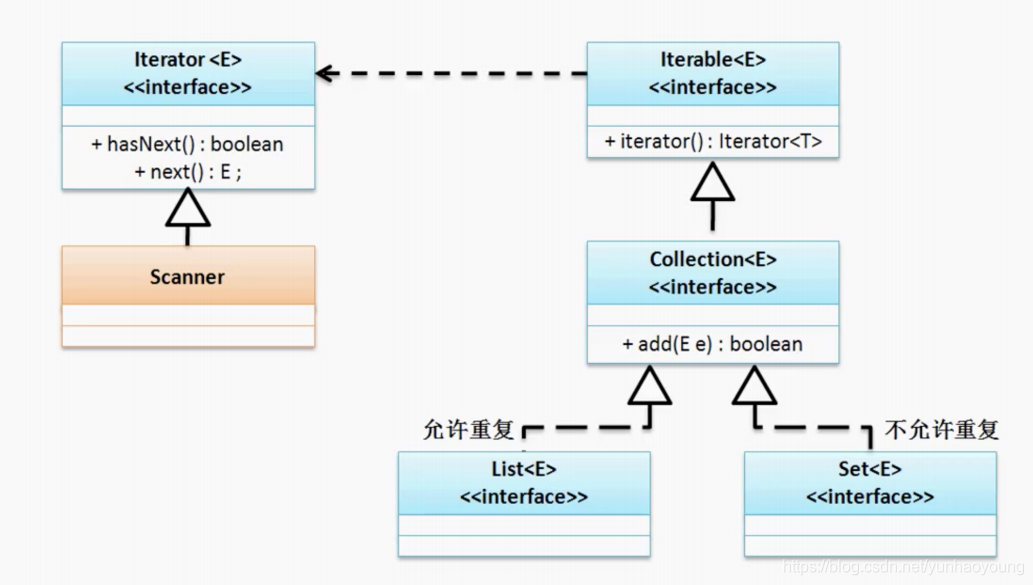
List接口--允许重复元素
List接口下主要有ArrayList、LinkedList 、Vector三个常用子类
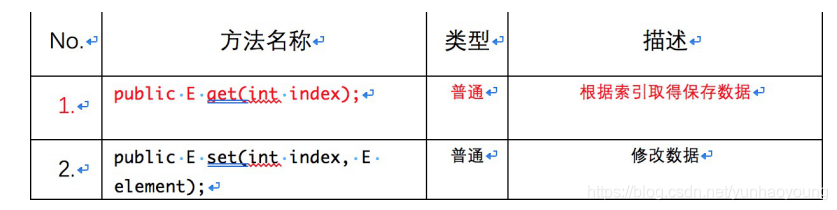
其中List接口中有俩个重要的子类方法
ArrayList--优先考虑--JDK1.2
接口中主要保存自定义类对象,自定义对象中必须覆写equals()方法,类集中contains()、remove()等方法需要调用equals方法来判断元素是否相等。
底层实现是对象数组,声明一个ArrayList对象时,长度为0
对集合的增删查改是异步处理,性能较高,线程不安全
当数组长度不够时,扩容为原来数组的1.5倍
Vector--JDK1.0
底层实现是对象数组,声明一个Vector对象时,长度为10
对集合的增删查改是同步处理(直接在方法上使用内建锁),性能较低,线程安全
当数组长度不够时,扩容为原来数组的2倍
LinkedList
基于链表实现的动态数组
面试题1:请解释ArrayList与Vector的区别
产生版本:Vector是JDK1.0版本产生的;ArrayList是JDK1.2版本产生的
线程安全:Vector采用在方法上加synchronize来保证线程安全,性能较低;ArrayList采用异步处理,性能较高,线程不安全
初始化及其扩容机制:Vector初始化数组大小是10,当数组不够时,扩容为原来数组的两倍;ArrayList采用懒加载策略,当第一次添加元素时才进行初始化,当数组长度不够时,扩容为原来数组的1.5倍
面试题2:fail-fast与fail-safe
fail-fast:java.util.concurrentModifacationException
如何产生:在集合迭代遍历同时修改集合结构(remove、add)
本质:modCount != expectedModCount
为何抛出此异常:尽量保证多线程场景下数据不会产生脏读
哪些类会抛出此异常:ArrayList、LinkedList、Vector
fail-safe:juc包下集合
ConcurrentHashMap、CopyOnWriteArrayList
Set接口--不允许元素重复
Set接口中方法与Collection接口中方法一致,常用有两个子类HashSet、TreeSet
HashSet--无序存储--底层基于哈希表
不允许重复元素,并且无序存储(根据hash码来保存元素),允许存放null值
TreeSet--有序存储--底层基于红黑树
不允许重复元素,并且按照升序排序,不允许存放null值
面试题1:TreeSet有序,序指的是什么
要使用TreeSet必须满足下列两个条件:
作为TreeSet集合的类,实现Compareable接口(内部排序);
通过构造方法传入Compareable接口对象(外部方法)
优先使用外部排序接口(更加灵活、策略模式)
面试题2:HashSet中元素判重依据
hashcode()
equals()
Queue--了解
Deque---双端队列
BlockingQueue---juc下阻塞队列,线程池
Iterator--集合遍历迭代器接口
判断是否有下一个元素:public boolean hasNext()
取得当前元素:public E next()
删除元素:public default void remove() --- JDK1.8开始变为default完整方法
Map接口--保存一对对象的接口
Map接口定义:public interface Map<K,V>
Map接口下常用方法:

Map接口下主要子类有HashMap、Hashtable、CurrentHashMap、TreeMap
HashMap--JDK1.8
源码剖析
1.成员变量、树化阈值
桶个数为16
扩容负载因子为0.75f
树化阈值为8
最小树化容量64
解除树化阈值6----reasize阶段
树化总结:当桶中链表元素超过8并且哈希表总元素个数超过64,此时桶中链表结构会转换为红黑树,否则,只是简单的扩容
why树化:当桶中链表元素个数太大会大大影响查找速度,因此将其树化来提高指定结点的速度
2.初始化策略
HashMap采用lady_load策略,当第一个put时,才将哈希表初始化
无参构造:仅仅赋值负载因子0.75
有参构造:初始化容量必须为2的整数幕,若传入非2的整数幕的数,则会调用tableSizeFor返回离2^n最近的数。eg:传15,返回16
3.put、get方式
put方法流程:
1.若HashMap还未初始化,调用reasize进行初始化操作;
2.对Key值Hash取得要存储的桶下标:
a.若桶中为空,则将结点直接作为桶的头结点保存;
b.若桶不为空
若树化,使用树化方式添加新节点
将新节点以链表形式尾插到最后,添加元素后,链表的个数binCount>=-1树化阈值,尝试进行树化操作
c.若桶中存在相同key结点,替换value值
3.添加元素后,计算整个哈希表的大小,若超过threshold(容量*负载因子),进行reasize扩容机制
get方法流程:
1.若哈希表已经初始化并且桶中首结点不为空
a.查找结点的key值恰好等于首节点,直接返回首节点
b.进行桶元素的遍历,查找指定结点
若树化,则按照树的方式进行查找
按照链表方式查找
2.哈希表为空或桶的首节点为空,直接返回null
4.哈希算法、扩容机制、性能
哈希算法:返回高低16位共同参与运算的hash值
扩容机制(reasize):判断哈希表是否初始化,若还未初始化,根据InittalCapcity值进行初始化操作;若表已初始化,则按照哈希表二倍方式扩容
扩容后进行原表的移动:若桶中结点已经树化,调用树的方式移动元素;若在移动过程中发现红黑树小于等于6,会将红黑树解除树化,还原为链表;若还未树化,则按照链表的方式移动元素
性能:多线程条件下,由于条件竞争,容易造成死锁;rehash是一个较为耗时的过程(在能预估元素个数的前提下,尽量自定义初始化容量,减少reasize个数)
面试题:为何不直接把Object的HashCode返回桶下标
几乎不会发生哈希碰撞,需要桶的个数太多
Hashtable---基于哈希表存储元素
早期版本的Map实现
初始化策略:当产生对象时就将HashMap初始化
线程安全:在get、put、remove等方法上使用内建锁将整个哈希表上锁
使用串行化操作整表,性能较低
面试题:如何优化Hashtable性能?
使用分段锁,将锁细粒度化,将整锁拆成多个锁进行优化
CurrentHashMap
JDK1.7实现
基于分段锁Segment进行实现,每个Segment都是ReentrantLock的子类
结构:将哈希表分为16个Segment,每个Segment下都是一个小的哈希表
关于锁:将原来的整表一把锁细粒度化为每个Segment一把锁,并且不同的Segment之间互不干扰
扩容机制:Segment初始化后无法扩容(默认为16),扩容实际上是对每个Segment的下小的哈希表进行扩容,并且每个哈希表下扩容完全隔离
JDK1.8实现
结构:与JDK1.8中HashMap基本一样,也是哈希表加红黑树,原先的Segment的保留,但是没有什么实际意义,仅仅用作序列化
关于锁:将原先锁一片区域,再次细粒度化,只锁桶中的头结点(使用CAS+同步代码块(synchronized))
面试题1:对比JDK7和JDK8中CurrentHashMap
结构上:JDK7是基于分段锁的Segment;JDK8是哈希表+红黑树
锁的使用:JDK7使用ReentrantLock对Segment上锁;JDK8使用CAS+synchronized代码块
面试题2:为什么JDK8又重新使用synchronize内建锁
在现版本JDK中,内建锁与Lock锁性能上基本差不多,甚至在低竞争场景下优于Lock;使用synchronize可以节省大量的空间,这是相较于ReentrantLock最大的优势
TreeMap
TreeMap是一个可以排序的Map子类,它按照key的内容进行排序
排序依旧是按照Compareable接口完成的
结论:有Compareable接口出现的地方,判断数据就依靠compareTo()方法实现,不再需要equals()和hashcode()

















 156
156

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









