




 本文详细介绍了在Web开发中常见的编码与解码问题,包括浏览器与服务器间的编码不一致导致的乱码现象,以及如何针对GET和POST请求进行正确的编码设置来避免乱码问题。同时,还提供了响应乱码的解决方案。
本文详细介绍了在Web开发中常见的编码与解码问题,包括浏览器与服务器间的编码不一致导致的乱码现象,以及如何针对GET和POST请求进行正确的编码设置来避免乱码问题。同时,还提供了响应乱码的解决方案。
乱码: 中文引起的乱码[GBK: 2字节一个字符 UTF-8: 3字节一个字符 ISO8859-1: 1字节一个字符]
原因: 编码解码格式不统一
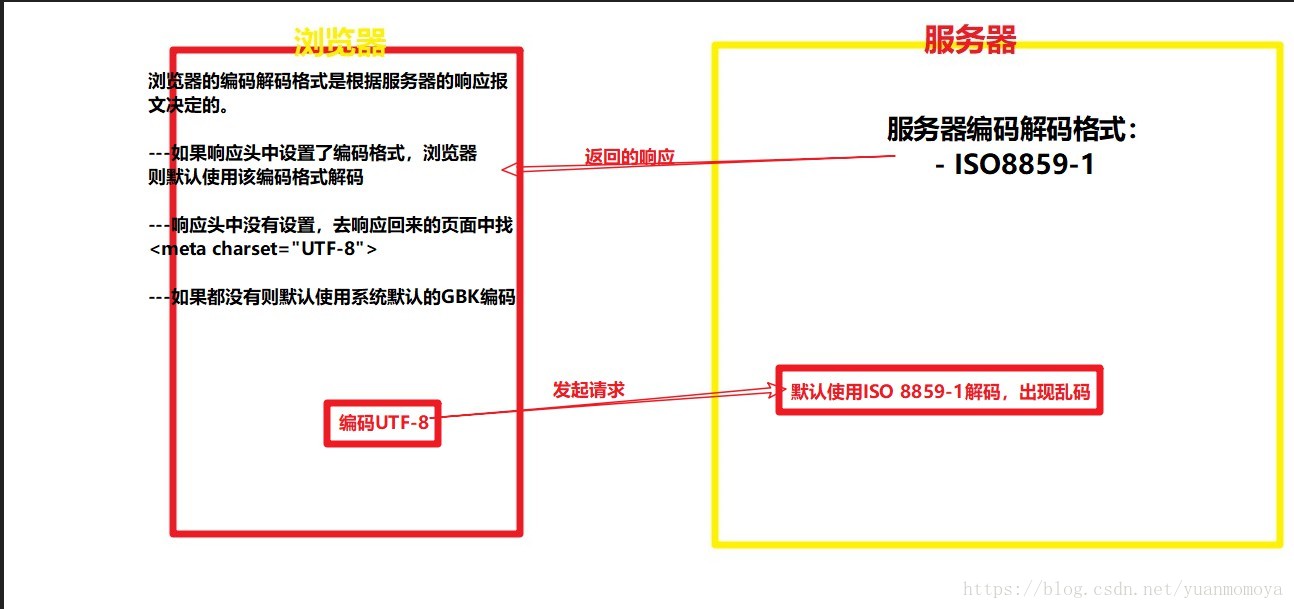
浏览器编码解码格式:
- 如果交给浏览器的响应报文设置了响应编码的响应头,浏览器优先使用
- 如果响应头中没有编码,浏览器则去页面中查找<meta charset="UTF-8">使用
- 如果报文和页面都没有设置编码,浏览器使用系统默认的编码GBK
服务器编码解码格式:
- ISO8859-1
情况
1、请求乱码: 浏览器封装数据(编码)发送给服务器解析(解码)出现乱码
浏览器编码格式:UTF-8
服务器解码格式:ISO8859-1
解决:
无论什么情况都可以解决:方案1: 使用ISO8859-1解析UTF-8出现了乱码 原理,不用
字符串重构
将ISO8859-1乱码字符串通过ISO8859-1还原为字节数组
使用UTF-8重构
byte[] bs = username.getBytes("ISO8859-1");
username = new String(bs, "UTF-8");
GET请求乱码:
方案2: get请求时,请求参数在请求首行的url地址后携带[get请求只能用来携带请求参数]
设置request对象解析请求首行数据的编码即可
在tomcat配置文件:server.xml中 8080端口号所在的标签添加URIEncoding="UTF-8"属性
- 解决了当前工作空间所有请求的中文乱码问题
POST请求乱码:
方案3: post请求时, 请求参数在请求体中携带,设置服务器解析请求体参数的编码[post请求可以上传文件或上传请求参数]
- 没有统一解决的方案,每个Servlet根据自己接受的数据类型单独处理
- 在使用request对象之前设置解码格式:request.setCharacterEncoding("UTF-8");
2、响应乱码: 服务器封装数据(编码)响应给浏览器解析(解码)出现乱码
在Servlet文件中编写中文字符串是UTF-8的编码
response对象是服务器封装使用的,编码格式是ISO8859-1,使用ISO8859-1将UTF-8的数据写入到响应体中[已经出现乱码]
浏览器得到响应报文,没有在响应头中获取到编码格式,也没有在页面中获取编码格式,就使用系统默认的GBK解析ISO8859-1的页面[又乱码了]
解决:
方案1: 不用
1.1 设置response对象的编码格式为UTF-8 :在使用response对象之前
response.setCharacterEncoding("UTF-8");
1.2 设置浏览器的解码格式为UTF-8
方案2: 常用
response.setHeader("Content-Type", "text/html;charset=UTF-8");//相当于设置了response对象的编码和告诉浏览器如何解析响应体内容
response.setContentType("text/html;charset=UTF-8");


















 3310
3310

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











