



最近在爬一个GB2312编码的网站,直接用request库get得到的结果乱码,用postman做个演示:
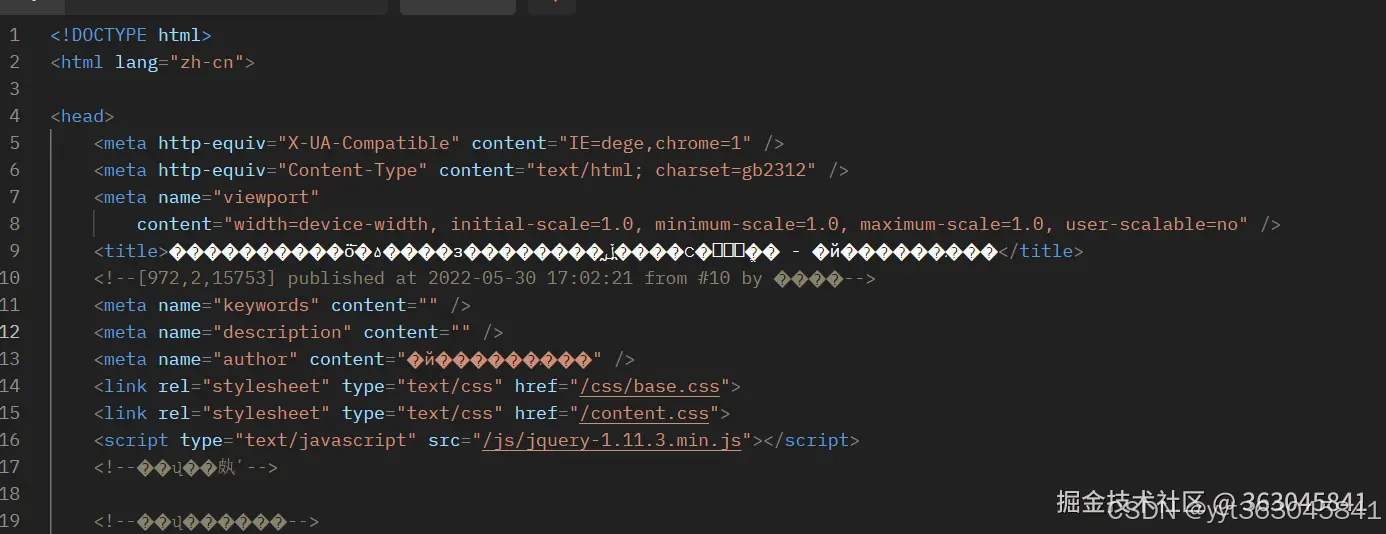
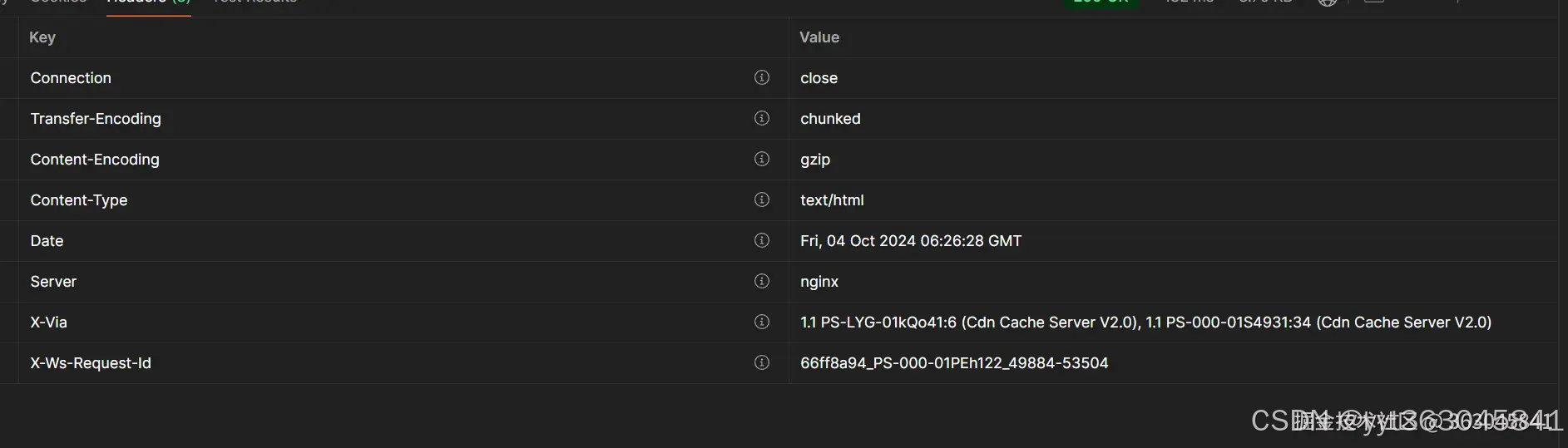
此类网站共性都是响应头没有指定编码类型,导致request库需要猜测编码,还猜错了,详见爬虫工程师,UTF8/GBK/GB2312的乱码让你头疼吗思路打开,解决 Python Requests 库和 Gola - 掘金 (juejin.cn)的分析。
网上搜索这个问题大概率看到的是一个很流行的无厘头方案:
response = requests.get(url=url)
response_code = response.text.encode('iso-8859-1').decode('gbk')
对于大部分网页来说这么做结果好像确实没有问题,但批量爬取总归会有问题,比如说肌这个字在转换过程中就会乱码,导致UnicodeDecodeError异常。
其实解决思路也很简单,在知道猜错的情况下手动指定正确的编码即可:
response.encoding = 'gb2312'
response_code = response.text
至此,问题彻底解决。



















 679
679

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











