




 本文介绍了Word2Vec模型的基本概念,包括词向量的高维特性、训练数据的构建方法、CBOW和Skip-Gram模型的区别,以及负采样在训练过程中的作用。通过对唐宇迪视频的学习,阐述了词向量模型如何将词转化为向量,并讨论了训练数据的多样性和负样本采样对模型训练的影响。
本文介绍了Word2Vec模型的基本概念,包括词向量的高维特性、训练数据的构建方法、CBOW和Skip-Gram模型的区别,以及负采样在训练过程中的作用。通过对唐宇迪视频的学习,阐述了词向量模型如何将词转化为向量,并讨论了训练数据的多样性和负样本采样对模型训练的影响。
这周开始学习word2vec,现在把网课相关内容整理如下:
1、词向量模型
以前统计文本,基本上基于词频,或者TFIDF,面临两个问题:1)两个词调换顺序,但是词频等不变,即改变位置不会影响计算结果;2)词义相近,但会出现截然不同的结果(自然语言处理与NLP被认为是两个词),其实有些词的词义是一致的,在空间上或是向量层面上的表达应该是一致的。
一个词向量的维度通常都是较高的,基本上是50-300维之间的,量的差别导致计算复杂性,计算速度不一。通常,数据的维度越高,能提供的信息也就越多,从而计算结果的可靠性就更值得信赖。
如何来描述语言的特征?通常都在词的层面上构建特征,Word2Vec就是要把词转换成向量。一份训练好的50维的某一个词的词向量大致长这样:其中数值的含义比较难解释,可以类比成降维完的结果也没法解释,计算机认识就行了。

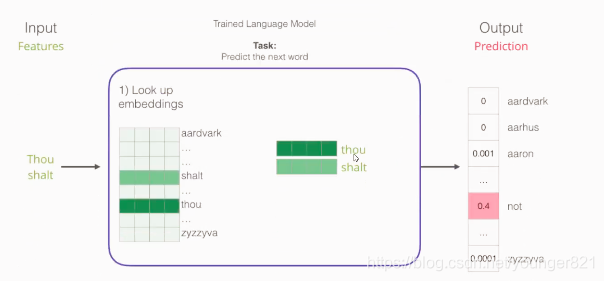
词向量模型中的输入:前后几个词,输出:类似于softmax多分类任务,n个词的概率,概率最大的就是预测词。中间是神经网络
对于输入,在输入神经网络之前是从不限制维数的(下图是4维)很多词的大表(语料库大表)中查找输入词语对应的嵌入向量,大表的每一个词的向量是随机进行初始化(跟神经网络的权重初始化是一样的)。特别的,在word2vec模型计算过程中,前向传播计算损失函数,反向传播通过损失函数更新权重参数矩阵,连输入也会一块更新,也就是每次都会把输入的词向量更新。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 632
632




 到【灌水乐园】发言
到【灌水乐园】发言







