最近考虑到这样一个需求:
需要把原始的日志文件用hadoop做清洗后,按业务线输出到不同的目录下去,以供不同的部门业务线使用。
这个需求需要用到MultipleOutputFormat和MultipleOutputs来实现自定义多目录、文件的输出。
需要注意的是,在hadoop 0.21.x之前和之后的使用方式是不一样的:
hadoop 0.21 之前的API 中有 org.apache.hadoop.mapred.lib.MultipleOutputFormat 和 org.apache.hadoop.mapred.lib.MultipleOutputs,而到了 0.21 之后 的API为 org.apache.hadoop.mapreduce.lib.output.MultipleOutputs ,
新版的API 整合了上面旧API两个的功能,没有了MultipleOutputFormat。
本文将给出新旧两个版本的API code。
1、旧版0.21.x之前的版本:
01 | import java.io.IOException; |
03 | import org.apache.hadoop.conf.Configuration; |
04 | import org.apache.hadoop.conf.Configured; |
05 | import org.apache.hadoop.fs.Path; |
06 | import org.apache.hadoop.io.LongWritable; |
07 | import org.apache.hadoop.io.NullWritable; |
08 | import org.apache.hadoop.io.Text; |
09 | import org.apache.hadoop.mapred.FileInputFormat; |
10 | import org.apache.hadoop.mapred.FileOutputFormat; |
11 | import org.apache.hadoop.mapred.JobClient; |
12 | import org.apache.hadoop.mapred.JobConf; |
13 | import org.apache.hadoop.mapred.MapReduceBase; |
14 | import org.apache.hadoop.mapred.Mapper; |
15 | import org.apache.hadoop.mapred.OutputCollector; |
16 | import org.apache.hadoop.mapred.Reporter; |
17 | import org.apache.hadoop.mapred.TextInputFormat; |
18 | import org.apache.hadoop.mapred.lib.MultipleTextOutputFormat; |
19 | import org.apache.hadoop.util.Tool; |
20 | import org.apache.hadoop.util.ToolRunner; |
22 | public class MultiFile extends Configured implements Tool { |
24 | public static class MapClass extends MapReduceBase implements |
25 | Mapper<LongWritable, Text, NullWritable, Text> { |
28 | public void map(LongWritable key, Text value, |
29 | OutputCollector<NullWritable, Text> output, Reporter reporter) |
31 | output.collect(NullWritable.get(), value); |
38 | public static class PartitionByCountryMTOF extends |
39 | MultipleTextOutputFormat<NullWritable, Text> { |
42 | protected String generateFileNameForKeyValue(NullWritable key, |
43 | Text value, String filename) { |
44 | String[] arr = value.toString().split(",", -1); |
45 | String country = arr[4].substring(1, 3); |
46 | return country + "/" + filename; |
65 | public int run(String[] args) throws Exception { |
66 | Configuration conf = getConf(); |
67 | JobConf job = new JobConf(conf, MultiFile.class); |
69 | Path in = new Path(args[0]); |
70 | Path out = new Path(args[1]); |
72 | FileInputFormat.setInputPaths(job, in); |
73 | FileOutputFormat.setOutputPath(job, out); |
75 | job.setJobName("MultiFile"); |
76 | job.setMapperClass(MapClass.class); |
77 | job.setInputFormat(TextInputFormat.class); |
78 | job.setOutputFormat(PartitionByCountryMTOF.class); |
79 | job.setOutputKeyClass(NullWritable.class); |
80 | job.setOutputValueClass(Text.class); |
82 | job.setNumReduceTasks(0); |
83 | JobClient.runJob(job); |
87 | public static void main(String[] args) throws Exception { |
88 | int res = ToolRunner.run(new Configuration(), new MultiFile(), args); |
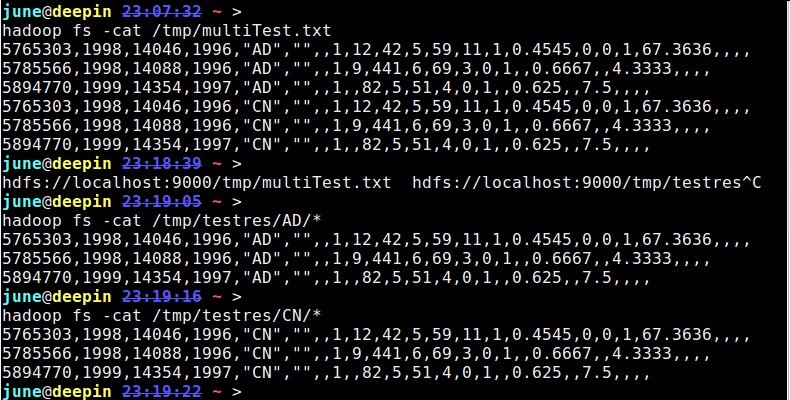
测试数据及结果:
1 | hadoop fs -cat /tmp/multiTest.txt |
2 | 5765303,1998,14046,1996,"AD","",,1,12,42,5,59,11,1,0.4545,0,0,1,67.3636,,,, |
3 | 5785566,1998,14088,1996,"AD","",,1,9,441,6,69,3,0,1,,0.6667,,4.3333,,,, |
4 | 5894770,1999,14354,1997,"AD","",,1,,82,5,51,4,0,1,,0.625,,7.5,,,, |
5 | 5765303,1998,14046,1996,"CN","",,1,12,42,5,59,11,1,0.4545,0,0,1,67.3636,,,, |
6 | 5785566,1998,14088,1996,"CN","",,1,9,441,6,69,3,0,1,,0.6667,,4.3333,,,, |
7 | 5894770,1999,14354,1997,"CN","",,1,,82,5,51,4,0,1,,0.625,,7.5,,,, |
from:
MultipleOutputFormat Example
http://mazd1002.blog.163.com/blog/static/665749652011102553947492/
2、新版0.21.x及之后的版本:
01 | public class TestwithMultipleOutputs extends Configured implements Tool { |
03 | public static class MapClass extends Mapper<LongWritable,Text,Text,IntWritable> { |
05 | private MultipleOutputs<Text,IntWritable> mos; |
07 | protected void setup(Context context) throws IOException,InterruptedException { |
08 | mos = new MultipleOutputs<Text,IntWritable>(context); |
11 | public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException{ |
12 | String line = value.toString(); |
13 | String[] tokens = line.split("-"); |
15 | mos.write("MOSInt",new Text(tokens[0]), new IntWritable(Integer.parseInt(tokens[1]))); |
16 | mos.write("MOSText", new Text(tokens[0]),tokens[2]); |
17 | mos.write("MOSText", new Text(tokens[0]),line,tokens[0]+"/"); |
20 | protected void cleanup(Context context) throws IOException,InterruptedException { |
25 | public int run(String[] args) throws Exception { |
27 | Configuration conf = getConf(); |
29 | Job job = new Job(conf,"word count with MultipleOutputs"); |
31 | job.setJarByClass(TestwithMultipleOutputs.class); |
33 | Path in = new Path(args[0]); |
34 | Path out = new Path(args[1]); |
36 | FileInputFormat.setInputPaths(job, in); |
37 | FileOutputFormat.setOutputPath(job, out); |
39 | job.setMapperClass(MapClass.class); |
40 | job.setNumReduceTasks(0); |
42 | MultipleOutputs.addNamedOutput(job,"MOSInt",TextOutputFormat.class,Text.class,IntWritable.class); |
43 | MultipleOutputs.addNamedOutput(job,"MOSText",TextOutputFormat.class,Text.class,Text.class); |
45 | System.exit(job.waitForCompletion(true)?0:1); |
49 | public static void main(String[] args) throws Exception { |
51 | int res = ToolRunner.run(new Configuration(), new TestwithMultipleOutputs(), args); |
测试的数据:
abc-1232-hdf
abc-123-rtd
ioj-234-grjth
ntg-653-sdgfvd
kju-876-btyun
bhm-530-bhyt
hfter-45642-bhgf
bgrfg-8956-fmgh
jnhdf-8734-adfbgf
ntg-68763-nfhsdf
ntg-98634-dehuy
hfter-84567-drhuk
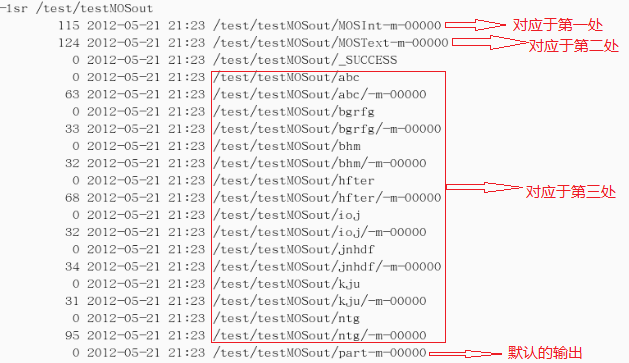
结果截图:(结果输出到/test/testMOSout)





 本文介绍如何使用Hadoop的MultipleOutputFormat特性,根据不同业务线将日志文件清洗后输出到多个目录。提供了0.21.x之前和之后版本的API示例代码。
本文介绍如何使用Hadoop的MultipleOutputFormat特性,根据不同业务线将日志文件清洗后输出到多个目录。提供了0.21.x之前和之后版本的API示例代码。

















 2777
2777

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









