







CUHK-IEMS5730-HW2
Pig Setup & Basic Operations
Pig Latin Script
BookA = load '/Pig_Data/google_book/googlebooks-eng-all-1gram-20120701-a' using PigStorage() as (gram:chararray, year:int, num:int, books:int);
BookB = load '/Pig_Data/google_book/googlebooks-eng-all-1gram-20120701-b' using PigStorage() as (gram:chararray, year:int, num:int, books:int);
--combine two file with same format together
AllBooks = UNION BookA, BookB;
--create {group,tuple(AllBooks)}
Grams = GROUP AllBooks by gram;
--create (group,avgnum)
GramsAvg = foreach Grams generate group, AVG(AllBooks.num) as avgnum;
OrderedGramsAvg = ORDER GramsAvg BY avgnum DESC;
--find top 20
LimitOrderedGramsAvg = LIMIT OrderedGramsAvg 20;
--store them
STORE LimitOrderedGramsAvg into '/Pig_Data/google-out';
Pig Latin Result
and 2.593207744E7
and_CONJ 2.5906234451764707E7
a 1.6665890811764706E7
a_DET 1.6645121127058823E7
as 6179734.075294117
be 5629591.52
be_VERB 5621156.232941177
as_ADP 5360443.872941176
by 5294067.04
by_ADP 5272951.997647059
are 4298564.341176471
are_VERB 4298561.303529412
at 3676050.1529411767
at_ADP 3670625.785882353
an 2979272.7411764706
an_DET 2977977.8870588234
but 2471102.4964705883
but_CONJ 2468978.0564705883
all 2189962.722352941
all_DET 2161257.294117647
Pig Latin Shortcut
I install pig on my own cluster.
Here is the shortcut of the process I run my script-pig.pigcode.
2019-02-22 04:55:01,577 [main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - 100% complete
2019-02-22 04:55:01,608 [main] INFO org.apache.pig.tools.pigstats.mapreduce.SimplePigStats - Script Statistics:
HadoopVersion PigVersion UserId StartedAt FinishedAt Features
2.9.2 0.17.0 tian 2019-02-22 04:47:08 2019-02-22 04:55:01 GROUP_BY,ORDER_BY,LIMIT,UNION
Success!
Job Stats (time in seconds):
JobId Maps Reduces MaxMapTime MinMapTime AvgMapTime MedianMapTime MaxReduceTime MinReduceTime AvgReduceTime MedianReducetime Alias Feature Outputs
job_1550810684179_0001 24 4 360 158 287 302 202 139 171 171 AllBooks,BookA,BookB,Grams,GramsAvg GROUP_BY,COMBINER
job_1550810684179_0002 1 1 5 5 5 5 4 4 4 4 OrderedGramsAvg SAMPLER
job_1550810684179_0003 1 1 13 13 13 13 4 4 4 4 OrderedGramsAvg ORDER_BY,COMBINER
job_1550810684179_0004 1 1 4 4 4 4 4 4 4 4 OrderedGramsAvg /Pig_Data/google-out,
Input(s):
Successfully read 61551917 records from: "/Pig_Data/google_book/googlebooks-eng-all-1gram-20120701-b"
Successfully read 86618505 records from: "/Pig_Data/google_book/googlebooks-eng-all-1gram-20120701-a"
Output(s):
Successfully stored 20 records (466 bytes) in: "/Pig_Data/google-out"
Counters:
Total records written : 20
Total bytes written : 466
Spillable Memory Manager spill count : 0
Total bags proactively spilled: 0
Total records proactively spilled: 0
Job DAG:
job_1550810684179_0001 -> job_1550810684179_0002,
job_1550810684179_0002 -> job_1550810684179_0003,
job_1550810684179_0003 -> job_1550810684179_0004,
job_1550810684179_0004
Hive Setup & Basic Operations
Hive Script
CREATE TABLE m (gram STRING, year INT, freq INT, bks INT)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS TEXTFILE;
CREATE TABLE n (gram STRING, year INT, freq INT, bks INT)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS TEXTFILE;
LOAD DATA LOCAL INPATH '/home/tian/hw2-book/googlebooks-eng-all-1gram-20120701-a' INTO TABLE m;
LOAD DATA LOCAL INPATH '/home/tian/hw2-book/googlebooks-eng-all-1gram-20120701-b' INTO TABLE n;
CREATE TABLE mn AS SELECT * FROM( SELECT * FROM m UNION ALL SELECT * FROM n) tmp;
CREATE TABLE h AS SELECT gram, AVG(freq) AS avgf FROM mn GROUP BY gram;
CREATE TABLE resu AS SELECT gram, avgf FROM h SORT BY avgf DESC LIMIT 20;
Hive Result
and 2.593207744E7
and_CONJ 2.5906234451764707E7
a 1.6665890811764706E7
a_DET 1.6645121127058823E7
as 6179734.075294117
be 5629591.52
be_VERB 5621156.232941177
as_ADP 5360443.872941176
by 5294067.04
by_ADP 5272951.997647059
are 4298564.341176471
are_VERB 4298561.303529412
at 3676050.1529411767
at_ADP 3670625.785882353
an 2979272.7411764706
an_DET 2977977.8870588234
but 2471102.4964705883
but_CONJ 2468978.0564705883
all 2189962.722352941
all_DET 2161257.294117647
Hive Process Shortcuts
Here is the shortcut of my execution of hive-script.sql.
tian@master:~/hw2-src$ hive -f hive-script.sql
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/home/tian/apache-hive-2.3.4-bin/lib/log4j-slf4j-impl-2.6.2.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/home/tian/hadoop-2.9.2/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Logging initialized using configuration in jar:file:/home/tian/apache-hive-2.3.4-bin/lib/hive-common-2.3.4.jar!/hive-log4j2.properties Async: true
OK
Time taken: 5.865 seconds
OK
Time taken: 0.089 seconds
Loading data to table default.m
OK
Time taken: 26.258 seconds
Loading data to table default.n
OK
Time taken: 21.387 seconds
WARNING: Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. tez, spark) or using Hive 1.X releases.
Query ID = tian_20190227064543_b9a91e25-513b-48ad-956c-b8cbf93233ab
Total jobs = 3
Launching Job 1 out of 3
Number of reduce tasks is set to 0 since there's no reduce operator
Starting Job = job_1551243260951_0010, Tracking URL = http://master:8088/proxy/application_1551243260951_0010/
Kill Command = /home/tian/hadoop-2.9.2/bin/hadoop job -kill job_1551243260951_0010
Hadoop job information for Stage-1: number of mappers: 12; number of reducers: 0
2019-02-27 06:45:58,187 Stage-1 map = 0%, reduce = 0%
2019-02-27 06:46:30,970 Stage-1 map = 17%, reduce = 0%, Cumulative CPU 128.91 sec
2019-02-27 06:46:45,848 Stage-1 map = 21%, reduce = 0%, Cumulative CPU 224.61 sec
2019-02-27 06:46:51,078 Stage-1 map = 33%, reduce = 0%, Cumulative CPU 261.16 sec
2019-02-27 06:46:55,189 Stage-1 map = 38%, reduce = 0%, Cumulative CPU 269.82 sec
2019-02-27 06:47:01,350 Stage-1 map = 46%, reduce = 0%, Cumulative CPU 291.8 sec
2019-02-27 06:47:02,381 Stage-1 map = 56%, reduce = 0%, Cumulative CPU 297.34 sec
2019-02-27 06:47:03,417 Stage-1 map = 70%, reduce = 0%, Cumulative CPU 305.42 sec
2019-02-27 06:47:12,805 Stage-1 map = 73%, reduce = 0%, Cumulative CPU 331.99 sec
2019-02-27 06:47:20,104 Stage-1 map = 75%, reduce = 0%, Cumulative CPU 362.98 sec
2019-02-27 06:47:22,193 Stage-1 map = 79%, reduce = 0%, Cumulative CPU 365.03 sec
2019-02-27 06:47:23,231 Stage-1 map = 83%, reduce = 0%, Cumulative CPU 367.84 sec
2019-02-27 06:47:24,267 Stage-1 map = 88%, reduce = 0%, Cumulative CPU 370.9 sec
2019-02-27 06:47:25,302 Stage-1 map = 92%, reduce = 0%, Cumulative CPU 377.44 sec
2019-02-27 06:47:27,383 Stage-1 map = 96%, reduce = 0%, Cumulative CPU 383.32 sec
2019-02-27 06:47:28,436 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 384.65 sec
MapReduce Total cumulative CPU time: 6 minutes 24 seconds 650 msec
Ended Job = job_1551243260951_0010
Stage-4 is selected by condition resolver.
Stage-3 is filtered out by condition resolver.
Stage-5 is filtered out by condition resolver.
Moving data to directory hdfs://master:9000/user/hive/warehouse/.hive-staging_hive_2019-02-27_06-45-44_021_3835967977717187098-1/-ext-10002
Moving data to directory hdfs://master:9000/user/hive/warehouse/mn
MapReduce Jobs Launched:
Stage-Stage-1: Map: 12 Cumulative CPU: 384.65 sec HDFS Read: 3070067861 HDFS Write: 3069919955 SUCCESS
Total MapReduce CPU Time Spent: 6 minutes 24 seconds 650 msec
OK
Time taken: 106.954 seconds
WARNING: Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. tez, spark) or using Hive 1.X releases.
Query ID = tian_20190227064730_73ab0cb9-3130-4861-b9a2-e82a15026048
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks not specified. Estimated from input data size: 12
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1551243260951_0011, Tracking URL = http://master:8088/proxy/application_1551243260951_0011/
Kill Command = /home/tian/hadoop-2.9.2/bin/hadoop job -kill job_1551243260951_0011
Hadoop job information for Stage-1: number of mappers: 12; number of reducers: 12
2019-02-27 06:47:41,225 Stage-1 map = 0%, reduce = 0%
2019-02-27 06:48:04,354 Stage-1 map = 8%, reduce = 0%, Cumulative CPU 63.07 sec
2019-02-27 06:48:16,308 Stage-1 map = 11%, reduce = 0%, Cumulative CPU 125.09 sec
2019-02-27 06:48:17,390 Stage-1 map = 19%, reduce = 0%, Cumulative CPU 133.0 sec
2019-02-27 06:48:18,494 Stage-1 map = 28%, reduce = 0%, Cumulative CPU 139.78 sec
2019-02-27 06:48:23,912 Stage-1 map = 31%, reduce = 0%, Cumulative CPU 156.86 sec
2019-02-27 06:48:33,497 Stage-1 map = 36%, reduce = 0%, Cumulative CPU 195.17 sec
2019-02-27 06:48:34,597 Stage-1 map = 38%, reduce = 0%, Cumulative CPU 198.76 sec
2019-02-27 06:48:38,832 Stage-1 map = 44%, reduce = 0%, Cumulative CPU 233.92 sec
2019-02-27 06:48:39,882 Stage-1 map = 48%, reduce = 1%, Cumulative CPU 238.15 sec
2019-02-27 06:48:40,909 Stage-1 map = 59%, reduce = 3%, Cumulative CPU 245.58 sec
2019-02-27 06:48:41,937 Stage-1 map = 59%, reduce = 5%, Cumulative CPU 246.6 sec
2019-02-27 06:48:42,962 Stage-1 map = 59%, reduce = 6%, Cumulative CPU 254.01 sec
2019-02-27 06:48:43,990 Stage-1 map = 59%, reduce = 7%, Cumulative CPU 254.2 sec
2019-02-27 06:48:45,014 Stage-1 map = 59%, reduce = 9%, Cumulative CPU 257.76 sec
2019-02-27 06:48:46,040 Stage-1 map = 59%, reduce = 10%, Cumulative CPU 265.45 sec
2019-02-27 06:48:49,114 Stage-1 map = 73%, reduce = 11%, Cumulative CPU 231.93 sec
2019-02-27 06:48:50,143 Stage-1 map = 73%, reduce = 13%, Cumulative CPU 232.05 sec
2019-02-27 06:48:51,170 Stage-1 map = 73%, reduce = 14%, Cumulative CPU 232.1 sec
2019-02-27 06:48:52,194 Stage-1 map = 76%, reduce = 17%, Cumulative CPU 235.93 sec
2019-02-27 06:48:53,218 Stage-1 map = 78%, reduce = 21%, Cumulative CPU 240.46 sec
2019-02-27 06:48:54,242 Stage-1 map = 78%, reduce = 24%, Cumulative CPU 240.62 sec
2019-02-27 06:48:55,266 Stage-1 map = 78%, reduce = 25%, Cumulative CPU 240.67 sec
2019-02-27 06:48:56,308 Stage-1 map = 83%, reduce = 25%, Cumulative CPU 243.76 sec
2019-02-27 06:48:57,357 Stage-1 map = 83%, reduce = 28%, Cumulative CPU 244.21 sec
2019-02-27 06:48:58,420 Stage-1 map = 83%, reduce = 33%, Cumulative CPU 245.35 sec
2019-02-27 06:48:59,477 Stage-1 map = 83%, reduce = 34%, Cumulative CPU 245.47 sec
2019-02-27 06:49:02,677 Stage-1 map = 83%, reduce = 39%, Cumulative CPU 253.11 sec
2019-02-27 06:49:03,728 Stage-1 map = 83%, reduce = 43%, Cumulative CPU 257.21 sec
2019-02-27 06:49:04,772 Stage-1 map = 83%, reduce = 46%, Cumulative CPU 258.67 sec
2019-02-27 06:49:07,846 Stage-1 map = 86%, reduce = 46%, Cumulative CPU 274.83 sec
2019-02-27 06:49:08,868 Stage-1 map = 89%, reduce = 46%, Cumulative CPU 291.25 sec
2019-02-27 06:49:10,914 Stage-1 map = 94%, reduce = 46%, Cumulative CPU 294.89 sec
2019-02-27 06:49:11,937 Stage-1 map = 94%, reduce = 47%, Cumulative CPU 294.99 sec
2019-02-27 06:49:13,980 Stage-1 map = 100%, reduce = 47%, Cumulative CPU 299.76 sec
2019-02-27 06:49:15,002 Stage-1 map = 100%, reduce = 50%, Cumulative CPU 300.14 sec
2019-02-27 06:49:16,025 Stage-1 map = 100%, reduce = 57%, Cumulative CPU 302.31 sec
2019-02-27 06:49:17,064 Stage-1 map = 100%, reduce = 63%, Cumulative CPU 306.28 sec
2019-02-27 06:49:18,092 Stage-1 map = 100%, reduce = 72%, Cumulative CPU 312.72 sec
2019-02-27 06:49:19,118 Stage-1 map = 100%, reduce = 78%, Cumulative CPU 316.69 sec
2019-02-27 06:49:20,144 Stage-1 map = 100%, reduce = 83%, Cumulative CPU 323.92 sec
2019-02-27 06:49:21,173 Stage-1 map = 100%, reduce = 86%, Cumulative CPU 323.92 sec
2019-02-27 06:49:22,198 Stage-1 map = 100%, reduce = 92%, Cumulative CPU 333.92 sec
2019-02-27 06:49:23,220 Stage-1 map = 100%, reduce = 93%, Cumulative CPU 336.87 sec
2019-02-27 06:49:24,245 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 343.92 sec
MapReduce Total cumulative CPU time: 5 minutes 43 seconds 920 msec
Ended Job = job_1551243260951_0011
Moving data to directory hdfs://master:9000/user/hive/warehouse/h
MapReduce Jobs Launched:
Stage-Stage-1: Map: 12 Reduce: 12 Cumulative CPU: 343.92 sec HDFS Read: 3070070067 HDFS Write: 68316915 SUCCESS
Total MapReduce CPU Time Spent: 5 minutes 43 seconds 920 msec
OK
Time taken: 114.701 seconds
WARNING: Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. tez, spark) or using Hive 1.X releases.
Query ID = tian_20190227064925_d9f709b2-0b33-4f5f-a767-a88f3c8b7318
Total jobs = 2
Launching Job 1 out of 2
Number of reduce tasks not specified. Estimated from input data size: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1551243260951_0012, Tracking URL = http://master:8088/proxy/application_1551243260951_0012/
Kill Command = /home/tian/hadoop-2.9.2/bin/hadoop job -kill job_1551243260951_0012
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
2019-02-27 06:49:32,805 Stage-1 map = 0%, reduce = 0%
2019-02-27 06:49:45,116 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 9.06 sec
2019-02-27 06:49:51,271 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 10.28 sec
MapReduce Total cumulative CPU time: 10 seconds 280 msec
Ended Job = job_1551243260951_0012
Launching Job 2 out of 2
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1551243260951_0013, Tracking URL = http://master:8088/proxy/application_1551243260951_0013/
Kill Command = /home/tian/hadoop-2.9.2/bin/hadoop job -kill job_1551243260951_0013
Hadoop job information for Stage-2: number of mappers: 1; number of reducers: 1
2019-02-27 06:50:00,277 Stage-2 map = 0%, reduce = 0%
Storm Cluster Setup & Word Count
Storm Three Node Cluster Setup
Here is the shortcut of my three nodes storm cluster.
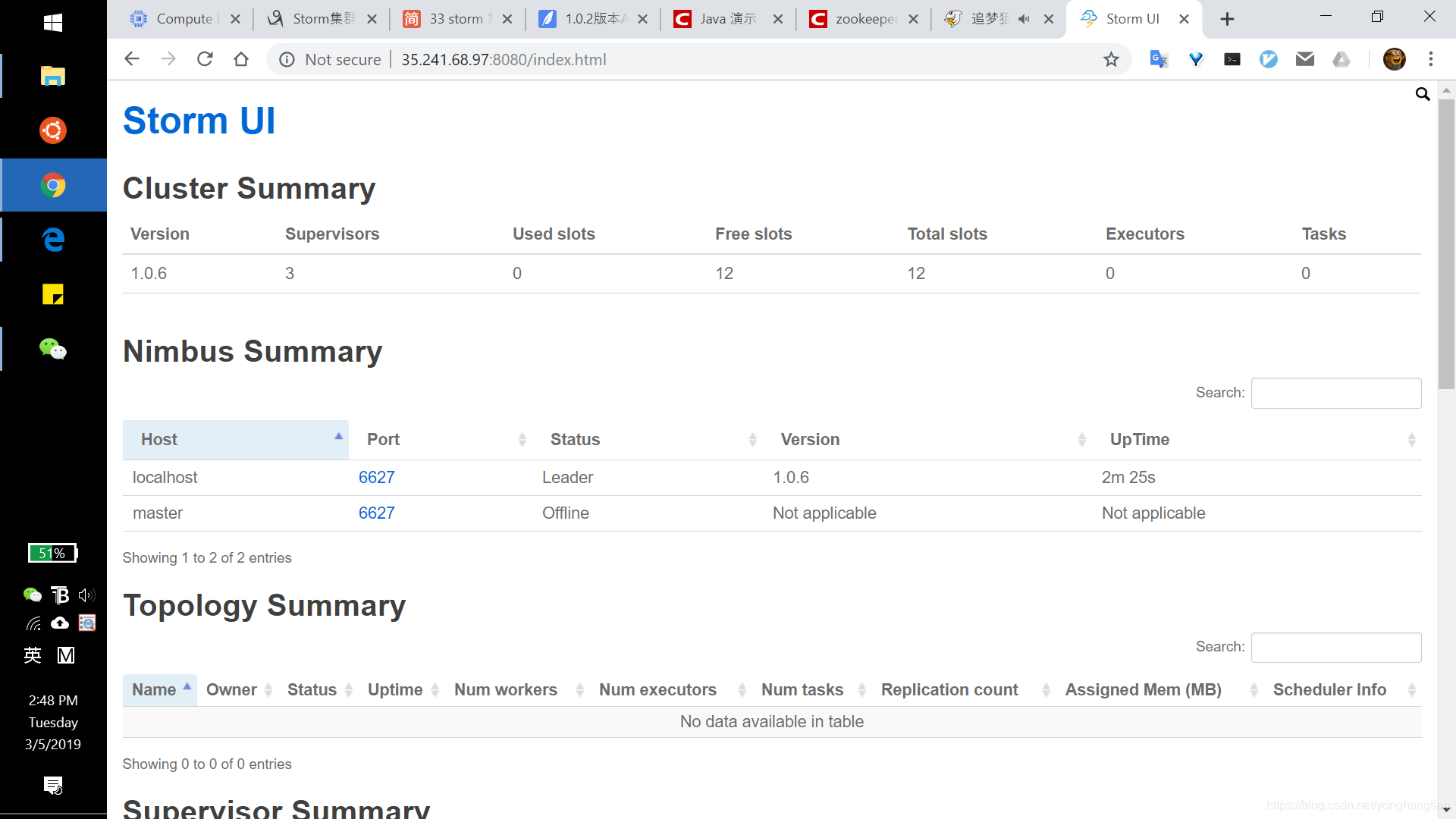
Storm Word Count
I did not finish this job since I can not figure out how to execute the cleanup method in local cluster and don’t know where is the output of the real cluster.
I get the source from the Internet, and edit it by myself.
Here is the source code of WordCountTopology.java:
import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.StormSubmitter;
import org.apache.storm.shade.com.google.common.collect.Maps;
import org.apache.storm.spout.SpoutOutputCollector;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.TopologyBuilder;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.topology.base.BaseRichSpout;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
import java.io.BufferedReader;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.IOException;
import java.util.Collections;
import java.util.Comparator;
import java.util.Map;
import java.util.ArrayList;
public class WordCountTopology {
/**
*
* 编写spout ,继承一个基类,负责从数据源获取数据
* @author bill
* @date 2017年9月16日 下午8:21:46
*/
public static class RandomSentenceSpout extends BaseRichSpout {
private SpoutOutputCollector collector;
private FileReader fr;
private boolean completed = false;
/**
* 当一个Task被初始化的时候会调用此open方法,
* 一般都会在此方法中对发送Tuple的对象SpoutOutputCollector和配置对象TopologyContext初始化
*/
@Override
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
this.collector = collector;
try{
this.fr = new FileReader(conf.get("wordsFile").toString());
} catch (FileNotFoundException e) {
throw new RuntimeException("Error reading file ["+ conf.get("wordsFile")+"]");
}
}
/**
* 这个spout类,之前说过,最终会运行在task中,某个worker进程的某个executor线程内部的某个task中
* 那个task会负责去不断的无限循环调用nextTuple()方法
* 只要的话呢,无限循环调用,可以不断发射最新的数据出去,形成一个数据流
*/
@Override
public void nextTuple() {
if (completed) {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
}
return;
}
BufferedReader br = new BufferedReader(fr);
String str ;
try {
while((str = br.readLine()) != null){
this.collector.emit(new Values(str));
}
} catch (IOException e) {
e.printStackTrace();
}
// 这个values,你可以认为就是构建一个tuple,tuple是最小的数据单位,无限个tuple组成的流就是一个stream,通过 emit 发送数据到下游bolt tuple
}
/**
* 用于声明当前Spout的Tuple发送流的域名字。Stream流的定义是通过OutputFieldsDeclare.declareStream方法完成的
* 通俗点说法:就是这个方法是定义一个你发射出去的每个tuple中的每个field的名称是什么,作为下游
bolt 中 execute 接收数据 key
*/
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("sentence"));
}
}
/**
*
* 编写一个bolt,用于切分每个单词,同时把单词发送出去
* @author bill
* @date 2017年9月16日 下午8:27:45
*/
public static class SplitSentenceBolt extends BaseRichBolt {
private OutputCollector collector;
/**
* 当一个Task被初始化的时候会调用此prepare方法,对于bolt来说,第一个方法,就是prepare方法
* OutputCollector,这个也是Bolt的这个tuple的发射器,一般都会在此方法中对发送Tuple的对象OutputCollector初始化
*/
@Override
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
}
/**
* 这是Bolt中最关键的一个方法,对于Tuple的处理都可以放到此方法中进行。具体的发送也是通过emit方法来完成的
* 就是说,每次接收到一条数据后,就会交给这个executor方法来执行
* 切分单词
*/
@Override
public void execute(Tuple input) {
// 接收上游数据
String sentence = input.getStringByField("sentence");
String[] words = sentence.split(" ");
for(String word : words){
word = word.trim();
if (!word.isEmpty()){
//发射数据
this.collector.emit(new Values(word));
}
}
}
/**
* 用于声明当前bolt的Tuple发送流的域名字。Stream流的定义是通过OutputFieldsDeclare.declareStream方法完成的
* 通俗点说法:就是这个方法是定义一个你发射出去的每个tuple中的每个field的名称是什么,作为下游 bolt 中 execute 接收数据 key
* 定义发射出去的tuple,每个field的名称
*/
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}
}
/**
*
* 单词次数统计bolt
* @author bill
* @date 2017年9月16日 下午8:35:00
*/
public static class WordCountBolt extends BaseRichBolt{
private OutputCollector collector;
Map<String,Long> countMap = Maps.newConcurrentMap();
/**
* 当一个Task被初始化的时候会调用此prepare方法,对于bolt来说,第一个方法,就是prepare方法
* OutputCollector,这个也是Bolt的这个tuple的发射器,一般都会在此方法中对发送Tuple的对象OutputCollector初始化
*/
@Override
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
}
/**
* 这是Bolt中最关键的一个方法,对于Tuple的处理都可以放到此方法中进行。具体的发送也是通过emit方法来完成的
* 就是说,每次接收到一条数据后,就会交给这个executor方法来执行
* 统计单词
*/
@Override
public void execute(Tuple input) {
// 接收上游数据
String word = input.getStringByField("word");
Long count = countMap.get(word);
if(null == count){
count = 0L;
}
count ++;
countMap.put(word, count);
//发射数据
//System.out.println(word +"\t"+count);
this.collector.emit(new Values(word,count));
}
@Override
public void cleanup(){
ArrayList<Map.Entry<String,Long>> list = new ArrayList<>(countMap.entrySet());
Collections.sort(list, new Comparator<Map.Entry<String, Long>>() {
@Override
public int compare(Map.Entry<String, Long> o1, Map.Entry<String, Long> o2) {
return o1.getValue().compareTo(o2.getValue());
}
});
for (int i = 0; i < 10; i ++){
Map.Entry<String,Long> elem = list.get(i);
System.out.println(elem.getKey()+"\t"+elem.getValue());
}
}
/**
* 用于声明当前bolt的Tuple发送流的域名字。Stream流的定义是通过OutputFieldsDeclare.declareStream方法完成的
* 通俗点说法:就是这个方法是定义一个你发射出去的每个tuple中的每个field的名称是什么,作为下游 bolt 中 execute 接收数据 key
* 定义发射出去的tuple,每个field的名称
*/
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word","count"));
}
}
public static void main(String[] args) throws InterruptedException {
//去将spout和bolts组合起来,构建成一个拓扑
TopologyBuilder builder = new TopologyBuilder();
// 第一个参数的意思,就是给这个spout设置一个名字
// 第二个参数的意思,就是创建一个spout的对象
// 第三个参数的意思,就是设置spout的executor有几个
builder.setSpout("RandomSentence", new RandomSentenceSpout(), 2);
builder.setBolt("SplitSentence", new SplitSentenceBolt(), 5)
//为bolt 设置 几个task
.setNumTasks(10)
//设置流分组策略
.shuffleGrouping("RandomSentence");
// fieldsGrouping 这个很重要,就是说,相同的单词,从SplitSentenceSpout发射出来时,一定会进入到下游的指定的同一个task中
// 只有这样子,才能准确的统计出每个单词的数量
// 比如你有个单词,hello,下游task1接收到3个hello,task2接收到2个hello
// 通过fieldsGrouping 可以将 5个hello,全都进入一个task
builder.setBolt("wordCount", new WordCountBolt(), 10)
//为bolt 设置 几个task
.setNumTasks(20)
//设置流分组策略
.fieldsGrouping("SplitSentence", new Fields("word"));
// 运行配置项
Config config = new Config();
/*
* 要想提高storm的并行度可以从三个方面来改造
* worker(进程)>executor(线程)>task(实例)
* 增加work进程,增加executor线程,增加task实例
* 对应 supervisor.slots.port 中配置个数
* 这里可以动态设置使用个数
* 最好一台机器上的一个topology只使用一个worker,主要原因时减少了worker之间的数据传输
*
* 注意:如果worker使用完的话再提交topology就不会执行,因为没有可用的worker,只能处于等待状态,把之前运行的topology停止一个之后这个就会继续执行了
*/
if (args != null && args.length > 0 ){
config.setNumWorkers(3);
try {
// 将Topolog提交集群
StormSubmitter.submitTopology(args[0], config, builder.createTopology());
} catch (Exception e) {
e.printStackTrace();
}
}
else{
config.setDebug(true);
config.setMaxTaskParallelism(3);
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("word-count",config,builder.createTopology());
Thread.sleep(10000);
cluster.shutdown();
}
}
}

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









