




 本文深入探讨了CPU缓存架构,重点解释了什么是伪共享(False Sharing)及其对多线程性能的影响。通过填充、创建独立对象和使用Java 8的@sun.misc.Contended注解等方法,可以有效避免伪共享,从而提高程序效率。
本文深入探讨了CPU缓存架构,重点解释了什么是伪共享(False Sharing)及其对多线程性能的影响。通过填充、创建独立对象和使用Java 8的@sun.misc.Contended注解等方法,可以有效避免伪共享,从而提高程序效率。
前言
学习的过程中遇到了一个名词——“伪共享”,出于对知识的兴趣,上网查阅了一些博文,研究了“伪共享”的问题,写此文章总结记录。
要很好的理解伪共享问题,我们要先从CPU的缓存开始说起。
CPU缓存架构
CPU 是计算机的心脏,所有运算和程序最终都要由它来执行。
主内存(RAM)是数据存放的地方,CPU 和主内存之间有好几级缓存,因为即使直接访问主内存也是非常慢的。
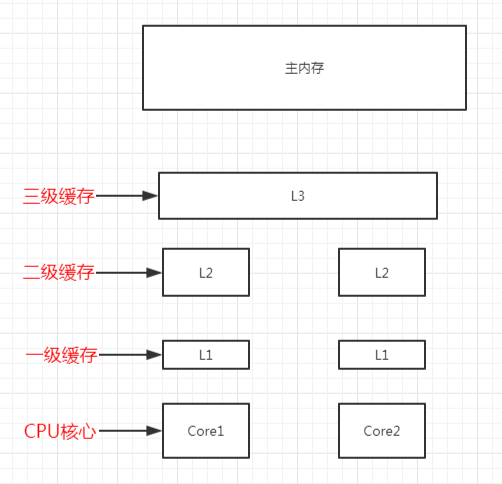
如果对一块数据做相同的运算多次,那么在执行运算的时候把它加载到离 CPU 很近的地方就有意义了,比如一个循环计数,你不想每次循环都跑到主内存去取这个数据来增长它吧。
再对缓存的概念做一些说明:
越靠近 CPU 的缓存越快也越小。
所以 L1 缓存很小但很快,并且紧靠着在使用它的 CPU 内核。
L2 大一些,也慢一些,并且仍然只能被一个单独的 CPU 核使用。
L3 在现代多核机器中更普遍,仍然更大,更慢,并且被单个插槽上的所有 CPU 核共享。
最后,主存保存着程序运行的所有数据,它更大,更慢,由全部插槽上的所有 CPU 核共享。
当 CPU 执行运算的时候,它先去 L1 查找所需的数据,再去 L2,然后是 L3,最后如果这些缓存中都没有,所需的数据就要去主内存拿。
走得越远,运算耗费的时间就越长。
所以如果进行一些很频繁的运算,要确保数据在 L1 缓存中。
CPU缓存行
缓存是由缓存行组成的,通常是 64 字节(常用处理器的缓存行是 64 字节的,比较旧的处理器缓存行是 32 字节),并且它有效地引用主内存中的一块地址。
一个 Java 的 long 类型是 8 字节,因此在一个缓存行中可以存 8 个 long 类型的变量。
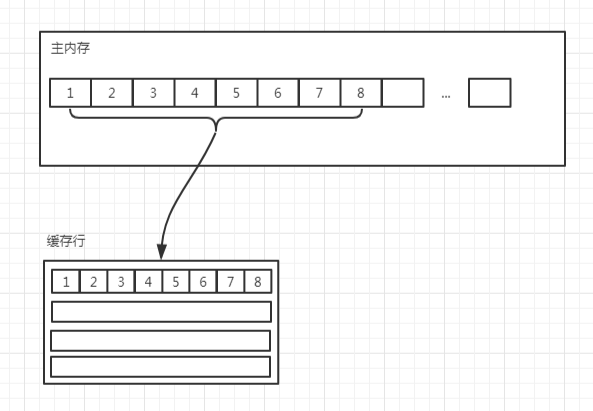
在程序运行的过程中,缓存每次更新都从主内存中加载连续的 64 个字节。因此,如果访问一个 long 类型的数组时,当数组中的一个值被加载到缓存中时,另外 7 个元素也会被加载到缓存中。
但是,如果使用的数据结构中的项在内存中不是彼此相邻的,比如链表,那么将得不到免费缓存加载带来的好处。
不过,这种免费加载也有一个坏处。设想如果我们有个 long 类型的变量 a,它不是数组的一部分,而是一个单独的变量,并且还有另外一个 long 类型的变量 b 紧挨着它,那么当加载 a 的时候将免费加载 b。
看起来似乎没有什么毛病,但是如果一个 CPU 核心的线程在对 a 进行修改,另一个 CPU 核心的线程却在对 b 进行读取。
当前者修改 a 时,会把 a 和 b 同时加载到前者核心的缓存行中,更新完 a 后其它所有包含 a 的缓存行都将失效,因为其它缓存中的 a 不是最新值了。
而当后者读取 b 时,发现这个缓存行已经失效了,需要从主内存中重新加载。
请记住,我们的缓存都是以缓存行作为一个单位来处理的,所以失效 a 的缓存的同时,也会把 b 失效,反之亦然。
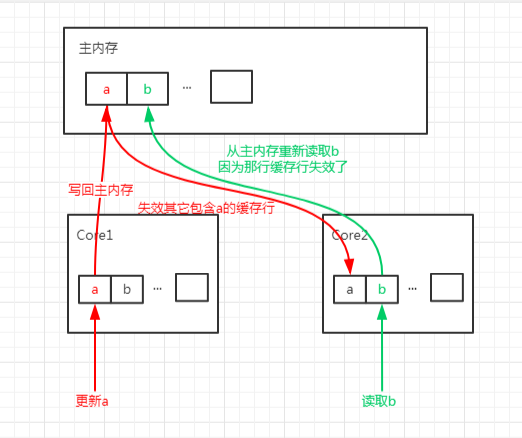
这样就出现了一个问题,b 和 a 完全不相干,每次却要因为 a 的更新需要从主内存重新读取,它被缓存未命中给拖慢了。
这就是传说中的伪共享。
何为伪共享(False Sharing)
从上面我们的原理讲解中,对伪共享有了理性的认识。
这里我们先给伪共享下个定义:
当多线程修改互相独立的变量时,如果这些变量共享同一个缓存行,就会无意中影响彼此的性能,这就是伪共享。
我们从一个例子来看"伪共享"产生的作用:
public class FalseSharingTest {
public static void main(String[] args) throws InterruptedException {
testP 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1137
1137



 到【灌水乐园】发言
到【灌水乐园】发言









