




前言
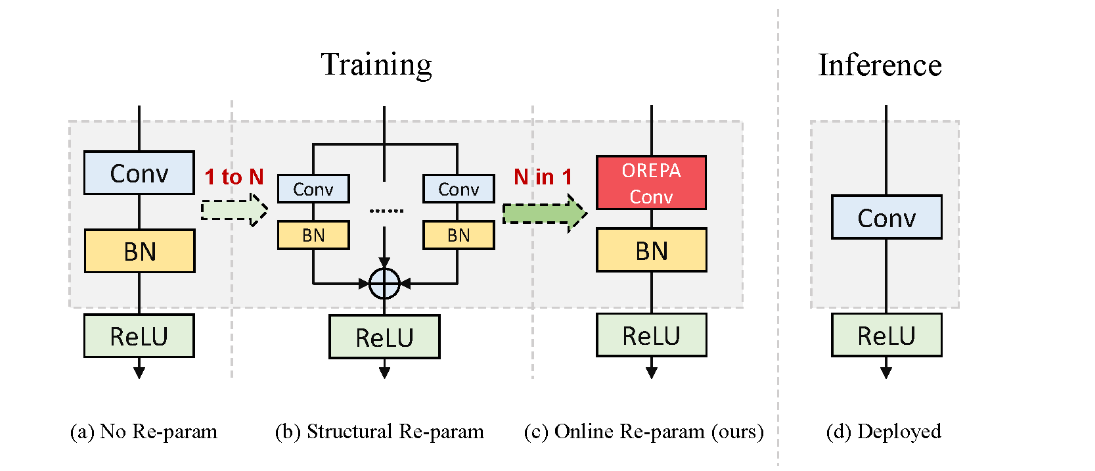
本文介绍了在线卷积重参数化(OREPA)及其在 YOLOv11 中的结合。结构重新参数化能在推理时优化模型性能,但训练成本高。OREPA 是两阶段流程,通过引入线性缩放层优化在线块,将复杂训练块压缩为单个卷积,减少训练开销。其包括块线性化和块压缩步骤,还探索了更有效的重参数化组件。与先进重参数化模型相比,OREPA 减少约 70%训练时间内存开销,加快约 2 倍训练速度,在 ImageNet 上表现提升最多 +0.6%。我们将 OREPA 集成进 YOLOv11,实验显示对下游任务有一致改进。
文章目录: YOLOv11改进大全:卷积层、轻量化、注意力机制、损失函数、Backbone、SPPF、Neck、检测头全方位优化汇总-优快云博客
专栏链接: YOLOv11改进专栏
文章目录
介绍

摘要
结构重参数化在各类计算机视觉任务中受到了越来越多的关注,其目的在于提升深度模型的性能,同时不增加任何推理时间成本。尽管这些模型在推理过程中具有较高的效率,但在复杂的训练阶段,它们依赖复杂的训练块来实现高准确性,这导致产生了额外的大量训练成本。本文介绍了在线卷积重参数化(OREPA),这是一个两阶段的流程,旨在通过将复杂的训练阶段块压缩为单个卷积,以减少高昂的训练开销。为达成这一目标,我们引入了一个线性缩放层,以便更好地优化在线块。在降低训练成本的同时,我们还对一些更有效的重参数化组件进行了探索。与最先进的重参数化模型相比,OREPA能够减少约70%的训练时间内存开销,并使训练速度加快约2倍。同时,配备OREPA的这些模型在ImageNet上的表现超越了以往的方法,准确率最多提高了0.6%。我们还在目标检测和语义分割任务上开展了实验,结果显示对下游任务有一致的改进效果。相关代码可在https://github.com/JUGGHM/OREPA_CVPR2022获取。
文章链接
论文地址:论文地址
代码地址:代码地址
基本原理
什么是结构重新参数化?
结构重新参数化是一种在神经网络训练和推理阶段优化模型性能的方法。其基本思想是通过在训练阶段使用复杂的、多分支的网络结构来提高模型的表达能力和性能,而在推理阶段将这些复杂结构重新参数化为更简单的等效结构,以减少计算开销和存储需求。
具体来说,结构重新参数化通常涉及以下几个步骤:
-
训练阶段:
- 使用复杂的网络结构进行训练。例如,一个卷积层可能被替换为多个并行的卷积层和跳跃连接(shortcut connections),以增强模型的表达能力和学习能力。
- 这种复杂的结构能够捕捉更多的特征,帮助模型在训练过程中更好地拟合数据。
-
重新参数化:
- 在训练完成后,将复杂的多分支结构转换为一个等效的简单结构。例如,将多个并行的卷积层的权重和偏置合并到一个单独的卷积层中。
- 这种转换是通过数学方法和等效变换实现的,确保在推理阶段模型的输出不变。
-
推理阶段:
- 使用重新参数化后的简单结构进行推理。由于结构更简单,推理的计算效率更高,延迟更低,所需的存储资源也更少。
- 这种优化对于部署在资源受限的设备(如移动设备)上的模型尤其有用。
结构重新参数化的一种常见应用是RepVGG模型。RepVGG在训练阶段使用多分支结构,而在推理阶段将其重新参数化为简单的VGG样式的卷积神经网络,从而兼具高性能和高效率。这种方法的优势在于,它能够在不牺牲模型性能的前提下,大幅度减少推理阶段的计算和存储需求,从而实现更快的推理速度和更低的资源占用。
OREPA关键点
- 在线优化阶段: 在这个阶段,OREPA通过移除原型块中的非线性组件,并引入线性缩放层来优化卷积层的性能。通过去除非线性组件,模型变得更易于优化。线性缩放层的引入可以提高模型的灵活性和优化效果。
- 压缩训练时模块阶段: 在这个阶段,OREPA将复杂的训练时模块压缩成一个单一的卷积操作,从而降低训练成本。通过简化结构将多个卷积层和批量归一化层合并为一个简单的卷积层,减少内存和计算成本。这种压缩结构的设计有助于提高训练效率。
- 线性缩放层: 线性缩放层是OREPA的关键组成部分,通过适当缩放权重来提高模型的灵活性和优化效果。这种线性缩放层取代了原有的非线性规范化层,保持了优化的多样性和表示能力。线性缩放层的引入有助于优化模型的训练过程,并提高模型的性能。
- 训练时模块压缩: 通过将复杂的训练时模块压缩成一个单一的卷积操作,OREPA降低了训练时的复杂性和资源消耗。这种压缩结构的设计使得在推理阶段,无论训练时的结构多么复杂,所有模型都被简化为单一的卷积层,提高了推理速度和降低了资源消耗。训练时模块压缩的过程有助于简化模型结构,提高训练和推理效率。
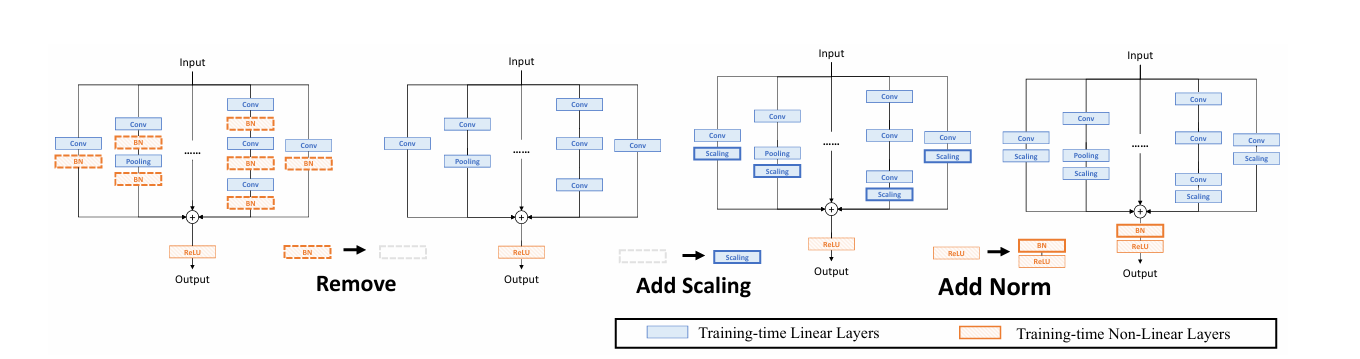
OREPA能够将复杂的训练时间块简化为单个卷积层,并保持较高的精度。OREPA的总体流程如图2所示,包括块线性化阶段和块压缩阶段。
-
块线性化
在训练过程中,中间的归一化层会阻碍单独层的合并,但直接删除它们会导致性能问题。为了解决这个困境,引入了一种通道级线性缩放操作,作为归一化的线性替代。缩放层包含一个可学习的向量,用于在通道维度上缩放特征图。线性缩放层与归一化层的作用相似,它们都鼓励多分支向不同方向优化,这是重参数化提高性能的关键。关于其具体影响的详细分析将在第3.4节中讨论。除了对性能的影响,线性缩放层还可以在训练过程中合并,使在线重参数化成为可能。
基于线性缩放层,对重参数化块进行修改,如图3所示。具体来说,块线性化阶段包括以下三个步骤:
- 去除所有非线性层:移除重参数化块中的所有非线性层,如归一化层。
- 添加尺度层:在每个分支的末尾添加一个尺度层,即线性缩放层,以保持优化多样性。
- 添加后归一化层:在合并所有分支之后,添加一个后归一化层,以稳定训练过程。
一旦完成线性化阶段,re-param块中只存在线性层,这意味着可以在训练阶段合并块中的所有组件。
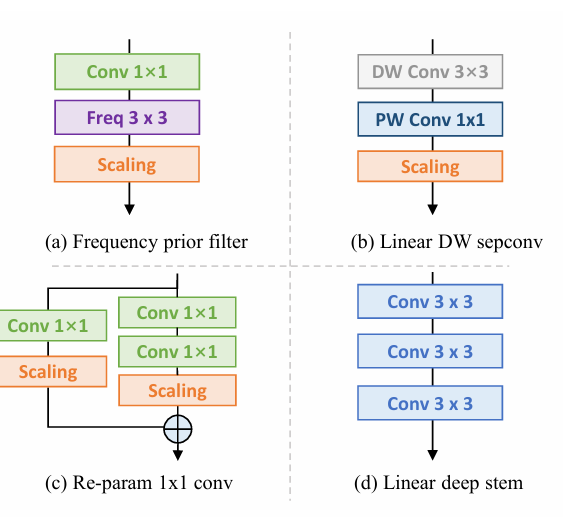
由于所提出的的OREPA大大节省了训练成本,它使能够探索更复杂的训练块。为此,通过对最先进的DBB模型进行线性化,并插入以下组件(图5),设计了一种新的重参数化模型OREPA-ResNet。
- 频率先验滤波器
在之前的工作中,块中使用了池化层。Qin 等人认为池化层是一种特殊的频率滤波器。为此,添加了一个 Conv1×1 频率滤波器分支。-
线性深度可分卷积
对深度可分卷积进行了稍微修改,去掉了中间的非线性激活层,使其在训练时可以合并。
-
1×1 卷积的重参数化
以前的工作主要集中在 3×3 卷积层的重参数化,而忽略了 1×1 层。建议对 1×1 层进行重参数化,因为它们在瓶颈结构中扮演着重要角色。具体来说,添加了一个额外的 Conv1×1 - Conv1×1 分支。
-
线性深 Stem
大型卷积核通常放置在最开始的层,如 7×7 stem 层,目的是获得更大的接收野。Guo 等人将 7×7 卷积层替换为堆叠的 3×3 层。
块压缩
得益于块的线性化,得到了一个线性块。块压缩步骤将中间特征映射上的操作转换为更高效的内核操作。这将重参数化的额外训练成本从 (O(H \times W)) 降低到 (O(K_H \times K_W)),其中 (H) 和 (W) 是特征图的空间尺寸,(K_H) 和 (K_W) 是卷积核的尺寸。
一般来说,无论线性重参数块多么复杂,以下两个属性始终有效:
- 块中的所有线性层,例如深度卷积、平均池化和线性缩放层,都可以用退化的卷积层表示,并具有相应的一组参数。
- 块可以由一系列并行分支表示,每个分支由一系列卷积层组成。
核心代码
from basic import *
import numpy as np
from dbb_transforms import transI_fusebn, transII_addbranch, transIII_1x1_kxk, transV_avg, transVI_multiscale
class OREPA(nn.Module):
def __init__(self,
in_channels,
out_channels,
kernel_size,
stride=1,
padding=0,
dilation=1,
groups=1,
internal_channels_1x1_3x3=None,
deploy=False,
nonlinear=None,
single_init=False,
weight_only=False,
init_hyper_para=1.0, init_hyper_gamma=1.0):
super(OREPA, self).__init__()
self.deploy = deploy
if nonlinear is None:
self.nonlinear = nn.Identity()
else:
self.nonlinear = nonlinear
self.weight_only = weight_only
self.kernel_size = kernel_size
self.in_channels = in_channels
self.out_channels = out_channels
self.groups = groups
assert padding == kernel_size // 2
self.stride = stride
self.padding = padding
self.dilation = dilation
if deploy:
self.orepa_reparam = nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size, stride=stride,
padding=padding, dilation=dilation, groups=groups, bias=True)
else:
self.branch_counter = 0
self.weight_orepa_origin = nn.Parameter(
torch.Tensor(out_channels, int(in_channels / self.groups),
kernel_size, kernel_size))
init.kaiming_uniform_(self.weight_orepa_origin, a=math.sqrt(0.0))
self.branch_counter += 1
self.weight_orepa_avg_conv = nn.Parameter(
torch.Tensor(out_channels, int(in_channels / self.groups), 1,
1))
self.weight_orepa_pfir_conv = nn.Parameter(
torch.Tensor(out_channels, int(in_channels / self.groups), 1,
1))
init.kaiming_uniform_(self.weight_orepa_avg_conv, a=0.0)
init.kaiming_uniform_(self.weight_orepa_pfir_conv, a=0.0)
self.register_buffer(
'weight_orepa_avg_avg',
torch.ones(kernel_size,
kernel_size).mul(1.0 / kernel_size / kernel_size))
self.branch_counter += 1
self.branch_counter += 1
self.weight_orepa_1x1 = nn.Parameter(
torch.Tensor(out_channels, int(in_channels / self.groups), 1,
1))
init.kaiming_uniform_(self.weight_orepa_1x1, a=0.0)
self.branch_counter += 1
if internal_channels_1x1_3x3 is None:
internal_channels_1x1_3x3 = in_channels if groups <= 4 else 2 * in_channels
if internal_channels_1x1_3x3 == in_channels:
self.weight_orepa_1x1_kxk_idconv1 = nn.Parameter(
torch.zeros(in_channels, int(in_channels / self.groups), 1, 1))
id_value = np.zeros(
(in_channels, int(in_channels / self.groups), 1, 1))
for i in range(in_channels):
id_value[i, i % int(in_channels / self.groups), 0, 0] = 1
id_tensor = torch.from_numpy(id_value).type_as(
self.weight_orepa_1x1_kxk_idconv1)
self.register_buffer('id_tensor', id_tensor)
else:
self.weight_orepa_1x1_kxk_idconv1 = nn.Parameter(
torch.zeros(internal_channels_1x1_3x3,
int(in_channels / self.groups), 1, 1))
id_value = np.zeros(
(internal_channels_1x1_3x3, int(in_channels / self.groups), 1, 1))
for i in range(internal_channels_1x1_3x3):
id_value[i, i % int(in_channels / self.groups), 0, 0] = 1
id_tensor = torch.from_numpy(id_value).type_as(
self.weight_orepa_1x1_kxk_idconv1)
self.register_buffer('id_tensor', id_tensor)
#init.kaiming_uniform_(
#self.weight_orepa_1x1_kxk_conv1, a=math.sqrt(0.0))
self.weight_orepa_1x1_kxk_conv2 = nn.Parameter(
torch.Tensor(out_channels,
int(internal_channels_1x1_3x3 / self.groups),
kernel_size, kernel_size))
init.kaiming_uniform_(self.weight_orepa_1x1_kxk_conv2, a=math.sqrt(0.0))
self.branch_counter += 1
expand_ratio = 8
self.weight_orepa_gconv_dw = nn.Parameter(
torch.Tensor(in_channels * expand_ratio, 1, kernel_size,
kernel_size))
self.weight_orepa_gconv_pw = nn.Parameter(
torch.Tensor(out_channels, int(in_channels * expand_ratio / self.groups), 1, 1))
init.kaiming_uniform_(self.weight_orepa_gconv_dw, a=math.sqrt(0.0))
init.kaiming_uniform_(self.weight_orepa_gconv_pw, a=math.sqrt(0.0))
self.branch_counter += 1
self.vector = nn.Parameter(torch.Tensor(self.branch_counter, self.out_channels))
if weight_only is False:
self.bn = nn.BatchNorm2d(self.out_channels)
self.fre_init()
init.constant_(self.vector[0, :], 0.25 * math.sqrt(init_hyper_gamma)) #origin
init.constant_(self.vector[1, :], 0.25 * math.sqrt(init_hyper_gamma)) #avg
init.constant_(self.vector[2, :], 0.0 * math.sqrt(init_hyper_gamma)) #prior
init.constant_(self.vector[3, :], 0.5 * math.sqrt(init_hyper_gamma)) #1x1_kxk
init.constant_(self.vector[4, :], 1.0 * math.sqrt(init_hyper_gamma)) #1x1
init.constant_(self.vector[5, :], 0.5 * math.sqrt(init_hyper_gamma)) #dws_conv
self.weight_orepa_1x1.data = self.weight_orepa_1x1.mul(init_hyper_para)
self.weight_orepa_origin.data = self.weight_orepa_origin.mul(init_hyper_para)
self.weight_orepa_1x1_kxk_conv2.data = self.weight_orepa_1x1_kxk_conv2.mul(init_hyper_para)
self.weight_orepa_avg_conv.data = self.weight_orepa_avg_conv.mul(init_hyper_para)
self.weight_orepa_pfir_conv.data = self.weight_orepa_pfir_conv.mul(init_hyper_para)
self.weight_orepa_gconv_dw.data = self.weight_orepa_gconv_dw.mul(math.sqrt(init_hyper_para))
self.weight_orepa_gconv_pw.data = self.weight_orepa_gconv_pw.mul(math.sqrt(init_hyper_para))
if single_init:
# Initialize the vector.weight of origin as 1 and others as 0. This is not the default setting.
self.single_init()
def fre_init(self):
prior_tensor = torch.Tensor(self.out_channels, self.kernel_size,
self.kernel_size)
half_fg = self.out_channels / 2
for i in range(self.out_channels):
for h in range(3):
for w in range(3):
if i < half_fg:
prior_tensor[i, h, w] = math.cos(math.pi * (h + 0.5) *
(i + 1) / 3)
else:
prior_tensor[i, h, w] = math.cos(math.pi * (w + 0.5) *
(i + 1 - half_fg) / 3)
self.register_buffer('weight_orepa_prior', prior_tensor)
def weight_gen(self):
weight_orepa_origin = torch.einsum('oihw,o->oihw',
self.weight_orepa_origin,
self.vector[0, :])
weight_orepa_avg = torch.einsum('oihw,hw->oihw', self.weight_orepa_avg_conv, self.weight_orepa_avg_avg)
weight_orepa_avg = torch.einsum(
'oihw,o->oihw',
torch.einsum('oi,hw->oihw', self.weight_orepa_avg_conv.squeeze(3).squeeze(2),
self.weight_orepa_avg_avg), self.vector[1, :])
weight_orepa_pfir = torch.einsum(
'oihw,o->oihw',
torch.einsum('oi,ohw->oihw', self.weight_orepa_pfir_conv.squeeze(3).squeeze(2),
self.weight_orepa_prior), self.vector[2, :])
weight_orepa_1x1_kxk_conv1 = None
if hasattr(self, 'weight_orepa_1x1_kxk_idconv1'):
weight_orepa_1x1_kxk_conv1 = (self.weight_orepa_1x1_kxk_idconv1 +
self.id_tensor).squeeze(3).squeeze(2)
elif hasattr(self, 'weight_orepa_1x1_kxk_conv1'):
weight_orepa_1x1_kxk_conv1 = self.weight_orepa_1x1_kxk_conv1.squeeze(3).squeeze(2)
else:
raise NotImplementedError
weight_orepa_1x1_kxk_conv2 = self.weight_orepa_1x1_kxk_conv2
if self.groups > 1:
g = self.groups
t, ig = weight_orepa_1x1_kxk_conv1.size()
o, tg, h, w = weight_orepa_1x1_kxk_conv2.size()
weight_orepa_1x1_kxk_conv1 = weight_orepa_1x1_kxk_conv1.view(
g, int(t / g), ig)
weight_orepa_1x1_kxk_conv2 = weight_orepa_1x1_kxk_conv2.view(
g, int(o / g), tg, h, w)
weight_orepa_1x1_kxk = torch.einsum('gti,gothw->goihw',
weight_orepa_1x1_kxk_conv1,
weight_orepa_1x1_kxk_conv2).reshape(
o, ig, h, w)
else:
weight_orepa_1x1_kxk = torch.einsum('ti,othw->oihw',
weight_orepa_1x1_kxk_conv1,
weight_orepa_1x1_kxk_conv2)
weight_orepa_1x1_kxk = torch.einsum('oihw,o->oihw', weight_orepa_1x1_kxk, self.vector[3, :])
weight_orepa_1x1 = 0
if hasattr(self, 'weight_orepa_1x1'):
weight_orepa_1x1 = transVI_multiscale(self.weight_orepa_1x1,
self.kernel_size)
weight_orepa_1x1 = torch.einsum('oihw,o->oihw', weight_orepa_1x1,
self.vector[4, :])
weight_orepa_gconv = self.dwsc2full(self.weight_orepa_gconv_dw,
self.weight_orepa_gconv_pw,
self.in_channels, self.groups)
weight_orepa_gconv = torch.einsum('oihw,o->oihw', weight_orepa_gconv,
self.vector[5, :])
weight = weight_orepa_origin + weight_orepa_avg + weight_orepa_1x1 + weight_orepa_1x1_kxk + weight_orepa_pfir + weight_orepa_gconv
return weight
def dwsc2full(self, weight_dw, weight_pw, groups, groups_conv=1):
t, ig, h, w = weight_dw.size()
o, _, _, _ = weight_pw.size()
tg = int(t / groups)
i = int(ig * groups)
ogc = int(o / groups_conv)
groups_gc = int(groups / groups_conv)
weight_dw = weight_dw.view(groups_conv, groups_gc, tg, ig, h, w)
weight_pw = weight_pw.squeeze().view(ogc, groups_conv, groups_gc, tg)
weight_dsc = torch.einsum('cgtihw,ocgt->cogihw', weight_dw, weight_pw)
return weight_dsc.reshape(o, int(i/groups_conv), h, w)
def forward(self, inputs=None):
if hasattr(self, 'orepa_reparam'):
return self.nonlinear(self.orepa_reparam(inputs))
weight = self.weight_gen()
if self.weight_only is True:
return weight
out = F.conv2d(
inputs,
weight,
bias=None,
stride=self.stride,
padding=self.padding,
dilation=self.dilation,
groups=self.groups)
return self.nonlinear(self.bn(out))
def get_equivalent_kernel_bias(self):
return transI_fusebn(self.weight_gen(), self.bn)
def switch_to_deploy(self):
if hasattr(self, 'or1x1_reparam'):
return
kernel, bias = self.get_equivalent_kernel_bias()
self.orepa_reparam = nn.Conv2d(in_channels=self.in_channels, out_channels=self.out_channels,
kernel_size=self.kernel_size, stride=self.stride,
padding=self.padding, dilation=self.dilation, groups=self.groups, bias=True)
self.orepa_reparam.weight.data = kernel
self.orepa_reparam.bias.data = bias
for para in self.parameters():
para.detach_()
self.__delattr__('weight_orepa_origin')
self.__delattr__('weight_orepa_1x1')
self.__delattr__('weight_orepa_1x1_kxk_conv2')
if hasattr(self, 'weight_orepa_1x1_kxk_idconv1'):
self.__delattr__('id_tensor')
self.__delattr__('weight_orepa_1x1_kxk_idconv1')
elif hasattr(self, 'weight_orepa_1x1_kxk_conv1'):
self.__delattr__('weight_orepa_1x1_kxk_conv1')
else:
raise NotImplementedError
self.__delattr__('weight_orepa_avg_avg')
self.__delattr__('weight_orepa_avg_conv')
self.__delattr__('weight_orepa_pfir_conv')
self.__delattr__('weight_orepa_prior')
self.__delattr__('weight_orepa_gconv_dw')
self.__delattr__('weight_orepa_gconv_pw')
self.__delattr__('bn')
self.__delattr__('vector')
def init_gamma(self, gamma_value):
init.constant_(self.vector, gamma_value)
def single_init(self):
self.init_gamma(0.0)
init.constant_(self.vector[0, :], 1.0)
YOLOv11引入代码
在根目录下的ultralytics/nn/目录,新建一个conv目录,然后新建一个以 OREPA为文件名的py文件, 把代码拷贝进去。
原代码无法直接使用,会报错IndexError: index 2 is out of bounds for dimension 2 with size 2,需要进行修改。
- 把引入的transI_fusebn, transII_addbranch,直接拷贝进来。
- 引入
autopad以及Conv- 源代码在运行会报错RuntimeError: Given groups=1, weight of size [32, 16, 1, 1], expected input[1, 128, 64, 64] to have 16 channels, but got 128 channels instead。这里直接加上out_channels = in_channels,保证通道数匹配。
import math
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
from torch.nn import init
def autopad(k, p=None, d=1): # kernel, padding, dilation
"""Pad to 'same' shape outputs."""
if d > 1:
k = d * (k - 1) + 1 if isinstance(k, int) else [d * (x - 1) + 1 for x in k] # actual kernel-size
if p is None:
p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-pad
return p
class Conv(nn.Module):
"""Standard convolution with args(ch_in, ch_out, kernel, stride, padding, groups, dilation, activation)."""
default_act = nn.SiLU() # default activation
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):
"""Initialize Conv layer with given arguments including activation."""
super().__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()
def forward(self, x):
"""Apply convolution, batch normalization and activation to input tensor."""
return self.act(self.bn(self.conv(x)))
def forward_fuse(self, x):
"""Perform transposed convolution of 2D data."""
return self.act(self.conv(x))
def transI_fusebn(kernel, bn):
gamma = bn.weight
std = (bn.running_var + bn.eps).sqrt()
return kernel * ((gamma / std).reshape(-1, 1, 1, 1)), bn.bias - bn.running_mean * gamma / std
def transVI_multiscale(kernel, target_kernel_size):
H_pixels_to_pad = (target_kernel_size - kernel.size(2)) // 2
W_pixels_to_pad = (target_kernel_size - kernel.size(3)) // 2
return F.pad(kernel, [W_pixels_to_pad, W_pixels_to_pad, H_pixels_to_pad, H_pixels_to_pad])
class OREPA(nn.Module):
def __init__(self,
in_channels,
out_channels,
kernel_size=3,
stride=1,
padding=None,
groups=1,
dilation=1,
act=True,
internal_channels_1x1_3x3=None,
deploy=False,
single_init=False,
weight_only=False,
init_hyper_para=1.0, init_hyper_gamma=1.0):
super(OREPA, self).__init__()
self.deploy = deploy
out_channels = in_channels
self.nonlinear = Conv.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()
self.weight_only = weight_only
self.kernel_size = kernel_size
self.in_channels = in_channels
self.out_channels = out_channels
self.groups = groups
self.stride = stride
padding = autopad(kernel_size, padding, dilation)
self.padding = padding
self.dilation = dilation
if deploy:
self.orepa_reparam = nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size,
stride=stride,
padding=padding, dilation=dilation, groups=groups, bias=True)
else:
self.branch_counter = 0
self.weight_orepa_origin = nn.Parameter(
torch.Tensor(out_channels, int(in_channels / self.groups), kernel_size, kernel_size))
init.kaiming_uniform_(self.weight_orepa_origin, a=math.sqrt(0.0))
self.branch_counter += 1
self.weight_orepa_avg_conv = nn.Parameter(
torch.Tensor(out_channels, int(in_channels / self.groups), 1,
1))
self.weight_orepa_pfir_conv = nn.Parameter(
torch.Tensor(out_channels, int(in_channels / self.groups), 1,
1))
init.kaiming_uniform_(self.weight_orepa_avg_conv, a=0.0)
init.kaiming_uniform_(self.weight_orepa_pfir_conv, a=0.0)
self.register_buffer(
'weight_orepa_avg_avg',
torch.ones(kernel_size,
kernel_size).mul(1.0 / kernel_size / kernel_size))
self.branch_counter += 1
self.branch_counter += 1
self.weight_orepa_1x1 = nn.Parameter(
torch.Tensor(out_channels, int(in_channels / self.groups), 1,
1))
init.kaiming_uniform_(self.weight_orepa_1x1, a=0.0)
self.branch_counter += 1
if internal_channels_1x1_3x3 is None:
internal_channels_1x1_3x3 = in_channels if groups <= 4 else 2 * in_channels
if internal_channels_1x1_3x3 == in_channels:
self.weight_orepa_1x1_kxk_idconv1 = nn.Parameter(
torch.zeros(in_channels, int(in_channels / self.groups), 1, 1))
id_value = np.zeros(
(in_channels, int(in_channels / self.groups), 1, 1))
for i in range(in_channels):
id_value[i, i % int(in_channels / self.groups), 0, 0] = 1
id_tensor = torch.from_numpy(id_value).type_as(
self.weight_orepa_1x1_kxk_idconv1)
self.register_buffer('id_tensor', id_tensor)
else:
self.weight_orepa_1x1_kxk_idconv1 = nn.Parameter(
torch.zeros(internal_channels_1x1_3x3,
int(in_channels / self.groups), 1, 1))
id_value = np.zeros(
(internal_channels_1x1_3x3, int(in_channels / self.groups), 1, 1))
for i in range(internal_channels_1x1_3x3):
id_value[i, i % int(in_channels / self.groups), 0, 0] = 1
id_tensor = torch.from_numpy(id_value).type_as(
self.weight_orepa_1x1_kxk_idconv1)
self.register_buffer('id_tensor', id_tensor)
# init.kaiming_uniform_(
# self.weight_orepa_1x1_kxk_conv1, a=math.sqrt(0.0))
self.weight_orepa_1x1_kxk_conv2 = nn.Parameter(
torch.Tensor(out_channels,
int(internal_channels_1x1_3x3 / self.groups),
kernel_size, kernel_size))
init.kaiming_uniform_(self.weight_orepa_1x1_kxk_conv2, a=math.sqrt(0.0))
self.branch_counter += 1
expand_ratio = 8
self.weight_orepa_gconv_dw = nn.Parameter(
torch.Tensor(in_channels * expand_ratio, 1, kernel_size,
kernel_size))
self.weight_orepa_gconv_pw = nn.Parameter(
torch.Tensor(out_channels, int(in_channels * expand_ratio / self.groups), 1, 1))
init.kaiming_uniform_(self.weight_orepa_gconv_dw, a=math.sqrt(0.0))
init.kaiming_uniform_(self.weight_orepa_gconv_pw, a=math.sqrt(0.0))
self.branch_counter += 1
self.vector = nn.Parameter(torch.Tensor(self.branch_counter, self.out_channels))
if weight_only is False:
self.bn = nn.BatchNorm2d(self.out_channels)
self.fre_init()
init.constant_(self.vector[0, :], 0.25 * math.sqrt(init_hyper_gamma)) # origin
init.constant_(self.vector[1, :], 0.25 * math.sqrt(init_hyper_gamma)) # avg
init.constant_(self.vector[2, :], 0.0 * math.sqrt(init_hyper_gamma)) # prior
init.constant_(self.vector[3, :], 0.5 * math.sqrt(init_hyper_gamma)) # 1x1_kxk
init.constant_(self.vector[4, :], 1.0 * math.sqrt(init_hyper_gamma)) # 1x1
init.constant_(self.vector[5, :], 0.5 * math.sqrt(init_hyper_gamma)) # dws_conv
self.weight_orepa_1x1.data = self.weight_orepa_1x1.mul(init_hyper_para)
self.weight_orepa_origin.data = self.weight_orepa_origin.mul(init_hyper_para)
self.weight_orepa_1x1_kxk_conv2.data = self.weight_orepa_1x1_kxk_conv2.mul(init_hyper_para)
self.weight_orepa_avg_conv.data = self.weight_orepa_avg_conv.mul(init_hyper_para)
self.weight_orepa_pfir_conv.data = self.weight_orepa_pfir_conv.mul(init_hyper_para)
self.weight_orepa_gconv_dw.data = self.weight_orepa_gconv_dw.mul(math.sqrt(init_hyper_para))
self.weight_orepa_gconv_pw.data = self.weight_orepa_gconv_pw.mul(math.sqrt(init_hyper_para))
if single_init:
# Initialize the vector.weight of origin as 1 and others as 0. This is not the default setting.
self.single_init()
def fre_init(self):
prior_tensor = torch.Tensor(self.out_channels, self.kernel_size,
self.kernel_size)
half_fg = self.out_channels / 2
for i in range(self.out_channels):
for h in range(3):
for w in range(3):
if i < half_fg:
prior_tensor[i, h, w] = math.cos(math.pi * (h + 0.5) *
(i + 1) / 3)
else:
prior_tensor[i, h, w] = math.cos(math.pi * (w + 0.5) *
(i + 1 - half_fg) / 3)
self.register_buffer('weight_orepa_prior', prior_tensor)
def weight_gen(self):
weight_orepa_origin = torch.einsum('oihw,o->oihw',
self.weight_orepa_origin,
self.vector[0, :])
weight_orepa_avg = torch.einsum('oihw,hw->oihw', self.weight_orepa_avg_conv, self.weight_orepa_avg_avg)
weight_orepa_avg = torch.einsum(
'oihw,o->oihw',
torch.einsum('oi,hw->oihw', self.weight_orepa_avg_conv.squeeze(3).squeeze(2),
self.weight_orepa_avg_avg), self.vector[1, :])
weight_orepa_pfir = torch.einsum(
'oihw,o->oihw',
torch.einsum('oi,ohw->oihw', self.weight_orepa_pfir_conv.squeeze(3).squeeze(2),
self.weight_orepa_prior), self.vector[2, :])
weight_orepa_1x1_kxk_conv1 = None
if hasattr(self, 'weight_orepa_1x1_kxk_idconv1'):
weight_orepa_1x1_kxk_conv1 = (self.weight_orepa_1x1_kxk_idconv1 +
self.id_tensor).squeeze(3).squeeze(2)
elif hasattr(self, 'weight_orepa_1x1_kxk_conv1'):
weight_orepa_1x1_kxk_conv1 = self.weight_orepa_1x1_kxk_conv1.squeeze(3).squeeze(2)
else:
raise NotImplementedError
weight_orepa_1x1_kxk_conv2 = self.weight_orepa_1x1_kxk_conv2
if self.groups > 1:
g = self.groups
t, ig = weight_orepa_1x1_kxk_conv1.size()
o, tg, h, w = weight_orepa_1x1_kxk_conv2.size()
weight_orepa_1x1_kxk_conv1 = weight_orepa_1x1_kxk_conv1.view(
g, int(t / g), ig)
weight_orepa_1x1_kxk_conv2 = weight_orepa_1x1_kxk_conv2.view(
g, int(o / g), tg, h, w)
weight_orepa_1x1_kxk = torch.einsum('gti,gothw->goihw',
weight_orepa_1x1_kxk_conv1,
weight_orepa_1x1_kxk_conv2).reshape(
o, ig, h, w)
else:
weight_orepa_1x1_kxk = torch.einsum('ti,othw->oihw',
weight_orepa_1x1_kxk_conv1,
weight_orepa_1x1_kxk_conv2)
weight_orepa_1x1_kxk = torch.einsum('oihw,o->oihw', weight_orepa_1x1_kxk, self.vector[3, :])
weight_orepa_1x1 = 0
if hasattr(self, 'weight_orepa_1x1'):
weight_orepa_1x1 = transVI_multiscale(self.weight_orepa_1x1,
self.kernel_size)
weight_orepa_1x1 = torch.einsum('oihw,o->oihw', weight_orepa_1x1,
self.vector[4, :])
weight_orepa_gconv = self.dwsc2full(self.weight_orepa_gconv_dw,
self.weight_orepa_gconv_pw,
self.in_channels, self.groups)
weight_orepa_gconv = torch.einsum('oihw,o->oihw', weight_orepa_gconv,
self.vector[5, :])
weight = weight_orepa_origin + weight_orepa_avg + weight_orepa_1x1 + weight_orepa_1x1_kxk + weight_orepa_pfir + weight_orepa_gconv
return weight
def dwsc2full(self, weight_dw, weight_pw, groups, groups_conv=1):
t, ig, h, w = weight_dw.size()
o, _, _, _ = weight_pw.size()
tg = int(t / groups)
i = int(ig * groups)
ogc = int(o / groups_conv)
groups_gc = int(groups / groups_conv)
weight_dw = weight_dw.view(groups_conv, groups_gc, tg, ig, h, w)
weight_pw = weight_pw.squeeze().view(ogc, groups_conv, groups_gc, tg)
weight_dsc = torch.einsum('cgtihw,ocgt->cogihw', weight_dw, weight_pw)
return weight_dsc.reshape(o, int(i / groups_conv), h, w)
def forward(self, inputs=None):
if hasattr(self, 'orepa_reparam'):
return self.nonlinear(self.orepa_reparam(inputs))
weight = self.weight_gen()
if self.weight_only is True:
return weight
out = F.conv2d(
inputs,
weight,
bias=None,
stride=self.stride,
padding=self.padding,
dilation=self.dilation,
groups=self.groups)
return self.nonlinear(self.bn(out))
def get_equivalent_kernel_bias(self):
return transI_fusebn(self.weight_gen(), self.bn)
def switch_to_deploy(self):
if hasattr(self, 'or1x1_reparam'):
return
kernel, bias = self.get_equivalent_kernel_bias()
self.orepa_reparam = nn.Conv2d(in_channels=self.in_channels, out_channels=self.out_channels,
kernel_size=self.kernel_size, stride=self.stride,
padding=self.padding, dilation=self.dilation, groups=self.groups, bias=True)
self.orepa_reparam.weight.data = kernel
self.orepa_reparam.bias.data = bias
for para in self.parameters():
para.detach_()
self.__delattr__('weight_orepa_origin')
self.__delattr__('weight_orepa_1x1')
self.__delattr__('weight_orepa_1x1_kxk_conv2')
if hasattr(self, 'weight_orepa_1x1_kxk_idconv1'):
self.__delattr__('id_tensor')
self.__delattr__('weight_orepa_1x1_kxk_idconv1')
elif hasattr(self, 'weight_orepa_1x1_kxk_conv1'):
self.__delattr__('weight_orepa_1x1_kxk_conv1')
else:
raise NotImplementedError
self.__delattr__('weight_orepa_avg_avg')
self.__delattr__('weight_orepa_avg_conv')
self.__delattr__('weight_orepa_pfir_conv')
self.__delattr__('weight_orepa_prior')
self.__delattr__('weight_orepa_gconv_dw')
self.__delattr__('weight_orepa_gconv_pw')
self.__delattr__('bn')
self.__delattr__('vector')
def init_gamma(self, gamma_value):
init.constant_(self.vector, gamma_value)
def single_init(self):
self.init_gamma(0.0)
init.constant_(self.vector[0, :], 1.0)
tasks注册
在ultralytics/nn/tasks.py中进行如下操作:
步骤1:
from ultralytics.nn.conv.OREPA import OREPA
步骤2
修改def parse_model(d, ch, verbose=True):
elif m in {OREPA}:
args = [ch[f], *args]
配置yolov11-OREPA.yaml
ultralytics/cfg/models/11/yolov11-OREPA.yaml
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLO11 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 8 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolo11n.yaml' will call yolo11.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.50, 0.25, 1024] # summary: 319 layers, 2624080 parameters, 2624064 gradients, 6.6 GFLOPs
s: [0.50, 0.50, 1024] # summary: 319 layers, 9458752 parameters, 9458736 gradients, 21.7 GFLOPs
m: [0.50, 1.00, 512] # summary: 409 layers, 20114688 parameters, 20114672 gradients, 68.5 GFLOPs
l: [1.00, 1.00, 512] # summary: 631 layers, 25372160 parameters, 25372144 gradients, 87.6 GFLOPs
x: [1.00, 1.50, 512] # summary: 631 layers, 56966176 parameters, 56966160 gradients, 196.0 GFLOPs
# YOLO11n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, OREPA, [128, 3, 2]] # 1-P2/4
- [-1, 2, C3k2, [256, False, 0.25]]
- [-1, 1, OREPA, [256, 3, 2]] # 3-P3/8
- [-1, 2, C3k2, [512, False, 0.25]]
- [-1, 1, OREPA, [512, 3, 2]] # 5-P4/16
- [-1, 2, C3k2, [512, True]]
- [-1, 1, OREPA, [1024, 3, 2]] # 7-P5/32
- [-1, 2, C3k2, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
- [-1, 2, C2PSA, [1024]] # 10
# YOLO11n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 2, C3k2, [512, False]] # 13
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 2, C3k2, [256, False]] # 16 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 13], 1, Concat, [1]] # cat head P4
- [-1, 2, C3k2, [512, False]] # 19 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 10], 1, Concat, [1]] # cat head P5
- [-1, 2, C3k2, [1024, True]] # 22 (P5/32-large)
- [[16, 19, 22], 1, Detect, [nc]] # Detect(P3, P4, P5)
实验
脚本
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLO
if __name__ == '__main__':
# 修改为自己的配置文件地址
model = YOLO('/root/ultralytics-main/ultralytics/cfg/models/11/yolov11-OREPA.yaml')
# 修改为自己的数据集地址
model.train(data='/root/ultralytics-main/ultralytics/cfg/datasets/coco8.yaml',
cache=False,
imgsz=640,
epochs=10,
single_cls=False, # 是否是单类别检测
batch=8,
close_mosaic=10,
workers=0,
optimizer='SGD',
amp=True,
project='runs/train',
name='OREPA',
)
结果
 @[TOC]
@[TOC]




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











