




 本文深入探讨了Apache Spark Streaming的核心概念,包括其微批处理架构、实时数据流处理流程以及关键的转换操作。文章详细介绍了状态less和stateful转换的区别,并阐述了如何利用Spark Streaming进行大规模数据流分析。
本文深入探讨了Apache Spark Streaming的核心概念,包括其微批处理架构、实时数据流处理流程以及关键的转换操作。文章详细介绍了状态less和stateful转换的区别,并阐述了如何利用Spark Streaming进行大规模数据流分析。
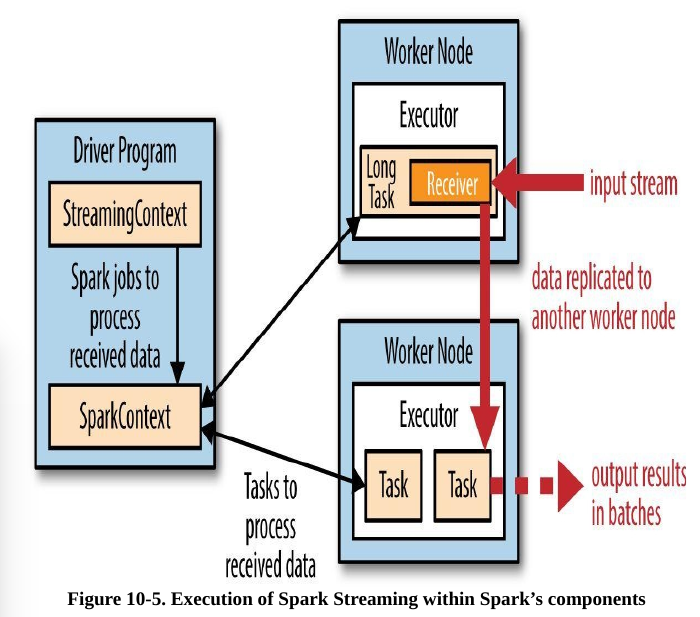
Spark Streaming uses a “micro-batch” architecture, where the streaming computation is treated as a continuous series of batch computations on small batches of data. Spark Streaming receives data from various input sources and groups it into small batches. New batches are created at regular time intervals.At the beginning of each time interval a new batch is created,and any data that arrives during that interval gets added to that batch.At the end of the time interval the batch is done growing.The size of the time intervals is determined by a parameter called the batch interval.

Transformations
Transformations on DStreams can be grouped into either stateless or stateful:
- In stateless transformations the processing of each batch does not depend on the data of its previousbatches.
- Stateful transformations,in contrast,use data or intermediate results from previous batches to compute the results of the current batch.They include transformations based on sliding windows and on tracking state across time.
Preferences
<<learning spark>>


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









