




在 AI 应用开发热潮下,一套稳定、可扩展的 AI 助手模块能大幅提升开发效率。本文将结合实际落地案例,从技术栈选型到核心功能操作,全方位拆解基于 Vue3+Django+Ollama 的 AI 助手模块,帮助开发者快速理解架构设计与实操逻辑。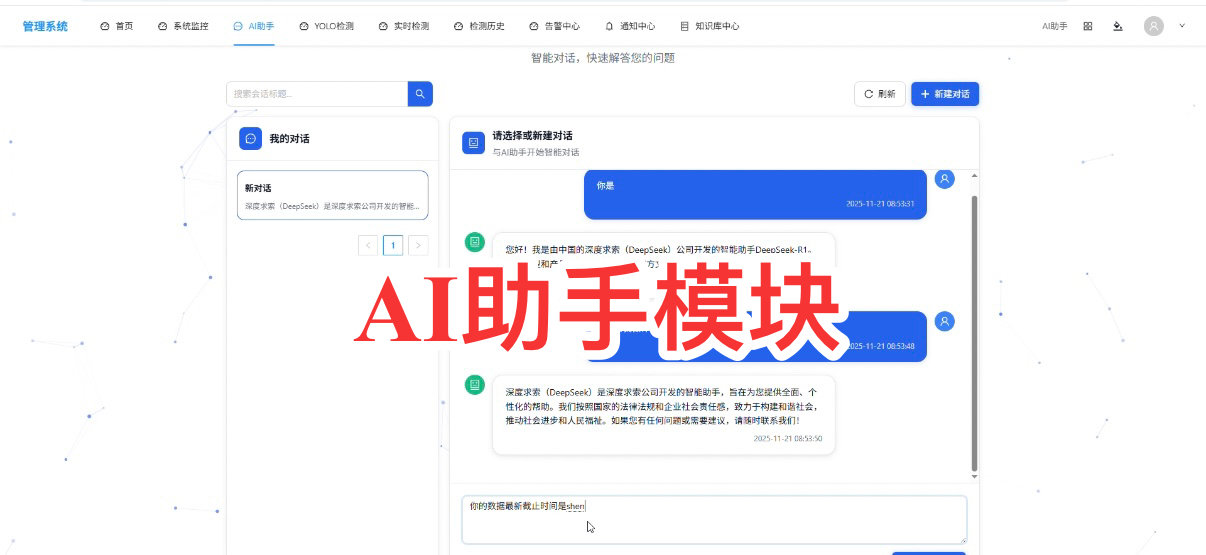
一、技术栈选型与架构设计
1. 前端技术栈:轻量高效,兼顾体验与扩展性
- 核心框架:Vue 3 + TypeScript,强类型支持减少开发 Bug,Composition API 提升代码复用性,适配复杂组件逻辑;
- UI 与样式:Ant Design Vue 提供丰富开箱组件,搭配 Tailwind CSS + DaisyUI 实现快速样式定制,兼顾美观与开发效率;
- 工程化工具:Vite 作为构建工具,热更新速度比 Webpack 提升 50% 以上,大幅缩短开发周期;
- 状态与路由:Pinia 替代 Vuex 管理全局状态,支持模块化拆分;Vue Router 实现会话间无缝切换,路由守卫保障权限安全;
- 请求处理:Axios 封装请求拦截器,统一处理 Token 过期、接口错误等场景,配合 loading 状态提升用户体验。
2. 后端与 AI 层:稳定可靠,支持本地部署
- 后端框架:Django 5.2.6 + DRF 3.14.0,DRF 提供强大的序列化与视图集功能,快速构建 RESTful API,适配前端多场景数据需求;
- 数据存储:SQLite 作为主数据库,轻量化且无需额外部署,适合中小规模数据存储;Redis 缓存高频访问数据(如会话信息、AI 响应结果),将接口响应时间从秒级压缩至毫秒级;
- 权限认证:JWT 生成无状态 Token,配合 RBAC(基于角色的权限控制)模型,精细化管理用户操作权限(如对话删除、会话创建),避免越权操作;
- 大模型部署:采用 Ollama 本地部署,支持 Llama 3、Mistral 等主流模型,无需依赖第三方 API,降低数据隐私风险与调用成本,同时支持模型版本快速切换。
3. 整体架构:模块化 + 前后端分离
采用插拔式模块化设计,前端按 “会话管理”“AI 交互”“搜索筛选” 拆分组件,后端按 “用户认证”“会话接口”“AI 调用” 拆分服务,后续可单独扩展功能模块(如文件上传、多轮对话记忆);前后端通过 RESTful API 通信,解耦开发流程,支持前端单独部署(如静态资源托管)、后端横向扩展(如多实例部署)。
二、核心功能操作演示(附技术对应逻辑)
1. 新建对话与 AI 交互:从请求到响应的全流程
- 操作步骤:点击 “新建对话” 按钮,输入提问(如 “你是”“你能为我做什么”“数据最新截止时间”),等待 AI 回复;
- 背后技术:
- 前端点击事件触发 Pinia 状态更新,记录当前会话 ID;
- Axios 携带 JWT Token 发送 POST 请求至 Django 后端 “/api/ai/chat/” 接口;
- 后端 DRF 视图集验证 Token 与用户权限,调用 Ollama SDK 发送 prompt;
- Ollama 返回结果后,后端将对话记录存入 SQLite,同时更新 Redis 缓存(缓存当前会话最新 3 条记录);
- 前端接收响应后,通过 Vue 3 的响应式数据更新界面,展示 AI 回复。
- 效果:输入 “你是” 时,AI 秒级返回身份定位;追问 “能做什么” 时,清晰罗列功能清单;查询 “数据截止时间” 时,准确返回预设时间节点,无明显延迟。
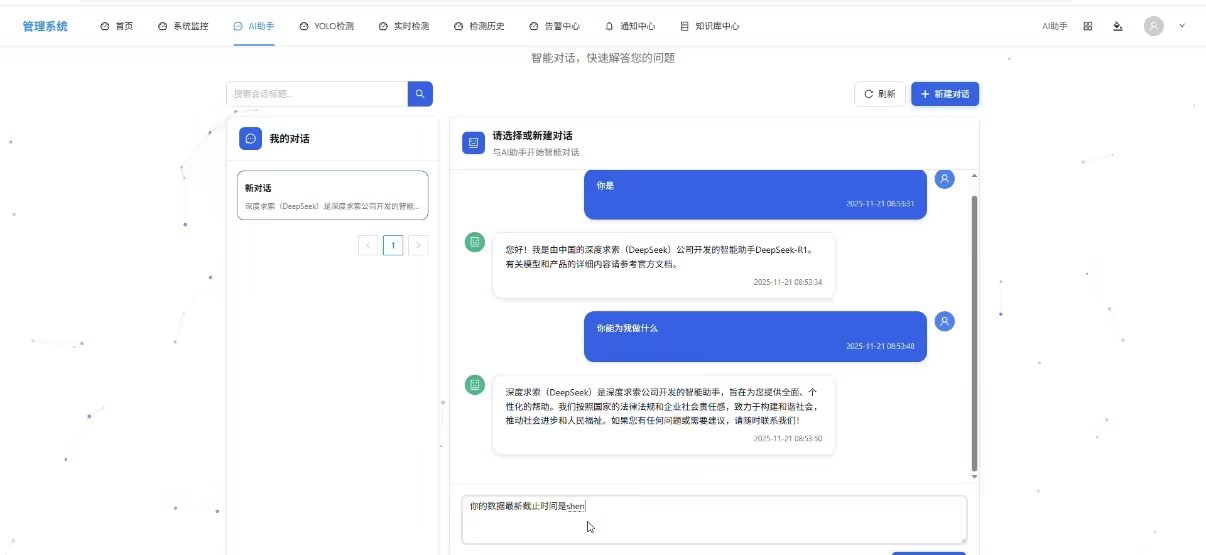
2. 多会话并行与重命名:路由与状态管理的协同
- 操作步骤:重复 “新建对话” 操作创建多个会话,点击会话标题编辑框,将会话分别重命名
- 背后技术:
- 每个会话创建时,Vue Router 生成独立路由(如 “/chat/[sessionId]”),通过路由参数区分不同会话;
- Pinia 的 “sessionStore” 模块存储所有会话列表,重命名时触发 state 更新,同步更新导航栏会话名称;
- 后端通过会话 ID 关联用户 ID,将不同会话的对话记录隔离存储,避免数据混淆。
- 优势:支持同时处理多个话题(如一边咨询技术问题,一边生成文案),会话切换时无数据丢失,符合用户多任务操作习惯。
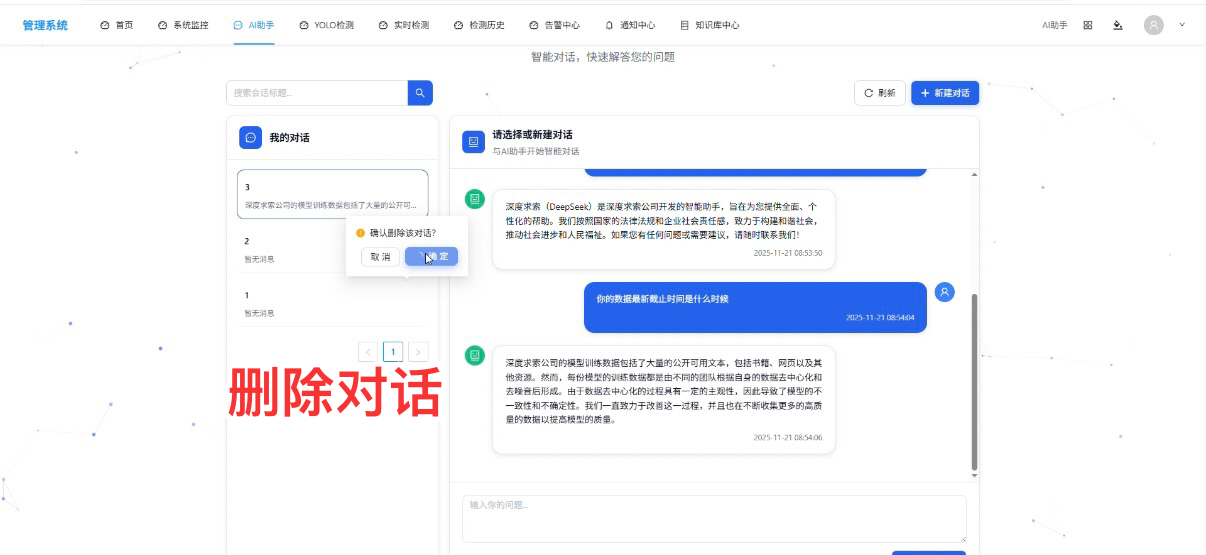
3. 会话搜索与删除:筛选效率与数据安全的平衡
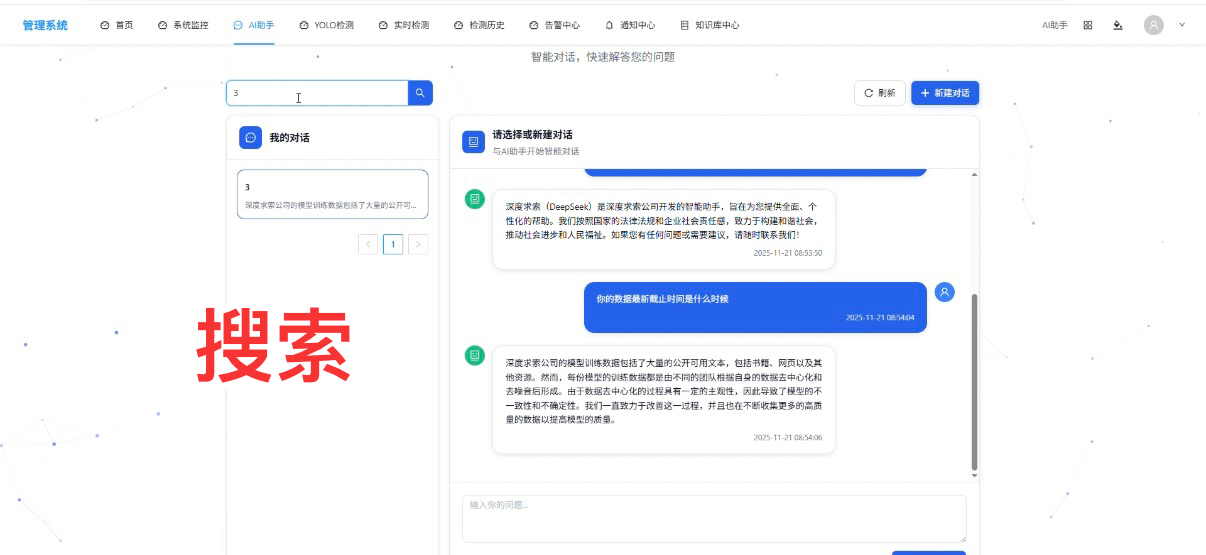
- 操作步骤 1(搜索):在顶部搜索框输入 “3”,系统快速筛选出名称含 “3” 的会话(即 “123” 会话);
- 背后技术 1:前端通过 Pinia 的 getter 过滤会话列表,使用 “includes” 方法匹配会话名称,配合防抖处理(500ms 延迟),避免频繁触发筛选逻辑;若后续会话量增大,可扩展为后端 Elasticsearch 搜索,提升筛选效率。
- 操作步骤 2(删除):点击会话 “删除” 按钮,确认后删除当前会话及所有对话记录;
- 背后技术 2:
- 前端发送 DELETE 请求至 “/api/session/[sessionId]/”,携带 JWT Token;
- 后端验证用户是否为会话创建者(RBAC 权限校验),通过后删除 SQLite 中的会话与对话记录,同时清除 Redis 中对应缓存;
- 前端接收成功响应后,通过 Vue Router 跳转到默认会话,更新 Pinia 中的会话列表。
三、技术亮点与扩展建议
1. 核心亮点总结
- 性能优化:Redis 缓存减少数据库查询次数,Vite 构建提升前端加载速度,Ollama 本地部署降低网络延迟;
- 安全性:JWT 防伪造请求,RBAC 控制操作权限,SQLite 数据本地存储降低隐私泄露风险;
- 可扩展性:模块化设计支持新增功能(如语音输入、文件导出),Ollama 支持切换不同大模型,适配不同场景需求。
2. 后续扩展方向
- 前端:集成 VueUse 工具库优化组件逻辑,添加暗黑模式适配不同使用场景;
- 后端:引入 Celery 实现异步任务(如长文本 AI 生成、批量对话导出),避免接口阻塞;
- AI 层:对接 LangChain 实现多模型协作(如用 GPT-4 处理复杂逻辑,用 Llama 3 处理简单问答),降低成本;
- 部署:前端用 Nginx 托管静态资源,后端用 Docker 容器化部署,支持一键启动(Docker Compose 管理前端、后端、Redis、Ollama 服务)。
四、结语
本文通过 “技术栈解析 + 操作演示 + 原理拆解”,完整呈现了 AI 助手模块的开发与使用流程,从前端的 Vue3 组件到后端的 Django 接口,再到 Ollama 大模型部署,每一步都兼顾实用性与技术深度。对于开发者而言,这套方案不仅可直接用于小场景落地(如个人 AI 助手、团队内部工具),也可作为学习前后端分离 + AI 应用开发的实战案例。
若在实践中遇到技术问题(如 Ollama 部署报错、Vue Router 路由冲突),欢迎在评论区交流,后续将针对高频问题推出专项解决方案!
赫兹威客官方交流群
赫兹威客官方交流群
赫兹威客官方交流群
https://qm.qq.com/q/ToiE4c056U![]() https://qm.qq.com/q/ToiE4c056U
https://qm.qq.com/q/ToiE4c056U


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









