



 该研究提出了一种监督层次深度哈希(SHDH)方法,利用等级标签信息改进检索性能。通过定义加权相似度度量和深度卷积神经网络学习高效的哈希编码。实验验证了SHDH的有效性,特别是在考虑标签层次关系时的检索准确性。
该研究提出了一种监督层次深度哈希(SHDH)方法,利用等级标签信息改进检索性能。通过定义加权相似度度量和深度卷积神经网络学习高效的哈希编码。实验验证了SHDH的有效性,特别是在考虑标签层次关系时的检索准确性。
这篇工作来自于AAAI2018,主要关注于图像标签的等级关系,通过引入带权的哈希距离,提高了整个检索的性能。
摘要
之前的工作都没有考虑到标签直接的等级关系(hierarchical relation of label)而等级关系里面具有丰富的信息。针对上述问题,提出了supervised hierarchical deep hashing (SHDH),具体来说定义了带权的相似度度量方式,通过深度卷积神经网络来获取高效的哈希编码,并通过相关实验来验证了SHDH的高效性。
本文的主要工作
层级相似度(Hierarchical Similarity)
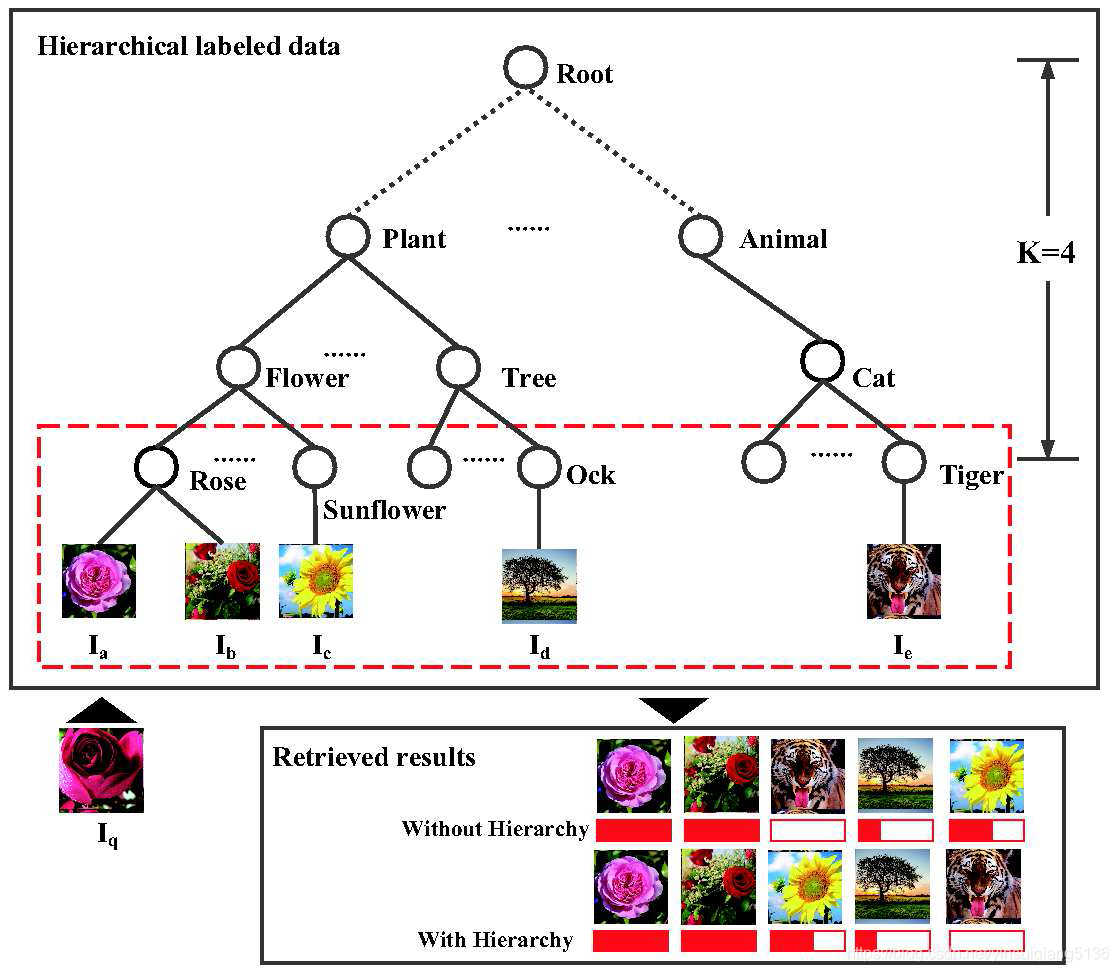
在一个等级的不同层的图像具有区分力的相似度,基于此,本文定义了基于等级标签数据两个图像的等级相似度。

公式(1)表明如果图像i和图像j在第k层中具有相同的祖先节点,那么图像i和图像j在这一层是相似的。反之,则不相似。
直观上来看,越高的层级越重要,因为如果选择了错误的祖先节点那么就到达不了正确的后继节点。
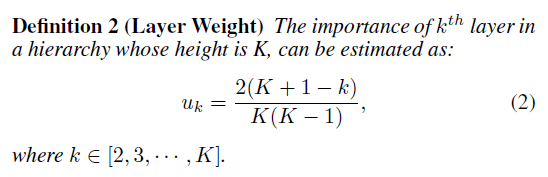
其中,当![]() 表明root节点没有区分能力,显然
表明root节点没有区分能力,显然![]() 表明祖先节点的影响力大于后继节点,此处作者增大权重层。基于上述两个定义,最终的图像i和图像j的等级相似度可以通过以下计算:
表明祖先节点的影响力大于后继节点,此处作者增大权重层。基于上述两个定义,最终的图像i和图像j的等级相似度可以通过以下计算:
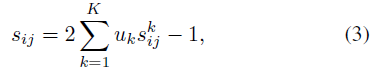
其中,K为等级高度。公式(3)可以保证图像对之间具有越common的等级标签对,则图像之间越相似。
objective function
对于图像xi,对应的哈希编码h(i)是由多个![]() 组成,因此,图像i和图像j带权哈希距离
组成,因此,图像i和图像j带权哈希距离![]()
首先,基于此定义相似度保持函数如下所示:
![]()
公式(5)可以保证相似的图像在每个segment中具有相同的hash code。
其次,最大化每位hash bit的信息,因此最大化下面的entropy,如公式(6)所示。
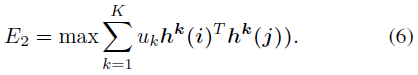
联合公式(5)和公式(6)所示,得到如下的损失函数:
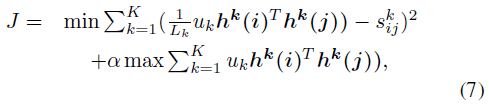
其中,![]() 为超参数。
为超参数。
Learning
假设N个数据所有的哈希编码![]() ,可以把公式(7)转换为如下的矩阵形式,如(8)所示方便优化。
,可以把公式(7)转换为如下的矩阵形式,如(8)所示方便优化。
![]()
其中A为对角阵,其中![]() 的值即为对应的
的值即为对应的![]() ,则根据如下进行优化。
,则根据如下进行优化。
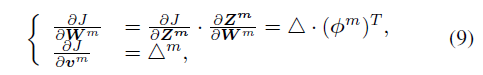


















 537
537

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









