




 本文详细介绍了SparkSQL的发展历程,从Hive到Shark再到SparkSQL的演变过程,以及SparkSQL相较于传统Hive的性能优势。同时,文章还深入探讨了SparkSQL中的DataFrame基本使用方法,并提供了实际操作示例,包括DataFrame的创建、查询、筛选和聚合等关键操作。
本文详细介绍了SparkSQL的发展历程,从Hive到Shark再到SparkSQL的演变过程,以及SparkSQL相较于传统Hive的性能优势。同时,文章还深入探讨了SparkSQL中的DataFrame基本使用方法,并提供了实际操作示例,包括DataFrame的创建、查询、筛选和聚合等关键操作。
目录:
- Spark SQL发展历程
- Spark SQL性能
- DateFrame介绍
- Spark RDD SQL 简单使用
一.Spark SQL发展历程
1.hive 到shark 再到spark sql 的演变

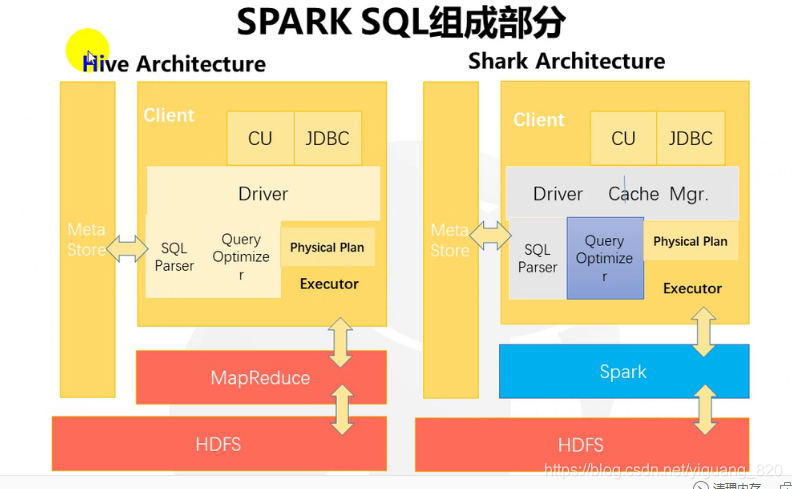



2.hive on spark(hive集成spark,计算效率提高,而不是仅仅依赖mapreduce)

![]()
3.spark sql实现


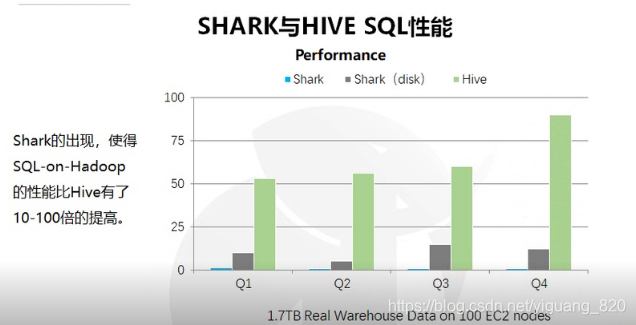
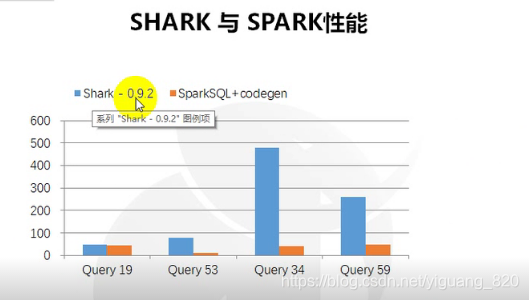
二.Spark SQL性能
shark 、shark (disk)、 spark sql 三者性能比较
三.DateFrame介绍


![]()
四.Spark RDD SQL简单使用
1.使用DataFrame
- 引入spark-sql_2.10依赖
- 构造SqlContext
//1.创建一个SparkConf对象 val conf=new SparkConf().setAppName("HelloSpark").setMaster("local[2]") //2.创建一个SparkConf对象 val sc=new SparkContext(conf) //3.创建一个SQLContext对象 val sqlContext=new SQLContext(sc) - 导入支持RDD到DataFrame的隐式转换
import sqlContext.implicits._ - 构造DataFrame
val df:DataFrame=sqlContext.read.json("e://user.json")
2.DataFrame简单操作
- 显示df:DataFrame的内容:df.show()
- 显示df:DataFrame中scheme的内容:df.printSchema()
- 显示某一列信息:df.select("user").show()
- 对列的值进行操作:df.select(df("user").show(),df("age")*10).show()
- 对值进行条件过滤:df.filter(df("age")>3).show()
- 分组之后进行过数据统计:df.gorupBy("name").count().show()
3.示例:使用步骤
- 创建项目
- 引入Spark 版本对应的Spark SQL 依赖(注意是在在Spark Core的基础之上)
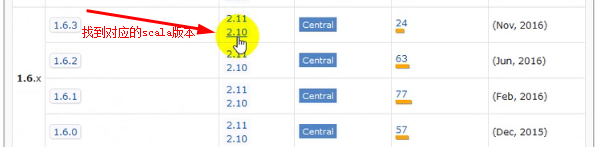
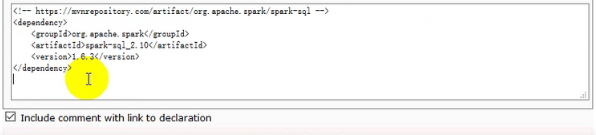
- 在e盘创建一个user.json文件
{"user":"aaa1","age":11} {"user":"aaa2","age":12} {"user":"aaa3","age":13} {"user":"aaa4","age":14} {"user":"aaa5","age":15} {"user":"aaa6","age":16} {"user":"aaa7","age":17} {"user":"aaa8","age":18} {"user":"aaa9","age":19} - 编写代码
package test import org.apache.spark.SparkConf import org.apache.spark.SparkContext import org.apache.spark.SparkContext._ import org.apache.spark.rdd.RDD import org.apache.spark.sql.SQLContext import org.apache.spark.sql.DataFrame object SparkFirst { def main(args: Array[String]): Unit = { //1.创建一个SparkConf对象 val conf=new SparkConf().setAppName("HelloSpark").setMaster("local[2]") //2.创建一个SparkConf对象 val sc=new SparkContext(conf) //3.创建一个SQLContext对象 val sqlContext=new SQLContext(sc) //4.引入包,import的效果从开始延伸到语句块的结束 import sqlContext.implicits._ /*如果手里有一个RDD,需要通过spark sql的方式进行操作的话,那么就需要用到spark sql的函数。 但是这些函数,默认情况下RDD是没有的。所以在scala中有一个很特殊的功能——隐式转换 将本地文件内容转换成一个DataFrame*/ //5.创建一个DataFrame val df:DataFrame=sqlContext.read.json("e://user.json") //6.使用spark sql函数 df.show() } } - 运行结果
+---+----+ |age|user| +---+----+ | 11|aaa1| | 12|aaa2| | 13|aaa3| | 14|aaa4| | 15|aaa5| | 16|aaa6| | 17|aaa7| | 18|aaa8| | 19|aaa9| +---+----+


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









