




 本文深入介绍了Apache Spark大数据处理框架,涵盖了Spark的特点、环境搭建、简单使用、运行模式及基础架构等内容。Spark以其轻量、快速、灵活和巧妙的特点,在数据处理、迭代计算、数据挖掘等领域展现出卓越性能。
本文深入介绍了Apache Spark大数据处理框架,涵盖了Spark的特点、环境搭建、简单使用、运行模式及基础架构等内容。Spark以其轻量、快速、灵活和巧妙的特点,在数据处理、迭代计算、数据挖掘等领域展现出卓越性能。
目录:
- Spark简介
- Spark特点
- Spark环境搭建
- Spark简单使用
- idea创建sprak项目
- Spark运行模式
- Spark基础架构
一.Spark简介
2.Spark是什么
- Spark系统是分布式批处理系统和分析挖掘引擎
- Spark是AMP LAB贡献到Apache社区的开源项目,是AMP大数据栈的基础组件
3.Spark能做什么
- 数据处理(Data Processing):可以用来快速处理数据,兼具容错性和可扩展性
- 迭代计算(Iterative Computation):支持迭代计算,有效应对多步的数据处理逻辑
- 数据挖掘(Data Mining):在海量数据基础上进行复杂的挖掘分析,可支持各种数据挖掘和机器学习算法
4.计算分为两大类:离线(批处理)和实时(流式处理、在线)
Spark数据处理(从一堆数据中找到或者统计出想要的结果):
- 容错性:
mr的错误点:在计算的过程中,某一台的计算服务挂掉(网线掉了、死机、内存不存、timeout超时等等),对于mr来说,整个程序是不是挂了?
并不会,会将该台服务器上处理的块数据迁移到另一个块的主机上,继续进行计算,(会影响job整体时间),但是对于job的结果还是会正常计算。
spark的容错性,基本上和mr一致(一台主机挂掉,将计算迁移到另一台接着计算) - 可扩展性:
mr增加 nodemanager 节点(salaves文件中增加),就等于增加了计算单元
spark与mr一样,就是可以动态的加节点(服务器) - 迭代计算:
Data => A(会产生一个结果)=> B(基于A的结果接着计算)=> C 如果中间某一步出现了问题,将会“影响结果”或者从头再来 - 数据挖掘:机器学习和图计算(是大数据挖掘工程师需要掌握的)
5.Spark生态圈
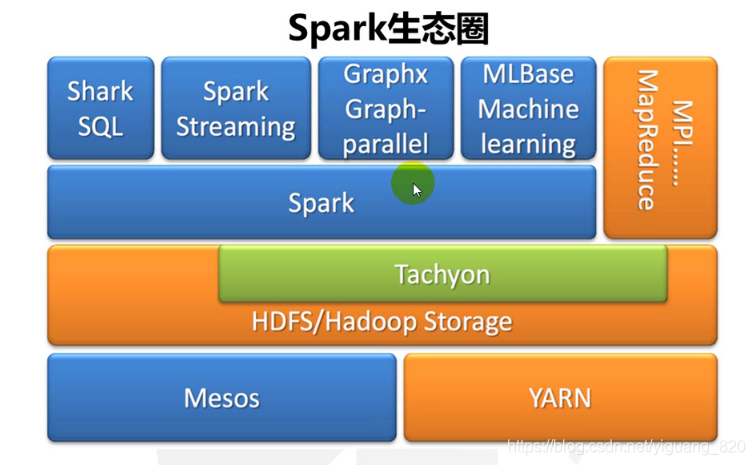
核心组件如下:
- Spark(Spark Core):包含Spark的基本功能;尤其是定义RDD的API、操作以及这两者上的动作。其他Spark的库都是构建在RDD和Spark Core之上的。
- Spark SQL:提供通过Apache Hive的SQL变体Hive查询语言(HiveQL)与Spark进行交互的API。每个数据库表被当做一个RDD,Spark SQL查询被转换为Spark操作。对熟悉Hive和HiveQL的人,Spark可以拿来就用。
- Spark Streaming:允许对实时数据流进行处理和控制。很多实时数据库(如Apache Store)可以处理实时数据。Spark Streaming允许程序能够像普通RDD一样处理实时数据。
- GraphX:图计算。控制图、并行图操作和计算的一组算法和工具的集合。GraphX扩展了RDD API,包含控制图、创建子图、访问路径上所有顶点的操作。
- MLlib:机器学习。一个常用机器学习算法库,算法被实现为对RDD的Spark操作。这个库包含可扩展的学习算法,比如分类、回归等需要对大量数据集进行迭代的操作。之前可选的大数据机器学习库Mahout,将会转到Spark,并在未来实现。
为什么很多国内的公司采用 yarn 而不是mesos?
- Spark解决的问题的什么:计算
在大数据里面hdfs已经被工公认为文件存储比较稳定的文件系统,所以大部分公司采用了hadoop的hdfs来存储相应的文件。
hadoop里面从Hadoop2.x里同将yarn引入到了dadoop架构里,所以公司里面就已经自带yarn了,
而且yarn也是一个比较优秀的资源调度管理架构。
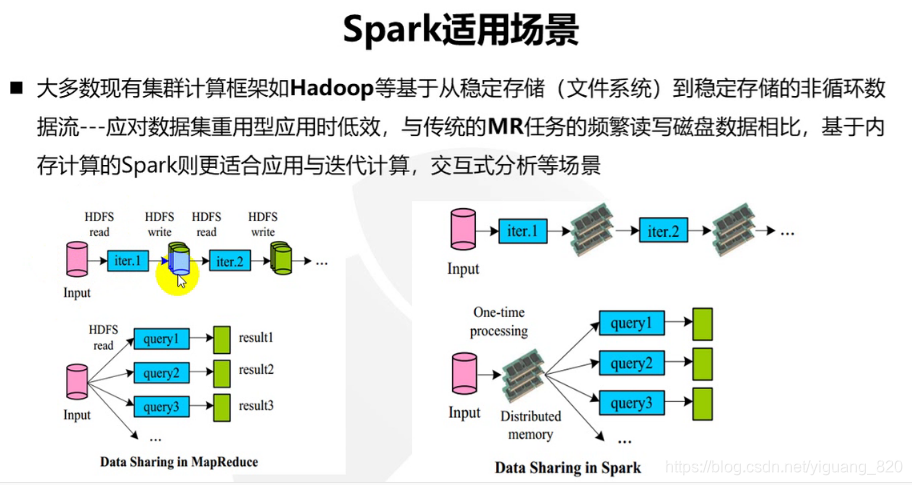
6.Spark使用场景

二.Spark特点
1.特点
- 轻
- Spark Core核心代码有3万行
- Scala语言的简洁和丰富表达力
- 巧妙利用了Hadoop和Mesos的基础设施
- 快:Spark对小数据集可达到亚秒级的延迟
- 对大数据集的迭代、机器学习、即席查询、图计算等应用,Spark版本比基于MapReduce、Hive和Pregel的实现快
- 内存计算、数据本地性和传输优化、调度优化
- 灵:Spark提供了不同层面的灵活性
- Scala语言trait动态混入策略(如可更换的集群调度器、序列化库)
- 允许扩展新的数据算子、新的数据源、新的language bingings
- Spark支持内存计算、多迭代批量处理、即席查询、流处理和图计算等多种范式
- 巧:巧妙借助现有大数据组件
- Saprk借Hadoop之势,与Hadoop无缝结合
- 图计算借用Pregel和PowerGraph的API以及PowerGraph的点分割思想
2.4个问题
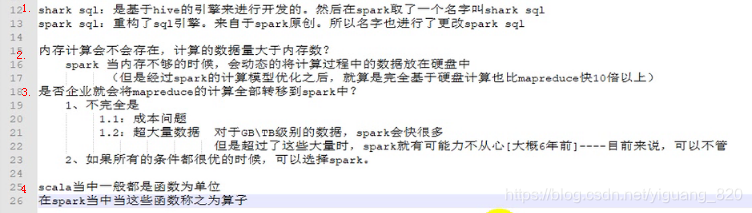
3.Spark和Hadoop比较

三.Spark环境搭建
安装步骤:
- 安装的spark版本为 spark-1.6.0,根据文档搭建spark运行环境
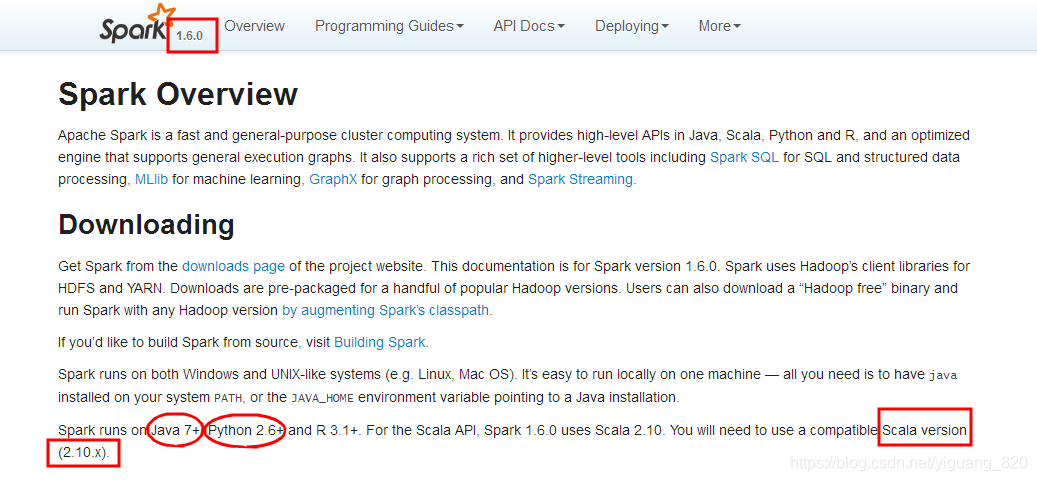
- 搭建Spark开发环境:提前安装Java 7+、Hadoop 2.6.0+ 、Python 2.6+ 、Scala 2.10.x,版本如
- 安装Java:Linux下安装Java(JDK8)
- 安装Hadoop:hadoop-2.7.3的安装
- 安装Python:http://www.runoob.com/python/python-install.html
- 安装Scala:linux下安装scala
- 下载Spark-1.6.0:官网下载链接
- 上传
- 解压
- 配置环境变量
- 修改配置文件
第一步:在conf目录下复制并重命名 spark-env.sh.template 为spark-env.sh
执行:
cp spark-env.sh.template spark-env.sh
vim spark-env.sh
第二步:在spark-env.sh中添加export JAVA_HOME=/home/jdk1.7.0_80 SPARK_MASTER_IP=localhost SPARK_WORKER_MEMOR=1G - 启动和测试
- 启动:因为提前了安装了hadoop,而hadoop的启动命令也是start-all.sh,所以进入spark的安装目录下/sbin/start-all.sh下执行
$SPARK_HOME/sbin/start-all.sh - 测试Spark是否安装成功:
$SPARK_HOME/bin/run-example SparkPi - 得到结果:
Pi is roughly 3.14716 - 检查页面:是否安装成功
http://localhost:8080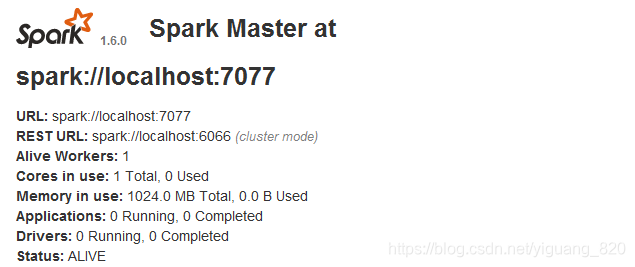
- 验证是否可以web访问:
crul http://localhost:8080/
- 启动:因为提前了安装了hadoop,而hadoop的启动命令也是start-all.sh,所以进入spark的安装目录下/sbin/start-all.sh下执行
四.Spark简单使用
spark安装之后可以输入 spark shell 进入spark的shell窗口,spark shell内置了一个SparkContext对象 =>spark上下文
然后开始学习spark的算子
如:
1.获取文件内容:
sc.textFile("/keduox/a.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_)
解析:使用sc.textFile("文件路径")读取一个文件中的内容,接收的对象为org.apache.spark.rdd.RDD,将文件内容转为RDD
2.将结果转为数组
sc.textFile("/keduox/a.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect
3.对象进行排序:根据key从大到小排列(为false则从大到小排列,为true或者为空则从小到达排列)
sc.textFile("/keduox/a.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).sortBy(_._2,false).collect
sc.textFile("/keduox/a.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).sortBy(_._2,true).collect
sc.textFile("/keduox/a.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).sortBy(_._2).collect
4.将结果存储到本地文件
sc.textFile("/keduox/a.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).saveAsTextFile("keduox/out/")
5.将排序后的对象中的元素顺序颠倒存储到本地文件
sc.textFile("/test/aaa.txt").flatMap(_.split(",")).map((_,1)).reduceByKey(_+_).sortBy(_._2,true)
.map(x => (x._2,x._1)).saveAsTextFile("/test/file1/")使用:
- 创建hello.txt文件,并写入内容
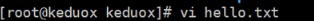
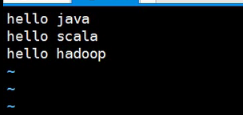
- 使用spark - shell

- 测试

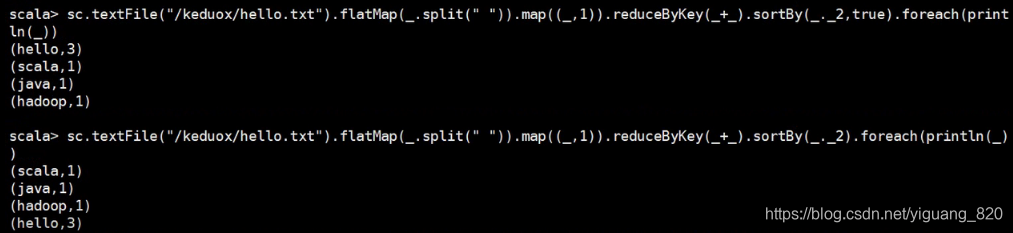
五.创建sprak项目
方法一:使用scala IDE 开发spark项目,简要步骤:
- 第一步:下载Scala IDE:eclipse集成scala
- 第二步:使用Scala IDE创建test项目,设置scala版本(右键项目 => build path => Configure build path => add Library => Scala Libaray)(不设置scala版本,会报错:Exception in thread "main" java.lang.NoSuchMethodError: scala.collection.immutable.HashSet$.empty()Lscala/collection/immutable/HashSet;)
- 第三步:根据Scala版本添加spark.jar包(下载spark,解压,将lib目录下的jar包导入到项目)

- 第四步:如果没有此步骤会报错:Could not locate executable null\bin\winutils.exe in the Hadoop binaries
下载相对应的Hadoop-2.6.0,解压,并设置环境变量
下载winutils.exe:
链接:https://pan.baidu.com/s/1bufm_9Qz4J9NCH2ITP4Zlg
提取码:ept3
解压后,将winutils.exe放到$HADOOP_HOME/bin/目录下 - 第五步:编写代码
package test import org.apache.spark.SparkConf import org.apache.spark.SparkContext import org.apache.spark.SparkContext._ import org.apache.spark.rdd.RDD object SparkFirst { def main(args: Array[String]): Unit = { val conf=new SparkConf().setAppName("HelloSpark").setMaster("local[2]") val sc=new SparkContext(conf) val arr=Array(2,3,4,5,6,7) val r1:RDD[Int]=sc.makeRDD(arr) println(r1.count()) } } - 第六步:最终项目结构:
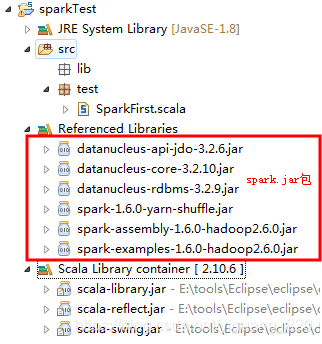
- 第七步:运行

- 注意:scala、spark、hadoop这三者的版本要相互兼容即可,而不是非得按照上面的教程中的版本
方法二:使用maven开发spark项目,简要步骤:
- 在Eclipse 中创建scala的maven项目test
- 创建之后,将pom.xml文件内不要的内容进行删除
- 删除test中不要的类和APP对象
- 让maven项目关联我们自己的scala
- 加入spark的依赖包
<dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.10</artifactId> <version>1.6.3</version> </dependency> - 如果采用的scala版本与spark要求的版本不一致时,会报错
修改scala的版本,采用绿色版,解压 --> 手动配置一下。 - 编写代码
package test import org.apache.spark.SparkConf import org.apache.spark.SparkContext import org.apache.spark.SparkContext._ import org.apache.spark.rdd.RDD object SparkFirst { def main(args: Array[String]): Unit = { val conf=new SparkConf().setAppName("HelloSpark").setMaster("local[2]") val sc=new SparkContext(conf) sc.textFile("E://a.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).foreach(println) } } /* *异常:System memory 259522560 must be at least 4.718592E8.Please use a large heap size *解决办法:http://blog.youkuaiyun.com/yizheyouye/article/details/50676022 */
说明:
六.Spark运行模式

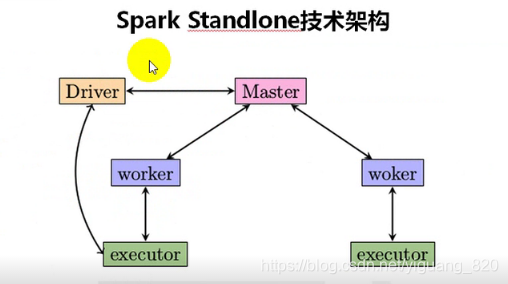
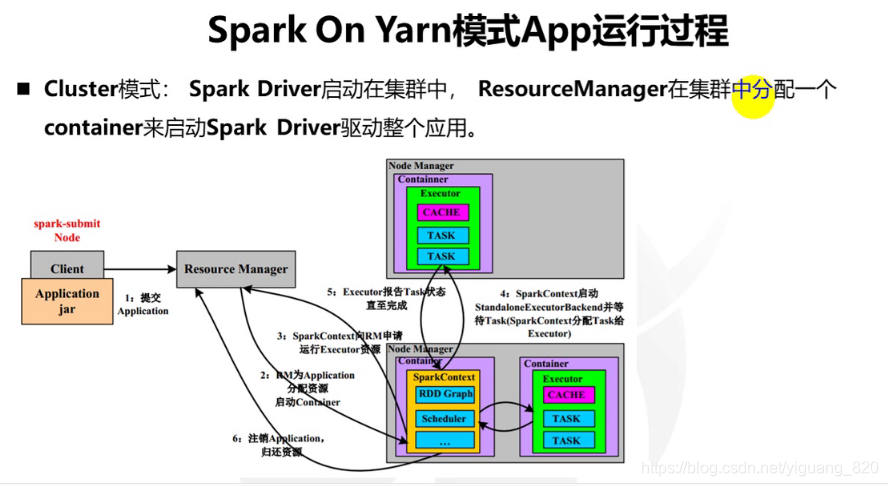
- Client 向RM提交Aplication
- RM为Application分配资源,启动Container
- SparkContext向RM申请资源,运行Excutor资源
- SparkContext启动StandaloneExecutorBackend并等待Task(SparkContext分配Task给Executor)
- Executor报告Task状态直至完成
- 注销Application,归还资源
七.Spark基础架构
- Spark架构采用了分布式计算中的Master-Slave模型;
- Master是对应集群中的含有Master进程的节点(ClusterManager);
- Slave是进程中含有Worker进程的节点。
- Master作为整个集群的控制器,负责整个集群的正常运行;
- Worker相当于是计算节点,接收主节点命令与进行状态汇报;
- Executor负责任务的执行,运行在Worker节点(在Yarn模式中,Master节点即为ResourceManager节点,Slave节点即为NodeManager节点)。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









