




 本文是关于C++ Prime的学习笔记,涵盖了C++的基础知识,包括头文件、编译器、输入输出、变量类型、复合类型如引用和指针、const的理解、字符串、向量、数组的操作等内容。重点讲解了如何初始化、操作和比较string对象,以及如何处理数组和多维数组。还讨论了内存管理,如new和delete操作符,以及动态长度的数组。文章深入浅出地介绍了C++中动态内存分配的概念和使用。
本文是关于C++ Prime的学习笔记,涵盖了C++的基础知识,包括头文件、编译器、输入输出、变量类型、复合类型如引用和指针、const的理解、字符串、向量、数组的操作等内容。重点讲解了如何初始化、操作和比较string对象,以及如何处理数组和多维数组。还讨论了内存管理,如new和delete操作符,以及动态长度的数组。文章深入浅出地介绍了C++中动态内存分配的概念和使用。
笔试准备
- 参考
- C++ Prime
- 第一章 开始
- 第二章 变量和基本类型
- 第三章 字符串、向量和数组
- 1. C++ 传递数组给函数
- 2. delete() in C++
- 3. 栈内存和堆内存的区别
- 4. 数组初始化0
- 5. malloc和new有什么区别?
- malloc() vs new
- 【重要!】new and delete operators in C++ for dynamic memory
- 动态长度的数组
- 6. sizeof
- C++输入字符串
- 深拷贝vs浅拷贝
- VS各种配置
参考
https://zhuanlan.zhihu.com/p/24355379
https://github.com/czs108/Cpp-Primer-5th-Note-CN/

C++ Prime
第一章 开始
头文件
"<>"表示来自标准库的头文件
“”表示非标准库的文件
编译器
GNU编译器的命令是 g++
$ g++ -o prog1 prog1.cc
visual studio 2010编译器的命令是c1
C:\user\> c1 /EHsc prog1.cpp // /EHsc是编译器选项
输入输出iostream
标准库定义了4个IO对象,cin/cout/cerr/clog
cin是istream的对象
>>是输入运算符,返回值是左侧运算对象,所以可以连续赋值
while(std::cin >> value) "std::cin >> value"结果是返回左侧对象,检测流的状态,直到遇到文件结束符(end of file),或者是错误的输入(比如输入和对应数据类型不符合时)
endl是操纵符,结束当前行,并将与设备关联的缓冲区的内容刷到设备中,是的所有输出都真正地写入输入流。
第二章 变量和基本类型
32位和64位编译器区别及int字节数
具体占几位要根据编译器的字长来确定

C/C++ 数据范围int
1 字节(byte) = 8 bit
字是根据机器的字长而定的,32位机器,则一个字是由4字节组成;64位机器,一个字由8字节组成


变量类型选择
一个char的大小和一个机器字节一样,确保可以存放机器基本字符集中任意字符对应的数字值。wchar_t确保可以存放机器最大扩展字符集中的任意一个字符。
-
在整型类型大小方面,C++规定short ≤ int ≤ long ≤ long long(long long是C++11定义的类型)。
-
浮点型可表示单精度(single-precision)、双精度(double-precision)和扩展精度(extended-precision)值,分别对应float、double和long double类型。
-
除去布尔型和扩展字符型,其他整型可以分为**带符号(signed)和无符号(unsigned)**两种。带符号类型可以表示正数、负数和0,无符号类型只能表示大于等于0的数值。类型int、short、long和long long都是带符号的,在类型名前面添加unsigned可以得到对应的无符号类型,如unsigned int。
-
字符型分为char、signed char和unsigned char三种,但是**表现形式只有带符号和无符号两种。**类型char和signed char并不一样, char的具体形式由编译器(compiler)决定。
如何选择算数类型:
-
当明确知晓数值不可能为负时,应该使用无符号类型。【好处在于正数范围大了2倍】
-
使用int执行整数运算,如果数值超过了int的表示范围,应该使用long long类型。
-
在算数表达式中不要使用char和bool类型。如果需要使用一个不大的整数,应该明确指定它的类型是signed char还是unsigned char。
-
执行浮点数运算时建议使用double类型。float通常精度不够。float与double的计算代价相差无几,long double没必要,耗费较大。
-
把浮点数赋给整数类型时,进行近似处理,结果值仅保留浮点数中的整数部分。
-
把整数值赋给浮点类型时,小数部分记为0。如果该整数所占的空间超过了浮点类型的容量,精度可能有损失。
-
赋给无符号类型一个超出它表示范围的值时,结果是初始值对无符号类型表示数值总数(8比特大小的unsigned char能表示的数值总数是256)取模后的余数。
-
赋给带符号类型一个超出它表示范围的值时,结果是未定义的(undefined)。
unsigned int 当u等于0时,**–u的结果将会是4294967295。**一种解决办法是用while语句来代替for语句,前者可以在输出变量前先减去1。
unsigned u = 11; // start the loop one past the first element we want to print
while (u > 0)
{
--u; // decrement first, so that the last iteration will print 0
std::cout << u << std::endl;
}
变量(Variables)
- 变量定义(Variable Definitions)
变量定义的基本形式:类型说明符(type specifier)后紧跟由一个或多个变量名组成的列表,其中变量名以逗号分隔,最后以分号结束。定义时可以为一个或多个变量赋初始值(初始化,initialization)。
初始化不等于赋值(assignment)。初始化的含义是创建变量时赋予其一个初始值,而赋值的含义是把对象的当前值擦除,再用一个新值来替代。
用花括号初始化变量称为列表初始化(list initialization)。当用于内置类型的变量时,如果使用了列表初始化并且初始值存在丢失信息的风险,则编译器会报错。
// 初始化方法(4种)
int a = 0;
int a(0);
int a = {0};
int a{0}; //等价于int d = 0, 也等价于int d(0)
//使用花括号{}来初始化有一个很6的地方(当它跟类型转换混一起的时候),它不允许你丢失信息,
long double ld = 3.1415926536;
int a{ld}, b = {ld}; // error: narrowing conversion required
int c(ld), d = ld; // ok: but value will be truncated,一般是用()或者=直接copy
如果定义变量时未指定初值,则变量被默认初始化(default initialized)。
对于内置类型,定义于任何函数体之外的变量被初始化为0,函数体内部的变量将不被初始化**(uninitialized)**。(定义于函数体内的内置类型对象如果没有初始化,则其值未定义,使用该类值是一种错误的编程行为且很难调试。类的对象如果没有显式初始化,则其值由类确定。)
复合类型(Compound Type)
- 引用(References)
引用为对象起了另外一个名字,引用类型引用(refers to)另外一种类型。通过将声明符写成**&d**的形式来定义引用类型,其中d是变量名称。
int ival = 1024;
int &refVal = ival; // refVal refers to (is another name for) ival
int &refVal2; // error: a reference must be initialized
定义引用时,程序把引用和它的初始值绑定(bind)在一起,而不是将初始值拷贝给引用。一旦初始化完成,将无法再令引用重新绑定到另一个对象,【关系确定之后不再改变,真专一呀哈哈哈】因此引用必须初始化。
引用不是对象,它只是为一个已经存在的对象所起的另外一个名字。
声明语句中引用的类型实际上被用于指定它所绑定的对象类型。大部分情况下,引用的类型要和与之绑定的对象严格匹配。
引用只能绑定在对象上,不能与字面值或某个表达式的计算结果绑定在一起。
- 指针(Pointer)
与引用类似,指针也实现了对其他对象的间接访问。
- 指针本身就是一个对象,允许对指针赋值和拷贝,而且在生命周期内它可以先后指向不同的对象。【指针就很多情了】
- 指针无须在定义时赋初值。和其他内置类型一样,在块作用域内定义的指针如果没有被初始化,也将拥有一个不确定的值。
通过将声明符写成d的形式来定义指针类型,其中d是变量名称。如果在一条语句中定义了多个指针变量,则每个量前都必须有符号。
int *ip1, *ip2; // both ip1 and ip2 are pointers to int
double dp, *dp2; // dp2 is a pointer to double; dp is a double
指针存放某个对象的地址,要想获取对象的地址,需要使用取地址符&。
【&:两个作用,取地址+表引用类型】
int ival = 42;
int *p = &ival; // p holds the address of ival; p is a pointer to ival
因为引用不是对象,没有实际地址,所以不能定义指向引用的指针。
声明语句中指针的类型实际上被用于指定它所指向的对象类型。大部分情况下,指针的类型要和它指向的对象严格匹配。
指针的值(即地址)应属于下列状态之一:
- 指向一个对象。
- 指向紧邻对象所占空间的下一个位置。
- 空指针,即指针没有指向任何对象。
- 无效指针,即上述情况之外的其他值。
- 试图拷贝或以其他方式访问无效指针的值都会引发错误。
【*:两个含义:表示指针类型+ 解引用】
如果指针指向一个对象,可以使用解引用(dereference)符*来访问该对象。
int ival = 42;
int *p = &ival; // p holds the address of ival; p is a pointer to ival
cout << *p; // * yields the object to which p points; prints 42
给解引用的结果赋值就是给指针所指向的对象赋值。
解引用操作仅适用于那些确实指向了某个对象的有效指针。
空指针(null pointer)不指向任何对象,在试图使用一个指针前代码可以先检查它是否为空。得到空指针最直接的办法是用字面值nullptr来初始化指针。
旧版本程序通常使用NULL(预处理变量,定义于头文件cstdlib中,值为0)给指针赋值,但在C++11中,最好使用nullptr初始化空指针。
int *p1 = nullptr; // equivalent to int *p1 = 0;
int *p2 = 0; // directly initializes p2 from the literal constant 0
// must #include cstdlib
int *p3 = NULL; // equivalent to int *p3 = 0;
建议初始化所有指针。
void是一种特殊的指针类型,可以存放任意对象的地址,但不能直接操作void指针所指的对象。
- 理解复合类型的声明(Understanding Compound Type Declarations)
① 指向指针的指针(Pointers to Pointers):
int ival = 1024;
int *pi = &ival; // pi points to an int
int **ppi = π // ppi points to a pointer to an int

② 指向指针的引用(References to Pointers):
int i = 42;
int *p; // p is a pointer to int
int *&r = p; // r is a reference to the pointer p
r = &i; // r refers to a pointer; assigning &i to r makes p point to i
*r = 0; // dereferencing r yields i, the object to which p points; changes i to 0
面对一条比较复杂的指针或引用的声明语句时,从右向左阅读有助于弄清它的真实含义。
const的理解
在变量类型前添加关键字const可以创建值不能被改变的对象。const变量必须被初始化。
- const的引用(References to const)
把引用绑定在const对象上即为对常量的引用(reference to const)。对常量的引用不能被用作修改它所绑定的对象。
const int ci = 1024;
const int &r1 = ci; // ok: both reference and underlying object are const
r1 = 42; // error: r1 is a reference to const
int &r2 = ci; // error: non const reference to a const object
大部分情况下,引用的类型要和与之绑定的对象严格匹配。【const的对象要用const类型的引用】但是有两个例外:
初始化常量引用时允许用任意表达式作为初始值,只要该表达式的结果能转换成引用的类型即可。
int i = 42;
const int &r1 = i; // we can bind a const int& to a plain int object
const int &r2 = 42; // ok: r1 is a reference to const
const int &r3 = r1 * 2; // ok: r3 is a reference to const
int &r4 = r * 2; // error: r4 is a plain, non const reference
允许为**一个常量引用绑定非常量的对象、**字面值或者一般表达式。
double dval = 3.14;
const int &ri = dval;
【结论:常量引用可以绑定,①常量对象, ②非常常量对象,③结果能转换成引用的类型的表达式。常量对象必须要用常量引用来绑定,其他类型的引用不可以!】
- 指针和const(Pointers and const)
分为 指针的指向 和 指针本身
① 指向常量的指针(pointer to const)【const double *cptr = π 】 不能用于修改其所指向的对象。常量对象的地址只能使用指向常量的指针来存放,但是指向常量的指针可以指向一个非常量对象。
point -> const
【所谓指向常量的指针或者引用,不过是指针或者引用 “自以为是” 罢了,他们觉得自己指向了常量,所以自觉地不去修改所指对象的值】 【指向了你,且不会去改变你,而你可以自己选择改变】
const double pi = 3.14; // pi is const; its value may not be changed
double *ptr = π // error: ptr is a plain pointer
const double *cptr = π // ok: cptr may point to a double that is const
// cptr指向了一个对象,并且规定这个对象是常量(自以为是地规定了),const是用来修饰指针指向的对象的,而不是指针本身。
*cptr = 42; // error: cannot assign to *cptr
double dval = 3.14; // dval is a double; its value can be changed
cptr = &dval; // ok: but can't change dval through cptr
//可以指向非常量,但是dval的值可以改变,但是不能通过cptr改变!
② 常量指针(const pointer),定义语句中把 *放在const之前 用来说明指针本身是一个常量,常量指针(const pointer)必须初始化。
int errNumb = 0;
int *const curErr = &errNumb; //常量指针,curErr will always point to errNumb
const double pi = 3.14159;
const double *const pip = π // pip is a const pointer to a const object
// 指针的名字是 pip,从右往左看pip是const常量, 也就是说pip一旦确定了值(也就是指向),就不能改变了
指针本身是常量只是说明了绑定关系,并不代表不能通过指针修改其所指向的对象的值,【我爱你,即使你变了我也还是爱你。哈哈哈哈肉麻肉麻!】能否这样做完全依赖于其指向对象的类型。
- 顶层const(Top-Level const)
顶层const表示指针本身是个常量【const离指针变量名更近】,【重点是看变量本身是否可以改变,这个是对于指针类型(指针的值即指针的指向关系)或是int类型(int类型的值)都是通用的】
底层const(low-level const)表示指针所指的对象是一个常量。
指针类型既可以是顶层const也可以是底层const。
int i = 0;
int *const p1 = &i; // we can't change the value of p1; const is **top-level** 【规定了专一的绑定关系,所以是top-level级别的爱恋了哈哈哈】
const int ci = 42; // we cannot change ci; const is top-level
const int *p2 = &ci; // we can change p2; const is low-level
const int *const p3 = p2; // right-most const is top-level, left-most is not
const int &r = ci; // const in reference types is always low-level
当执行拷贝操作时,常量是顶层const还是底层const区别明显:
顶层const没有影响。拷贝操作不会改变被拷贝对象的值,因此拷入和拷出的对象是否是常量无关紧要。
i = ci; // ok: copying the value of ci; top-level const in ci is ignored
p2 = p3; // ok: pointed-to type matches; top-level const in p3 is ignored
拷入和拷出的对象必须具有相同的底层const资格。或者两个对象的数据类型可以相互转换。一般来说,非常量可以转换成常量,反之则不行。
int *p = p3; // error: p3 has a low-level const but p doesn't
p2 = p3; // ok: p2 has the same low-level const qualification as p3
p2 = &i; // ok: we can convert int* to const int*
int &r = ci; // error: can't bind an ordinary int& to a const int object
const int &r2 = i; // ok: can bind const int& to plain int
- constexpr和常量表达式(constexpr and Constant Expressions)
常量表达式(constant expressions)指值不会改变并且在编译过程就能得到计算结果的表达式。
一个对象是否为常量表达式由它的数据类型和初始值共同决定。
const int max_files = 20; // max_files is a constant expression
const int limit = max_files + 1; // limit is a constant expression
int staff_size = 27; // staff_size is not a constant expression
const int sz = get_size(); // sz is not a constant expression
C++11允许将变量声明为constexpr类型以便由编译器来验证变量的值是否是一个常量表达式。
constexpr int mf = 20; // 20 is a constant expression
constexpr int limit = mf + 1; // mf + 1 is a constant expression
constexpr int sz = size(); // ok only if size is a constexpr function
指针和引用都能定义成constexpr,但是初始值受到严格限制。constexpr指针的初始值必须是0、nullptr或者是存储在某个固定地址中的对象。
函数体内定义的普通变量一般并非存放在固定地址中,因此constexpr指针不能指向这样的变量。相反,函数体外定义的变量地址固定不变,可以用来初始化constexpr指针。
在constexpr声明中如果定义了一个指针,限定符constexpr仅对指针本身有效,与指针所指的对象无关。constexpr把它所定义的对象置为了顶层const。
constexpr int *p = nullptr; // p是指向int的const指针
constexpr int i = 0;
constexpr const int *cp = &i; // cp是指向const int的const指针
const和constexpr限定的值都是常量。但constexpr对象的值必须在编译期间确定,而const对象的值可以延迟到运行期间确定。
建议使用constexpr修饰表示数组大小的对象,因为数组的大小必须在编译期间确定且不能改变。
处理类型(Dealing with Types)
类型别名(Type Aliases)
类型别名是某种类型的同义词,传统方法是使用关键字typedef定义类型别名。
typedef double wages; // wages is a synonym for double
typedef wages base, *p; // base is a synonym for double, p for double*
C++11使用关键字using进行别名声明(alias declaration),作用是把等号左侧的名字规定成等号右侧类型的别名。
using SI = Sales_item; // SI is a synonym for Sales_item
auto类型说明符(The auto Type Specifier)
C++11新增auto类型说明符,能让编译器自动分析表达式所属的类型。auto定义的变量必须有初始值。
// the type of item is deduced from the type of the result of adding val1 and val2
auto item = val1 + val2; // item initialized to the result of val1 + val2
编译器推断出来的auto类型有时和初始值的类型并不完全一样。
当引用被用作初始值时,编译器以引用对象的类型作为auto的类型。
int i = 0, &r = i;
auto a = r; // a is an int (r is an alias for i, which has type int)
auto一般会忽略顶层const。
const int ci = i, &cr = ci;
auto b = ci; // b is an int (top-level const in ci is dropped)
auto c = cr; // c is an int (cr is an alias for ci whose const is top-level)
auto d = &i; // d is an int*(& of an int object is int*)
auto e = &ci; // e is const int*(& of a const object is low-level const)
如果希望推断出的auto类型是一个顶层const,需要显式指定const auto。
const auto f = ci; // deduced type of ci is int; f has type const int
设置类型为auto的引用时,原来的初始化规则仍然适用,初始值中的顶层常量属性仍然保留。
auto &g = ci; // g is a const int& that is bound to ci
auto &h = 42; // error: we can't bind a plain reference to a literal
const auto &j = 42; // ok: we can bind a const reference to a literal
decltype类型指示符(The decltype Type Specifier)
C++11新增decltype类型指示符,作用是选择并返回操作数的数据类型,此过程中编译器不实际计算表达式的值。
decltype(f()) sum = x; // sum has whatever type f returns
decltype处理顶层const和引用的方式与auto有些不同,如果decltype使用的表达式是一个变量,则decltype返回该变量的类型 (包括顶层const和引用) 。
const int ci = 0, &cj = ci;
decltype(ci) x = 0; // x has type const int, decltype(ci) 返回的是类型!
decltype(cj) y = x; // y has type const int& and is bound to x
decltype(cj) z; // error: z is a reference and must be initialized
int i;
decltype(i) e; // OK, e has type int;
decltype((i)) d; // error, int&, must be initialized;
如果decltype使用的表达式不是一个变量,则decltype返回表达式结果对应的类型。
如果表达式的内容是解引用操作,则decltype将得到引用类型。
如果decltype使用的是一个不加括号的变量,则得到的结果就是该变量的类型;如果给变量加上了一层或多层括号,则decltype会得到引用类型,因为变量是一种可以作为赋值语句左值的特殊表达式。
decltype((var))的结果永远是引用,而decltype(var)的结果只有当var本身是一个引用时才会是引用。
第三章 字符串、向量和数组
命名空间的using声明(Namespace using Declarations)
使用using声明后就无须再通过专门的前缀去获取所需的名字了。
using std::cout;
程序中使用的每个名字都需要用独立的using声明引入。
头文件中通常不应该包含using声明。
标准库类型string(Library string Type)
标准库类型string表示可变长的字符序列,定义在头文件string中。
定义和初始化string对象(Defining and Initializing strings)
初始化string的方式:

如果使用等号初始化一个变量,实际上执行的是拷贝初始化(copy initialization),编译器把等号右侧的初始值拷贝到新创建的对象中去。如果不使用等号,则执行的是直接初始化(direct initialization)。【书上的结论,没用“=”就叫直接初始化,如果要用到多个值来初始化,则一般只能使用直接初始化的方式】
string s("hello");
string s2 = string("hello"); //要显式地创建一个(临时)对象用于拷贝。
// 相当于以下两句话:
string s1("heloo");
string s2 = s1;w
string对象上的操作(Operations on strings)
string的操作:

在执行读取操作时,string对象会自动忽略开头的空白(空格符、换行符、制表符等)并从第一个真正的字符开始读取,直到遇见下一处空白为止。 如上所述,如果输入" hey zhou “,输出将是"hey”,不信你自己试试。 string对象也支持连续输入输出(这个是cin和cout的特性,以后会介绍原理)
string s1, s2;
cin >> s1 >> s2; //第一个输入到s1,第二个输入到s2
cout << s1 << s2 << endl; //输出两个string对象
这段程序如果输入" hey zhou “,输出是"heyzhou” 只有这样的一种输入方式肯定不够,因为它只能读取数量确定的一个一个的单词。
读取未知数量的string
使用getline函数可以读取一整行字符。该函数只要遇到换行符就结束读取并返回结果 【换行符被读进来了,但是不存被丢弃了!】 ,如果输入的开始就是一个换行符,则得到空string。触发getline函数返回的那个换行符实际上被丢弃掉了,得到的string对象中并不包含该换行符。
int main()
{
string word;
// cin 遇到空格就停止
//在执行读取操作时,string对象会自动忽略开头的空白(空格符、换行符、制表符等)并从第一个真正的字符开始读取,直到遇见下一处空白为止
while(cin >> word)
{
cout << word << endl;
}
return 0;
}
//有时候,我们还希望能在最终得到的字符串中保留输入的空白符,这时应该用getline函数代替>>。
int main()
{
string line;
while(getline(cin, line))
{
cout << line << endl;
}
return 0;
}
cin.getline(you_name, arsize); // getline将丢弃换行符,用空格‘\0’表示换行
cin.get(you_name, arsize); // get(arg1, arg2)将保留换行符在输入流中,所以下一步要通过cin.get()来读取换行符
cin.get(); //没有参数的get,或者接受一个char参数的get(ch)读取换行符
// cin.get(you_name, size).get() 等于上两句话的结合
size函数和empty函数
size函数返回string对象的长度,返回值是string::size_type类型 足够存销任何string对象的大小,这是一种无符号类型。要使用size_type,必须先指定它是由哪种类型定义的。
如果一个表达式中已经有了**size函数就不要再使用int了,**这样可以避免混用int和unsigned int可能带来的问题。
比较string对象
string s1 = "hello";
string s2 = "hello jay";
string s3 = "hi";
// result: s1<s2<s3. 长的更大,字母在后面的更大
当把string对象和字符字面值及字符串字面值混合在一条语句中使用时,必须确保每个加法运算符两侧的运算对象中至少有一个是string。
string s4 = s1 + ", "; // ok: adding a string and a literal
string s5 = "hello" + ", "; // error: no string operand
string s6 = s1 + ", " + "world"; // ok: each + has a string operand
为了与C兼容,C++语言中的字符串字面值并不是标准库string的对象。
处理string对象中的字符(Dealing with the Characters in a string)
头文件cctype中的字符操作函数:

建议使用C++版本的C标准库头文件。C语言中名称为name.h的头文件,在C++中则被命名为cname。
- 遍历
C++11提供了范围**for(range for)**语句,可以遍历给定序列中的每个元素并执行某种操作。
for (declaration : expression)
statement
expression部分是一个对象,用于表示一个序列。declaration部分负责定义一个变量,该变量被用于访问序列中的基础元素。每次迭代,declaration部分的变量都会被初始化为expression部分的下一个元素值。
string str("some string");
// print the characters in str one character to a line
for (auto c : str) // for every char in str 遍历str的每个字符
cout << c << endl; // print the current character followed by a newline
如果想在范围for语句中改变string对象中字符的值,必须把循环变量定义成引用类型。【for(auto &c : s)】
- 只访问一部分-下标运算
下标运算符接收的输入参数是string::size_type类型的值,表示要访问字符的位置,返回值是该位置上字符的引用。
下标数值从0记起,范围是0至size - 1。使用超出范围的下标将引发不可预知的后果。
C++标准并不要求标准库检测下标是否合法。编程时可以把下标的类型定义为相应的size_type,这是一种无符号数,可以确保下标不会小于0,此时代码只需要保证下标小于size的值就可以了。另一种确保下标合法的有效手段就是使用范围for语句。
来个难点的,编写一个程序把0-15之间的十进制数转换成对应的十六进制数(可以自己先想想先写写)
const string hex = "0123456789ABCDEF";
string res;
string::size_type n;
while(cin >> n)
{
if(n < 16)
{
res += hex[n]; //是不是很巧妙
}
cout << res << endl;
}
标准库类型vector(Library vector Type)
标准库类型vector表示对象的集合,也叫做容器(container),定义在头文件vector中。vector中所有对象的类型都相同,每个对象都有一个索引与之对应并用于访问该对象。
// 标准库类型vector表示对象的集合,其中所有对象的类型都相同。可以把vector看成一个容器,容器里面装的都是同一个类型的东西。 要想使用vector,必须包含适当的头文件
#include <vector>
using std::vector;
vector是模板(template)而非类型,由vector生成的类型必须包含vector中元素的类型,如vector。
vector : 模板
vector<int> : 类型
类模板实例化为类,类实例化为对象。 对于类模板来说,我们需要提供一些额外的信息来指定类模板到底实例化成什么样的类。 以vector为例:
vector<int> vec1; //vec1保存int对象
vector<vector<int>> vec2; //vec2保存vector<int>对象,相当于二维数组
因为引用不是对象,所以不存在包含引用的vector。
在早期的C++标准中,如果vector的元素还是vector,定义时必须在外层vector对象的右尖括号和其元素类型之间添加一个空格,如vector<vector >。但是在C++11标准中,可以直接写成vector<vector>,不需要添加空格。
定义和初始化vector对象(Defining and Initializing vectors)
初始化vector对象的方法:

vector<int> v1; //默认初始化,空vector
vector<int> v2(v1);
vector<int> v3 = v1;
vector<string> v4(5, "c"); //有5个字符串"c"
//可以只提供vector对象容纳的元素数量而省略初始值,此时会创建一个值初始化(value-initialized)的元素初值,并把它赋给容器中的所有元素。这个初值由vector对象中的元素类型决定。
vector<int> v5(5); //包含了5个重复执行默认初始化的对象,就是5个0,int默认初始化为0,
vector<int> v6{1, 2, 3};
vector<int> v7 = {1, 2, 3};
vector<string> v1("a", "b"); //错误
vector<string> v2{"a", "b"}; //正确:列表初始化
vector<int> v3(10, -1); //正确:10个-1
vector<int> v4{10, -1}; //正确:10,-1
vector<int> v5(10); //10个0,值默认初始化
vector<string> v6(10); //10个空string对象
// 二维数组初始化
vector<vector<int> > (m+1, vector<int>(n+1, 0)) //创建一个二维的vector(m*n维),并初始化为0
- 初始化vector对象时如果使用圆括号,可以说提供的值是用来**构造(construct)**vector对象的; 【圆括号初始化的用法 (num, init_val)】
- 如果使用的是花括号,则是在**列表初始化(list initialize)**该vector对象 【花括号初始化的用法 {init_val1, init_val2, …, init_val3}】 。另一方面,如果初始化使用了花括号的形式但是提供的值又不能用来列表初始化,就要考虑用这样的值来构造vector对象了 【花括号不能列表初始化时,改成构造的用法 {num, init_val}, 同圆括号了】
向vector对象中添加元素(Adding Elements to a vector)动态数组!
push_back函数可以把一个值添加到vector的尾端。
vector<int> v2; // empty vector
for (int i = 0; i != 100; ++i)
v2.push_back(i); // append sequential integers to v2
// at end of loop v2 has 100 elements, values 0 . . . 99
范围for语句体内不应该改变其所遍历序列的大小。
其他vector操作(Other vector Operations)
vector支持的操作:

size函数返回vector对象中元素的个数,返回值是由vector定义的size_type类型。vector对象的类型包含其中元素的类型。
vector<int>::size_type // ok
vector::size_type // error
vector和string对象的下标运算符只能用来访问已经存在的元素,而不能用来添加元素。
vector<int> ivec; // empty vector
for (decltype(ivec.size()) ix = 0; ix != 10; ++ix)
{
ivec[ix] = ix; // disaster: ivec has no elements
ivec.push_back(ix); // ok: adds a new element with value ix
}
迭代器介绍(Introducing Iterators)
迭代器的作用和下标类似,但是更加通用。所有标准库容器都可以使用迭代器, 但是其中只有少数几种同时支持下标运算符。
使用迭代器(Using Iterators)
定义了迭代器的类型都拥有begin和end两个成员函数 。begin函数 返回 指向第一个元素的迭代器,end函数 返回指向容器 “尾元素的下一位置(one past the end)” 的迭代器,通常被称作尾后迭代器(off-the-end iterator)或者简称为尾迭代器(end iterator)。尾后迭代器仅是个标记,表示程序已经处理完了容器中的所有元素。迭代器一般为iterator类型 (有点类似指针!用对应元素的时候要用 解引用迭代器*)。
// b denotes the first element and e denotes one past the last element in ivec
vector<int>::iterator b,e; //it能读写vector<int>的元素
//如果vector或string对象是常量,则只能使用const_iterator迭代器,该迭代器只能读元素,不能写元素。
//begin和end返回的迭代器具体类型由对象是否是常量决定,如果对象是常量,则返回const_iterator;如果对象不是常量,则返回iterator。
vector<int>::const_iterator it2; //is只能读vector<int>的元素
vector<int> v;
const vector<int> cv;
auto b= v.begin(); //b的类型是vector<int>::iterator
auto e = v.end(); //e的类型是vector<int>::iterator
auto it2 = cv.begin(); //it2的类型和b,e不一样哦,是vector<int>::const_iterator
如果容器为空,则begin和end返回的是同一个迭代器,都是尾后迭代器。
标准容器迭代器的运算符:
因为end返回的迭代器并不实际指向某个元素,所以不能对其进行递增或者解引用的操作。
在for或者其他循环语句的判断条件中,最好使用**!=**而不是<。所有标准库容器的迭代器都定义了==和!=,但是只有其中少数同时定义了<运算符。
任何可能改变容器对象容量的操作,都会使该对象的迭代器失效。
接下来的程序厉害了,算是我们写到现在第一个实用的程序,**二分查找,**不知道二分查找的点我,text是一个从小到大排好序的容器:
// 作者:苍井玛利亚
// 链接:https://www.nowcoder.com/discuss/19777
// 来源:牛客网
//text必须是有序的,我们要找的是target
auto beg = text.cbegin(), end = text.cend();
auto mid = (end + beg)/2; //中间点
while(mid != end && *mid != target)
{
if(target < *mid) //我们要找的元素是否在前半部分
{
end = mid; //如果是,则忽略后半部分
}
else //我们要找的元素在后半部分
{
beg = mid + 1; //忽略前半部分
}
mid = (end + beg)/2; //更新中间点
}
迭代器运算(Iterator Arithmetic)
vector和string迭代器支持的操作:

difference_type类型用来表示两个迭代器间的距离,这是一种带符号整数类型。
数组(Arrays)
Array vs. Vector
数组类似vector,但数组的大小确定不变,不能随意向数组中添加元素。
如果不清楚元素的确切个数,应该使用vector。
定义和初始化内置数组(Defining and Initializing Built-in Arrays)
数组是一种复合类型,声明形式为a[d],其中a是数组名称,d是数组维度(dimension)。维度必须是一个常量表达式。
默认情况下,数组的元素被默认初始化。
定义数组的时候必须指定数组的类型,不允许用auto关键字由初始值列表推断类型。
如果定义数组时提供了元素的初始化列表,则允许省略数组维度,编译器会根据初始值的数量计算维度。但如果显式指明了维度,那么初始值的数量不能超过指定的大小。如果维度比初始值的数量大,则用提供的值初始化数组中靠前的元素,剩下的元素被默认初始化。
const unsigned sz = 3;
int ia1[sz] = {0,1,2}; // array of three ints with values 0, 1, 2
int a2[] = {0, 1, 2}; // an array of dimension 3
int a3[5] = {0, 1, 2}; // **equivalent to a3[] = {0, 1, 2, 0, 0}**
string a4[3] = {"hi", "bye"}; // same as a4[] = {"hi", "bye", ""}
int a5[2] = {0,1,2}; // error: too many initializers
可以用字符串字面值初始化字符数组,但字符串字面值结尾处的空字符也会一起被拷贝到字符数组中。
// '\0' = null
char a1[] = {'C', '+', '+'}; // list initialization, no null
char a2[] = {'C', '+', '+', '\0'}; // list initialization, explicit null
char a3[] = "C++"; // null terminator added automatically
const char a4[6] = "Daniel"; // error: no space for the null!
数组还有个奇怪的地方是:不允许拷贝和复制,换句话说,你只能初始化它,so不能用一个数组初始化或直接赋值给另一个数组。
从数组的名字开始由内向外阅读有助于理解复杂数组声明的含义。记住从右到左看,有括号先看括号
int *ptrs[10]; //ptrs是数组,数组里面的元素类型是int *,含有10个类型是int*指针类型元素的数组 (int *) ptrs[10]; <= int ptrs[10];
int (*parray)[10]; //parray是指针,指向含有10个元素的数组
int &refs[10] = ptrs; //ref是数组,数组里面的元素是引用,
//难道就这么简单?不是的——>因为引用不是对象,这个定义错了
int (&arrRef)[10] = arr; //arrRef是一个引用,引用了一个含有10个整数的数组
int *(&arry)[10] = ptrs; //首先看括号,括号里表示arry是个引用,括号看完了
//接下来从右往左看,引用的对象是一个大小为10的数组,最后看左边知道
//数组的元素类型是指针,指针的类型是int
// 所以是一个含有10个int*指针类型元素的数组的引用!
访问数组元素(Accessing the Elements of an Array)
数组下标通常被定义成size_t类型,这是一种机器相关的无符号类型,可以表示内存中任意对象的大小。size_t定义在头文件cstddef中。
大多数常见的安全问题都源于缓冲区溢出错误。当数组或其他类似数据结构的下标越界并试图访问非法内存区域时,就会产生此类错误。
指针和数组(Pointers and Arrays)
数组还有一个特性,在很多用到数组名字的地方,编译器会自动将数组名字替换为指向数组首元素的指针:
string nums[] = {"one", "two", "three"}; // array of strings
string *p = &nums[0]; // p points to the first element in nums
string *p0 = nums; //等价于string p0 = &nums[0];
一维数组寻址公式:
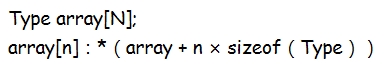
当使用数组作为一个auto变量的初始值时,推断得到的类型是指针而非数组。但decltype关键字不会发生这种转换,直接返回数组类型。
int ia[] = {0,1,2,3,4,5,6,7,8,9}; // ia is an array of ten ints
auto ia2(ia); // ia2 is an int* that points to the first element in ia
ia2 = 42; // error: ia2 is a pointer, and we can't assign an int to a pointer
auto ia2(&ia[0]); // now it's clear that ia2 has type int*
// ia3 is an array of ten ints
decltype(ia) ia3 = {0,1,2,3,4,5,6,7,8,9};
ia3 = p; // error: can't assign an int* to an array
ia3[4] = i; // ok: assigns the value of i to an element in ia3
C++11在头文件iterator中定义了两个名为begin和end的函数,功能与容器中的两个同名成员函数类似,参数是一个数组。
int ia[] = {0,1,2,3,4,5,6,7,8,9}; // ia is an array of ten ints
int *beg = begin(ia); // pointer to the first element in ia
int *last = end(ia); // pointer one past the last element in ia
两个指针相减的结果类型是ptrdiff_t,这是一种定义在头文件cstddef中的带符号类型。
标准库类型限定使用的下标必须是无符号类型,而内置的下标运算无此要求。
C风格字符串(C-Style Character Strings)
C风格字符串是将字符串存放在字符数组中,并以空字符结束(null terminated)。这不是一种类型,而是一种为了表达和使用字符串而形成的书写方法。
C++标准支持C风格字符串,但是最好不要在C++程序中使用它们。对大多数程序来说,使用标准库string要比使用C风格字符串更加安全和高效。
C风格字符串的函数:
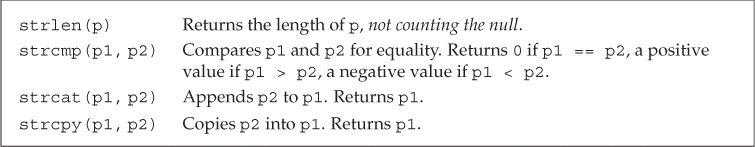
C风格字符串函数不负责验证其参数的正确性,传入此类函数的指针必须指向以空字符作为结尾的数组。
与旧代码的接口(Interfacing to Older Code)
任何出现字符串字面值的地方都可以用以空字符结束的字符数组来代替:
允许使用以空字符结束的字符数组来初始化string对象或为string对象赋值。
在string对象的加法运算中,允许使用以空字符结束的字符数组作为其中一个运算对象(不能两个运算对象都是)。
在string对象的复合赋值运算中,允许使用以空字符结束的字符数组作为右侧运算对象。
不能用string对象直接初始化指向字符的指针。为了实现该功能,string提供了一个名为c_str的成员函数,返回const char*类型的指针,指向一个以空字符结束的字符数组,数组的数据和string对象一样。
string s(“Hello World”); // s holds Hello World
char str = s; // error: can’t initialize a char from a string
const char *str = s.c_str(); // ok
针对string对象的后续操作有可能会让c_str函数之前返回的数组失去作用,如果程序想一直都能使用其返回的数组,最好将该数组重新拷贝一份。
可以使用数组来初始化vector对象,但是需要指明要拷贝区域的首元素地址和尾后地址。
int int_arr[] = {0, 1, 2, 3, 4, 5};
// ivec has six elements; each is a copy of the corresponding element in int_arr
vector ivec(begin(int_arr), end(int_arr));
在新版本的C++程序中应该尽量使用vector、string和迭代器,避免使用内置数组、C风格字符串和指针。
多维数组(Multidimensional Arrays)
C++中的多维数组其实就是数组的数组。当一个数组的元素仍然是数组时,通常需要用两个维度定义它:一个维度表示数组本身的大小,另一个维度表示其元素(也是数组)的大小。通常把二维数组的第一个维度称作行,第二个维度称作列。
多维数组初始化的几种方式:
int ia[3][4] =
{ // three elements; each element is an array of size 4
{0, 1, 2, 3}, // initializers for the row indexed by 0
{4, 5, 6, 7}, // initializers for the row indexed by 1
{8, 9, 10, 11} // initializers for the row indexed by 2
};
// equivalent initialization without the optional nested braces for each row
int ib[3][4] = {0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11};
// explicitly initialize only element 0 in each row
int ic[3][4] = {{ 0 }, { 4 }, { 8 }};
// explicitly initialize row 0; the remaining elements are value initialized
int id[3][4] = {0, 3, 6, 9};
可以使用下标访问多维数组的元素,数组的每个维度对应一个下标运算符。如果表达式中下标运算符的数量和数组维度一样多,则表达式的结果是给定类型的元素。如果下标运算符数量比数组维度小,则表达式的结果是给定索引处的一个内层数组。
// assigns the first element of arr to the last element in the last row of ia
ia[2][3] = arr[0][0][0];
int (&row)[4] = ia[1]; // binds row to the second four-element array in ia
多维数组寻址公式:

使用范围for语句处理多维数组时,为了避免数组被自动转换成指针,语句中的外层循环控制变量必须声明成引用类型。
for (const auto &row : ia) // for every element in the outer array
for (auto col : row) // for every element in the inner array
cout << col << endl;
如果row不是引用类型,编译器初始化row时会自动将数组形式的元素转换成指向该数组内首元素的指针,这样得到的row就是int类型,而之后的内层循环则试图在一个int内遍历,程序将无法通过编译。
for (auto row : ia)
for (auto col : row)
使用范围for语句处理多维数组时,除了最内层的循环,其他所有外层循环的控制变量都应该定义成引用类型。
因为多维数组实际上是数组的数组,所以由多维数组名称转换得到的指针指向第一个内层数组。
int ia[3][4]; // array of size 3; each element is an array of ints of size 4
int (*p)[4] = ia; // p points to an array of four ints
p = &ia[2]; // p now points to the last element in ia
声明指向数组类型的指针时,必须带有圆括号。
int *ip[4]; // array of pointers to int
int (*ip)[4]; // pointer to an array of four ints
使用auto和decltype能省略复杂的指针定义。
// print the value of each element in ia, with each inner array on its own line
// p points to an array of four ints
for (auto p = ia; p != ia + 3; ++p)
{
// q points to the first element of an array of four ints; that is, q points to an int
for (auto q = *p; q != *p + 4; ++q)
cout << *q << ' ';
cout << endl;
}
1. C++ 传递数组给函数
C++ 中您可以通过指定不带索引的数组名来传递一个指向数组的指针。
C++ 传数组给一个函数,数组类型自动转换为指针类型,因而传的实际是地址。
如果您想要在函数中传递一个一维数组作为参数,您必须以下面三种方式来声明函数形式参数,这三种声明方式的结果是一样的,因为每种方式都会告诉编译器将要接收一个整型指针。同样地,您也可以传递一个多维数组作为形式参数。
方式 1
形式参数是一个指针:
void myFunction(int *param)
方式 2
形式参数是一个已定义大小的数组:
void myFunction(int param[10])
方式 3
形式参数是一个未定义大小的数组:
void myFunction(int param[])
2. delete() in C++
Delete is an operator that is used to destroy array and non-array(pointer) objects which are created by new expression.
https://www.geeksforgeeks.org/delete-in-c/
- Delete can be used by either using Delete operator or Delete [ ] operator
- New operator is used for dynamic memory allocation which puts variables on heap memory.
- Which means Delete operator deallocates memory from heap.
- Pointer to object is not destroyed, value or memory block pointed by pointer is destroyed.
- Deleting NULL pointer : Deleting a NULL does not cause any change and no error.
3. 栈内存和堆内存的区别
https://blog.youkuaiyun.com/richerg85/article/details/19175133
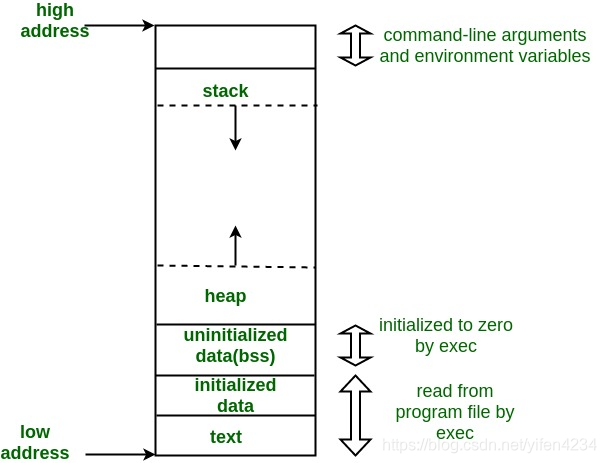
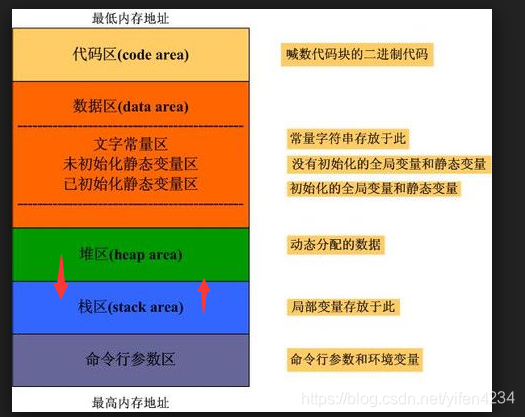
Memory Layout of C Programs
https://www.geeksforgeeks.org/memory-layout-of-c-program/
A typical memory representation of C program consists of following sections.
- Text segment
- Initialized data segment
- Uninitialized data segment
- Stack
- Heap

4. 数组初始化0
栈内存用 int a[size] = {0};
堆内存分配好了用memset或者直接用calloc分配
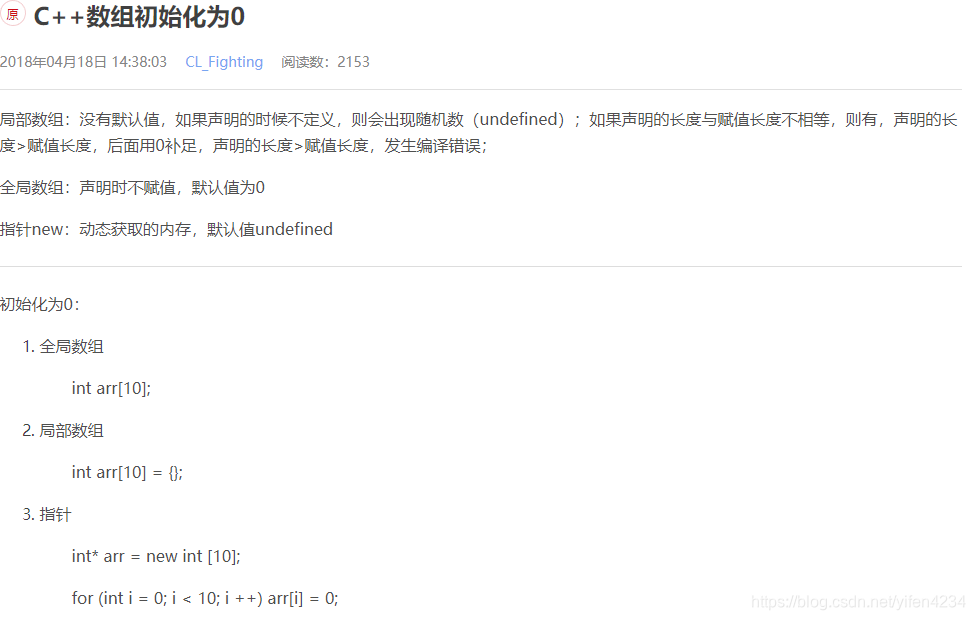
迭代器
# include <vector>
vector<int> v; //创建一个类型为 vector<int> 类型的向量v;
vector<int>::iterator it;//创造一个类型为迭代器类型的 vetcor<int>::iterator 的迭代器it
it = v.begin(); //让it指向v的头部
it_end = v.end(); //让it指向v的尾部的下一个位置
vector<vector<int> > (m+1, vector<int>(n+1, 0)) //创建一个二维的vector(m*n维),并初始化为0
begin( ) 函数返回一个指向向量开头的迭代器。
end( ) 函数返回一个指向向量末尾的迭代器。
5. malloc和new有什么区别?
链接:https://www.nowcoder.com/questionTerminal/84c6de43ca954bbbb5581d9cfbb60431
来源:牛客网
1.操作对象有所不同
malloc和free是c++/c语言的标准库函数;而new和delete是c++的运算符,对于非内部数据类的对象而言,光用malloc无法满足动态对象的要求,因为对象在创建的时候要执行构造函数,对象在消亡之前要执行析构函数。由于malloc是库函数而不是运算符,不在编译器控制权限之内,不能把执行构造函数和析构函数的任务强加malloc.
2.用法上不同
1)malloc函数原型: void malloc(size_t size) ;用malloc申请一块长度为length的整数类型的内存,程序为:int p = (int)malloc(sizeof(int)length);
注意2点:A:类型转换,因为malloc的类型为void;B:sizeof
malloc本身并不识别要申请的内存是什么类型,它只关心内存的总字节数。
2)对比malloc,new要简单一些
int p1 = (int*)malloc(sizeof(int)length);
int p2 = new int[length];
这是因为new内置了sizeof. 类型转换和类型安全检查功能。
malloc() vs new
Following are the differences between malloc() and operator new.:
- Calling Constructors: new calls constructors, while malloc() does not. In fact primitive data types (char, int, float… etc) can also be initialized with new. == For example, below program prints 10.
#include<iostream>
using namespace std;
int main()
{
int *n = new int(10); // 新建一个值,initialization with new() 这里10表示初值
cout << *n; // 10;
int *m = new int{10}; // 10,开位置+初始化
int *p = new int; // -842150451, 开位置+初始化
// int a = new int(10); // error: int* 类型的值不能用于初始化int类型的实体
int *a = new int[10]; // 新建一个数组
for (int i = 0; i < 10; i ++)
cout << a[i] << endl;
/*
-842150451
...
-842150451
*/
cout << *a << endl; //-842150451
cout << "******" << endl;
int *b = new int[10](); // ()这个才调用了构造函数!
for (int i = 0; i < 10; i++)
cout << b[i] << endl;
/*
0
...
0
*/
cout << *b << endl; // 0
return 0;
}
// 如果是 a
- operator vs function: new is an operator, while malloc() is a function.
- return type: new returns exact data type (the pointer variable), while malloc() returns **void ***.
- Failure Condition: On failure, malloc() returns NULL where as new Throws.
- Memory: In case of new, memory is allocated from free store where as in malloc() memory allocation is done from heap.
- Overriding: We are allowed to override new operator where as we can not override the malloc() function legally.
- Size: Required size of memory is calculated by compiler for new, where as we have to manually calculate size for malloc().

【重要!】new and delete operators in C++ for dynamic memory
https://www.geeksforgeeks.org/new-and-delete-operators-in-cpp-for-dynamic-memory/
Dynamic memory allocation in C/C++ refers to performing memory allocation manually by programmer. Dynamically allocated memory is allocated on Heap and non-static and local variables get memory allocated on Stack (Refer Memory Layout C Programs for details).https://www.geeksforgeeks.org/memory-layout-of-c-program/
What are applications?
- One use of dynamically allocated memory is to allocate memory of variable size which is not possible with compiler allocated memory except variable length arrays.
- The most important use is flexibility provided to programmers. We are free to allocate and deallocate memory whenever we need and whenever we don’t need anymore. There are many cases where this flexibility helps. Examples of such cases are Linked List, Tree, etc.
动态分配内存的一个用途是分配可变大小的内存,这在编译器分配内存时是不可能的,除了可变长度数组。
最重要的用途是为程序员提供灵活性。我们可以在任何需要和不再需要的时候自由地分配和释放内存。例如:链表、树等。
How is it different from memory allocated to normal variables? - For normal variables like “int a”, “char str[10]”, etc, memory is automatically allocated and deallocated.
- For dynamically allocated memory like “int *p = new int[10]”, it is programmers responsibility to deallocate memory when no longer needed. If programmer doesn’t deallocate memory, it causes memory leak (内存泄露)(memory is not deallocated until program terminates).
1. new operator[堆上申请空间]
The new operator denotes a request for memory allocation on the Heap. If sufficient memory is available, new operator initializes the memory and returns the address of the newly allocated and initialized memory to the pointer variable.
Syntax to use new operator: To allocate memory of any data type, the syntax is:
int *p = NULL;
p = new int;
//or
int *p = new int;
Initialize memory: We can also initialize the memory using new operator:
int *arr[10]; // 非动态 Hint: We can create a non-dynamic array using int *arr[10];
int *p = new int(25); // 动态内存
float *q = new float(75.25);
// 自己测试
int g[10]; // 初始化,00000
void func(){
int *b = new int[10](); // 调用默认初始化, 0,0,0,0...
int e[10]; //-858993460,-858993460...
int *c = new int[10]; // -842150451,-842150451...
int *c = new int(10) // OK! 10,单个数可以定初始值!
int *j = new int[10](0); // 不能为数组指定初始值,不能用圆括号确定初始值!
int *k = new int[3]{1,2,3}; // 1,2,3
int d[1000] = { 0 }; // 0,0,0....
int h[1000] = { 1 }; // 1,0,0....
}
Allocate block of memory: new operator is also used to allocate a block(an array) of memory of type data-type.
int *p = new int[10]
Dynamically allocates memory for 10 integers continuously of type int and returns pointer to the first element of the sequence, which is assigned to p(a pointer). p[0] refers to first element, p[1] refers to second element and so on.
2. deleteoperator
Since it is programmer’s responsibility to deallocate dynamically allocated memory, programmers are provided delete operator by C++ language.
//delete pointer-variable;
delete p;
delete[] p;
动态长度的数组
void fun(int n)
{
int arr[n];
// ......
}
int main()
{
fun(6);
}
But C++ standard (till C++11) doesn’t support variable sized arrays. (不支持动态长度的数组,array的size必须要是常量)。The C++11 standard mentions array size as a constant-expression。The program may work in GCC compiler, because GCC compiler provides an extension to support them.
6. sizeof
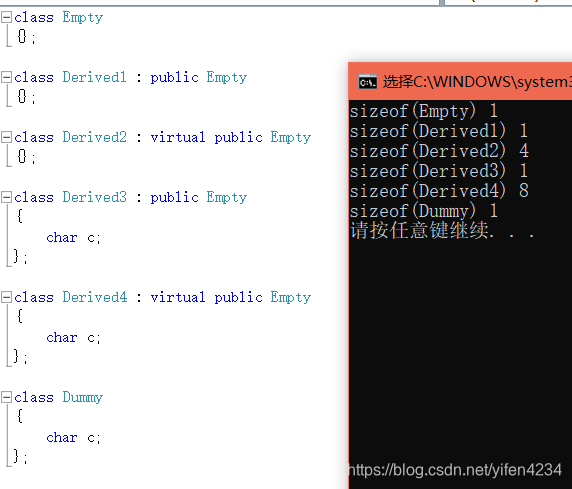
Why is the size of an empty class not zero in C++?
https://www.geeksforgeeks.org/why-is-the-size-of-an-empty-class-not-zero-in-c/
#include<iostream>
using namespace std;
class Empty {};
int main()
{
cout << sizeof(Empty);
return 0;
}
Output:
1
Size of an empty class is not zero. It is 1 byte generally. It is nonzero to ensure that the two different objects will have different addresses. See the following example.
[空类实例化的size是1,是因为要区分不同的对象!]
C++输入字符串
# include<iostream>
using namespace std;
int main()
{
cout<<"Enter Something"<< endl;
int you_name[20];
const int arsize = 20;
cin<<you_name; // 以空格,制表符,换行符来停止
cin.getline(you_name, arsize); // getline将丢弃换行符,用空格‘\0’表示换行
cin.get(you_name, arsize); // get(arg1, arg2)将保留换行符在输入流中,所以下一步要通过cin.get()来读取换行符
cin.get(); //没有参数的get,或者接受一个char参数的get(ch)读取换行符
// cin.get(you_name, size).get() 等于上两句话的结合
}
深拷贝vs浅拷贝
https://www.zhihu.com/question/36370072
说白了,就是类值和类指针行为的区别。
对于含有指针成员的类,直接拷贝可能会出现两个对象的指针成员指向同一个数据区。这时候一般先new个内存,然后复制内容
当然这也得看情况,如果整个类只需要一份这样的数据,就没必要new内存了,直接编译器默认构造函数就行。
总结:一般对于堆上的内存才需要深拷贝
是针对指针的,浅拷贝是只拷贝指针地址,意思是浅拷贝指针都指向同一个内存空间,当原指针地址所指空间被释放,那么浅拷贝的指针全部失效。
深拷贝是先申请一块跟被拷贝数据一样大的内存空间,把数据复制过去。这样拷贝多少次,就有多少个不同的内存空间,干扰不到对方。
结构体
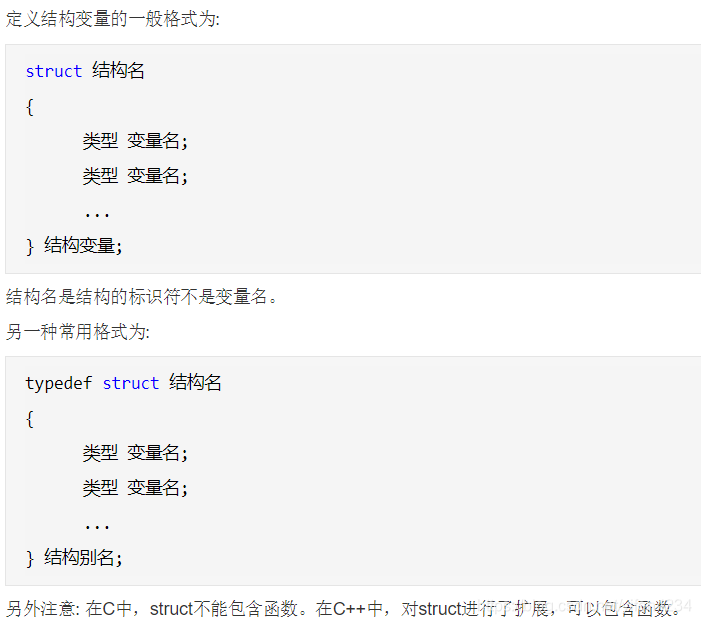
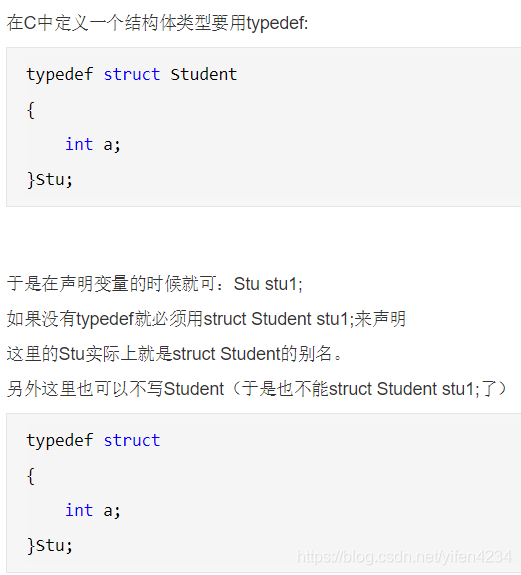
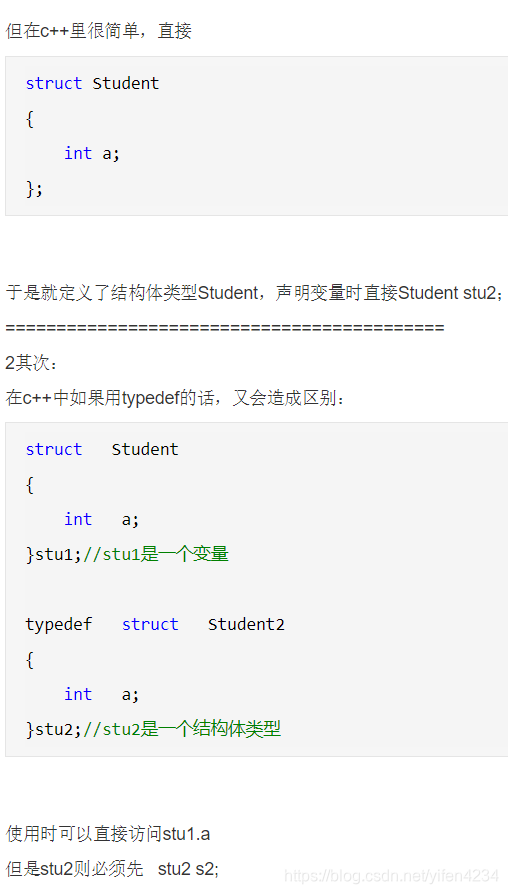
在C语言里面,一定要用typedef【待官方求证】
VS各种配置
说来惭愧,之前都是用codeblocks,没怎么用过vs…
1. Visual Studio控制台程序输出窗口一闪而过的解决方法
其实问题是你执行时按的是F5,而正确的应该是Ctrl+F5,这样窗口就会显示 Press any key to continue…这句话了。也可以看到程序运行的结果了。
因为,F5是Debugging模式,在这个模式下,当程序运行结束后,窗口不会继续保持打开状态。而Ctrl+F5是 Start Without Debugging模式,在这个模式下,就可以看到运行结果了。
如果你按Ctrl+F5仍然是一闪而过的话,那么请按照如下设置:
在工程上右键—>属性—>配置属性—>连接器—>系统—>子系统(在窗口右边)—>下拉框选择控制台(/SUBSYSTEM:CONSOLE)
作者:Paul-Huang
原文:https://blog.youkuaiyun.com/huang1024rui/article/details/77480957
2. stdafx.h预编译头文件
微软公司的预编译头文件叫这个名字,预编译头文件可以缩短程序的编译时间。
c++里的stdafx.h是干什么的? - Kale Woo的回答 - 知乎
https://www.zhihu.com/question/66359961/answer/304539921

VS中的Solution/project 是什么意思?
Solution不仅仅是Project Group,尽管他最大的作用就是这个。Solution是你开发中所需要用到的所有东西的集合和一个管理器,例如项目、文档、测试用例、源代码管理、第三方类库,全都可以整合在Solution里面,非常方便。项目的整合就不说了,拥有依赖关系的项目在同一个Solution里面就可以自动级联编译,而且是增量编译的。单元测试,除了解决项目依赖之外,在Solution里面的时候,关联项目编译的时候单元测试就会自动运行。在调试的时候,Solution里面的项目都会被自动加载到调试器,便于进行源代码调试。Solution可以用文件夹分组项目,也可以存放项目文档。
作者:Ivony
链接:https://www.zhihu.com/question/35946310/answer/65207974
来源:知乎

















 2718
2718

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









