




 本文深入探讨HDFS的工作原理,包括上传下载流程、机架感知策略、NN与2NN的持久化策略,以及NameNode故障处理方法。理解HDFS的网络拓扑、机架感知和故障恢复机制对于大数据处理至关重要。
本文深入探讨HDFS的工作原理,包括上传下载流程、机架感知策略、NN与2NN的持久化策略,以及NameNode故障处理方法。理解HDFS的网络拓扑、机架感知和故障恢复机制对于大数据处理至关重要。
文章目录
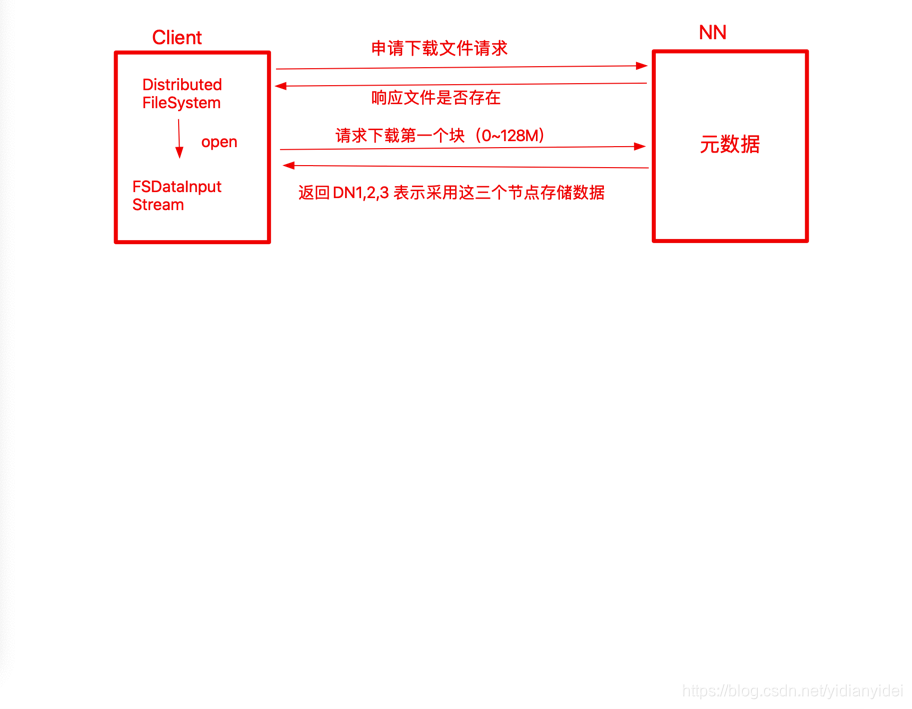
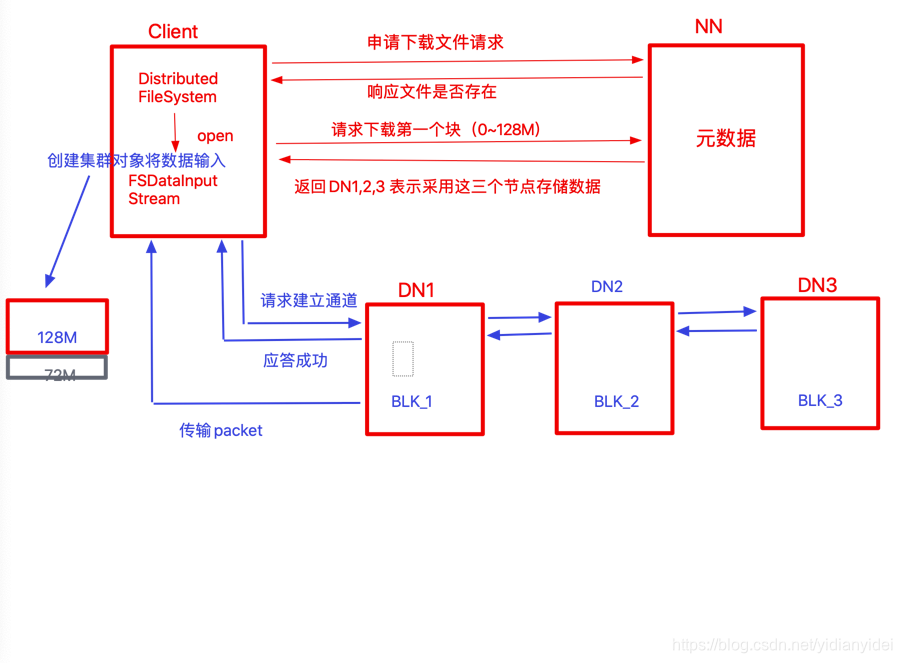
一 HDFS上传图解
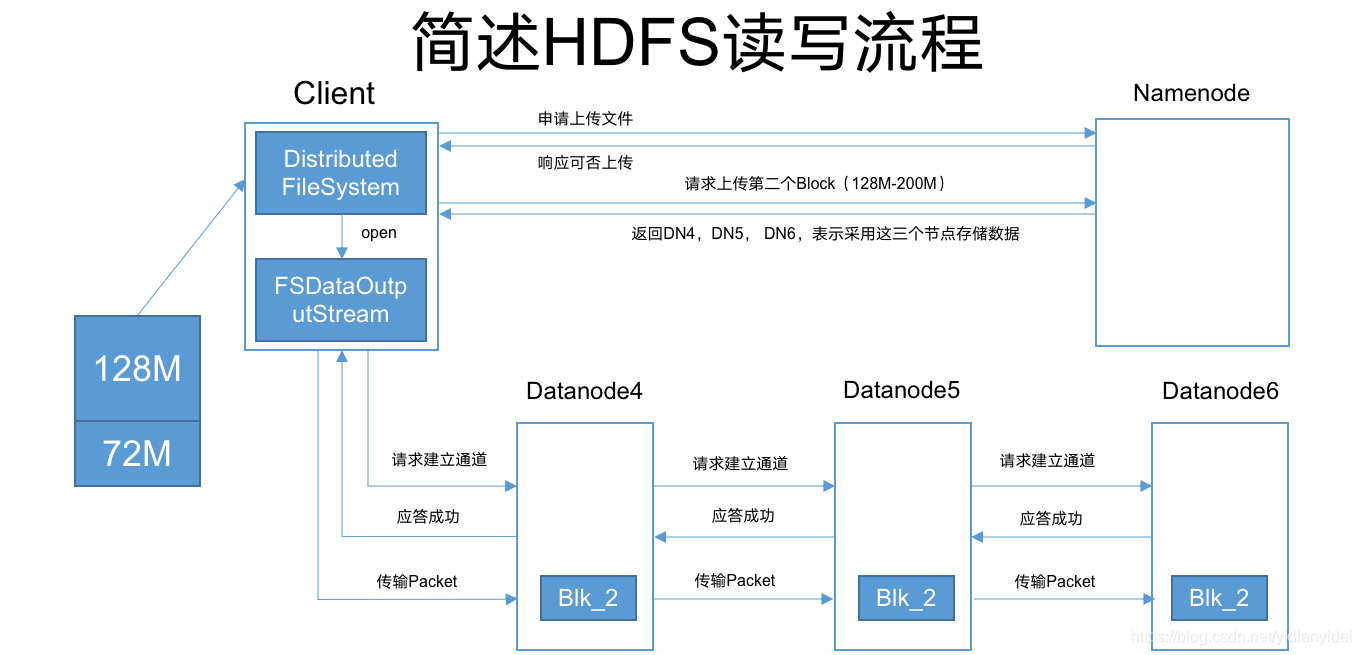
图解
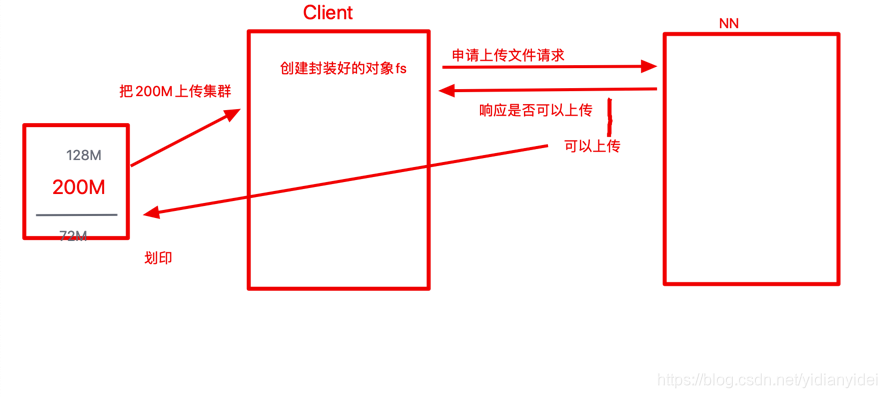
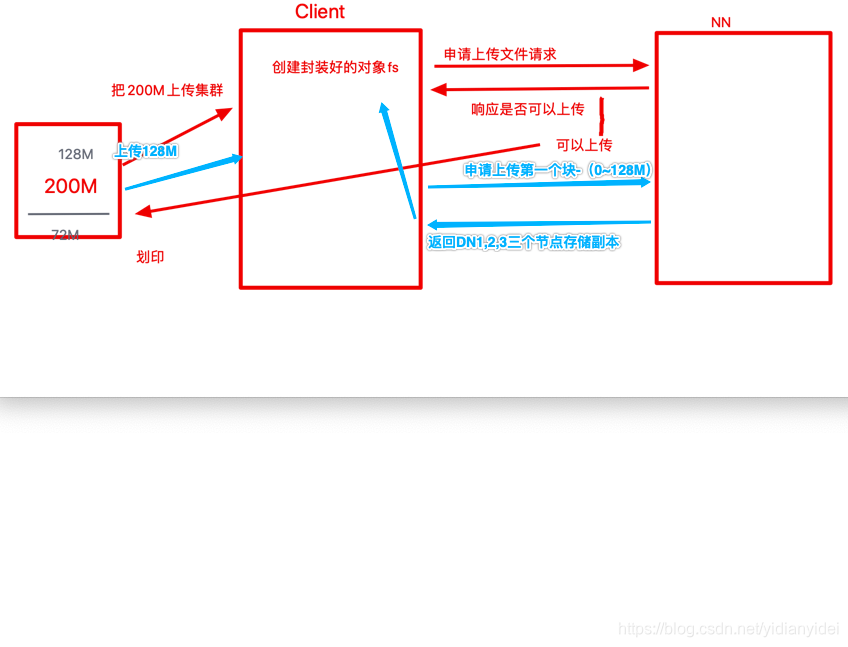
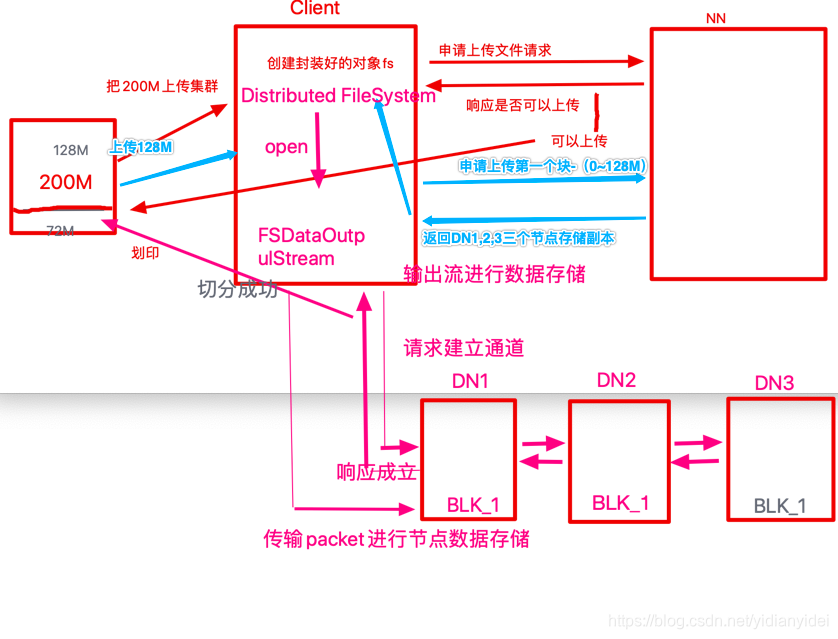
块2 也是如此流程
二 扩展
网络拓扑
只描述他们关系 ,不管他们是什么。
图
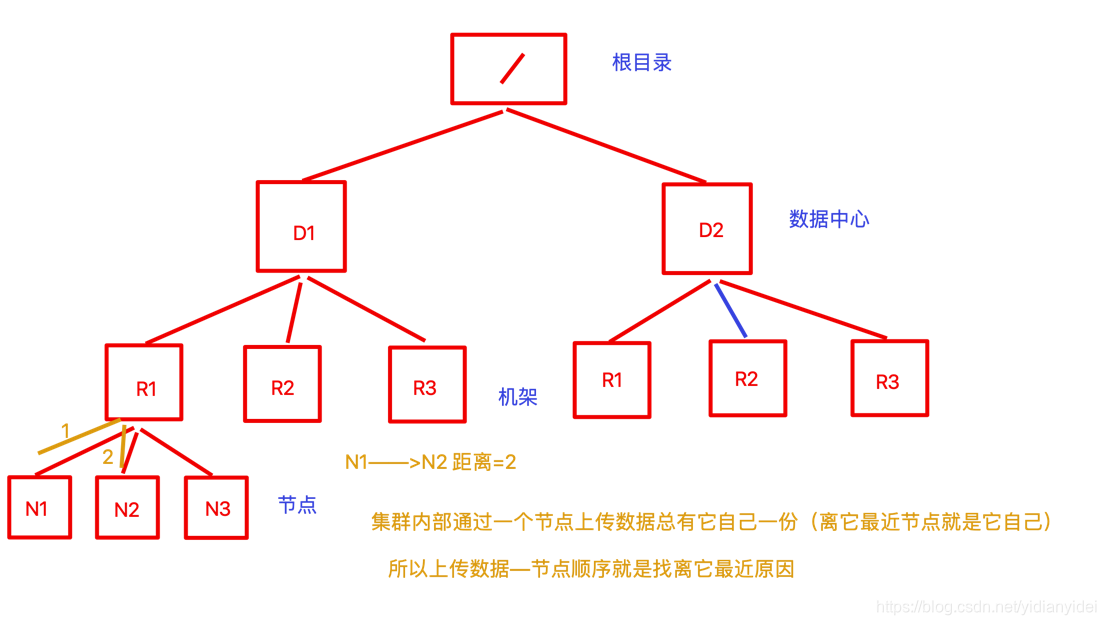
机架感知
(副本选择策略)—副本数是3的情况下 ,第一个副本是localrack ,其它可能是不同机架不同节点,不会跨数据中心
机架感知
(副本选择策略)—副本数是3的情况下 ,第一个副本是localrack ,其它可能是不同机架不同节点,不会跨数据中心
为何建立通道串行?
围绕 IO —>因为性能---->并行的话压力集中在客户端,使得性能变差------>只能串行
挂了?
请求建立通道挂了-----集群fail
传输packet 挂了1节点挂了 传输失败----fail
传输packet 挂了 2 节点挂了 --没事 因为数据已经保存在1 节点上—会根据1节点存储 恢复2节点
三 HDFS下载图解
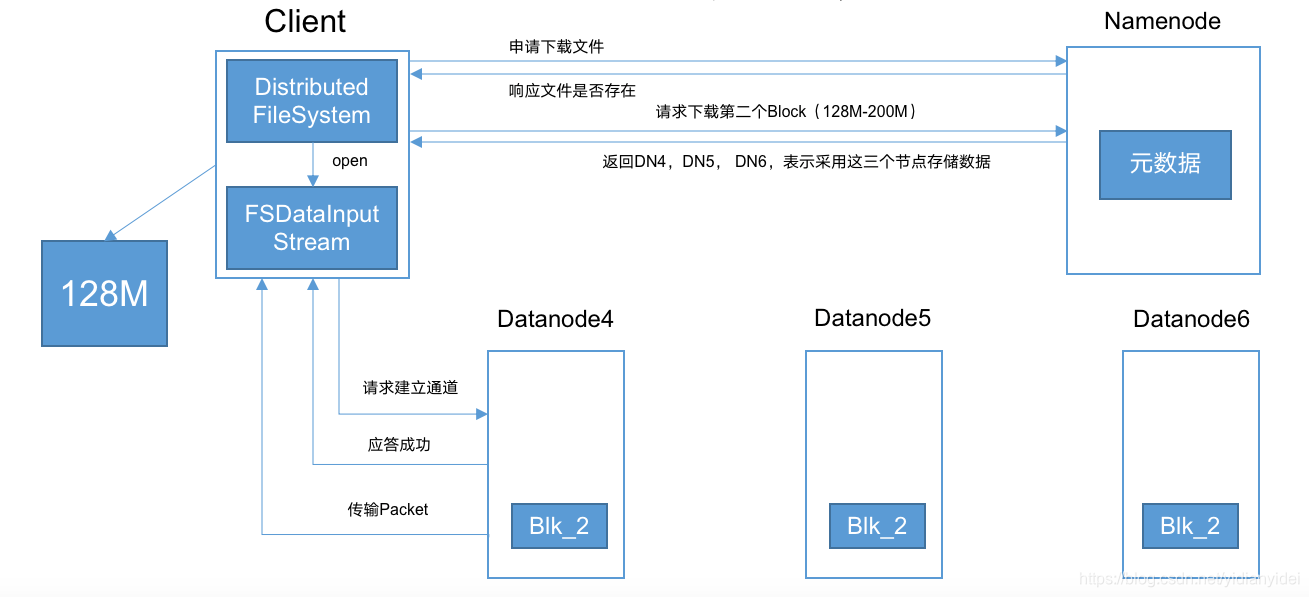
图解
挂了?
如果DN1 挂了会请求DN2-----直至全挂了整个下载过程才失败
四 NN 与2NN 之间关系
持久化策略
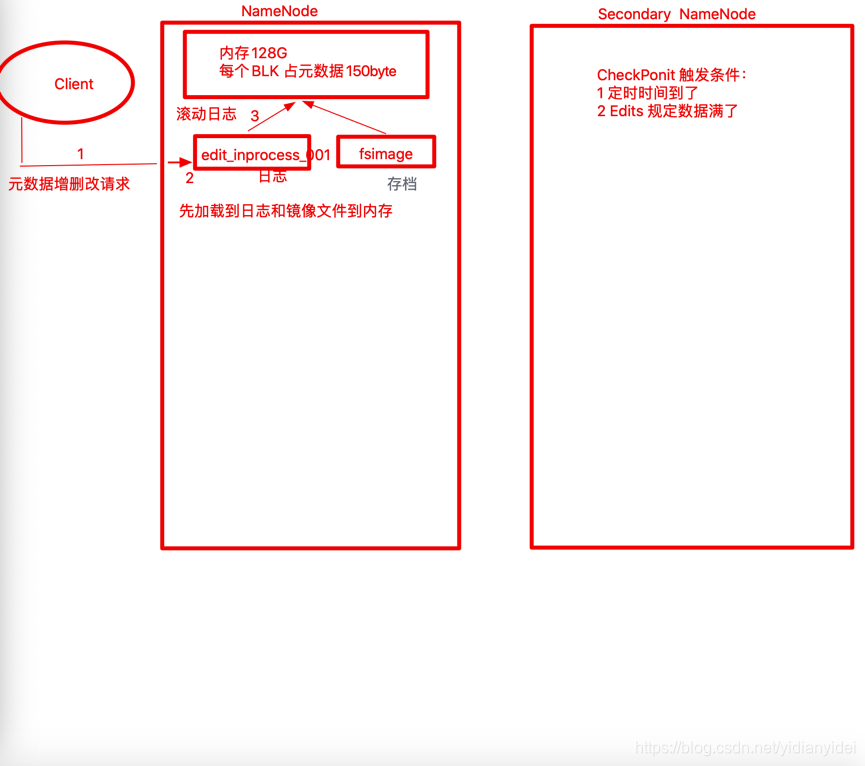
NN 是存在内存中------>断电即没 ------?如何持久化呢
Redis 持久化
64G/128G
RDB
定时把整个内存镜像保存一份—保存慢 读快
AOF
操作一次保存一次------安全性高 读慢 保存快
**Hadoop 持久化
AOF
每写一条,保存一次 (edits.log)—一旦重启 就要把edits.log 全读一遍
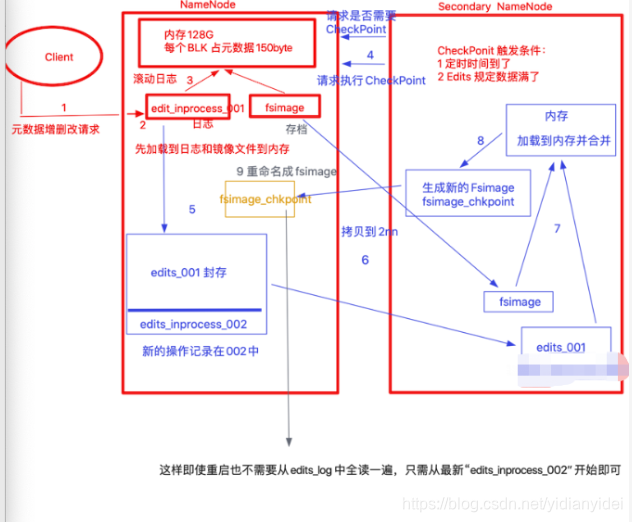
2NN 与NN 持久化策略
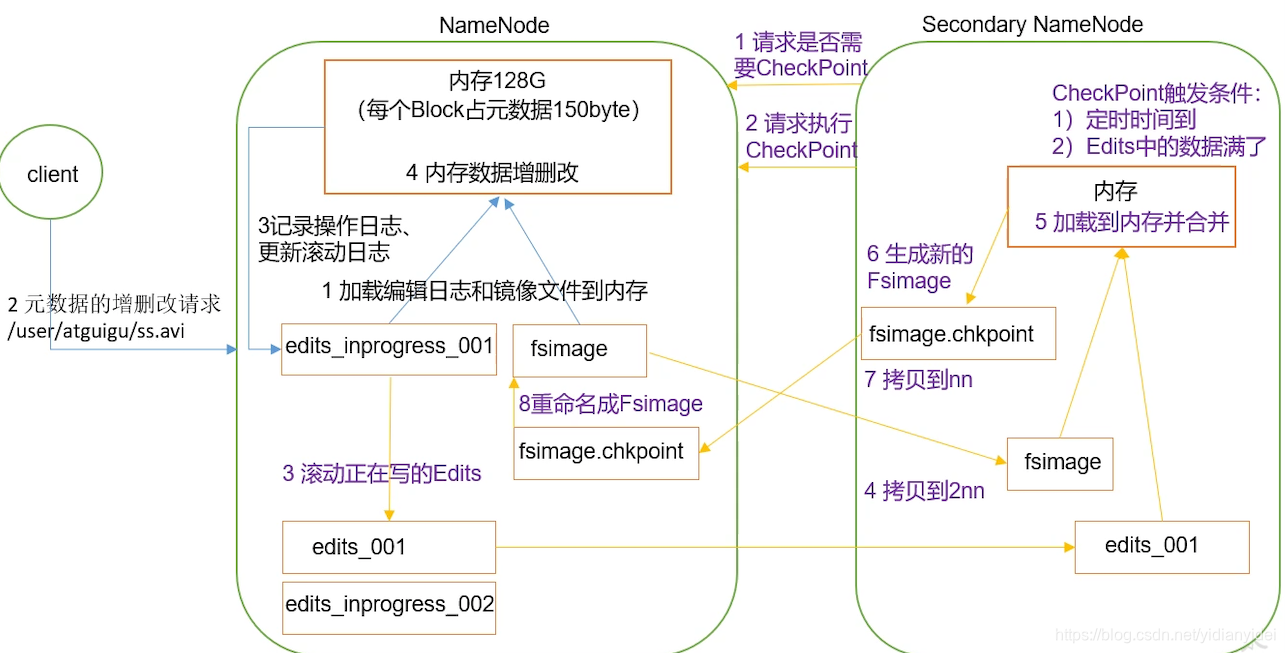
图解
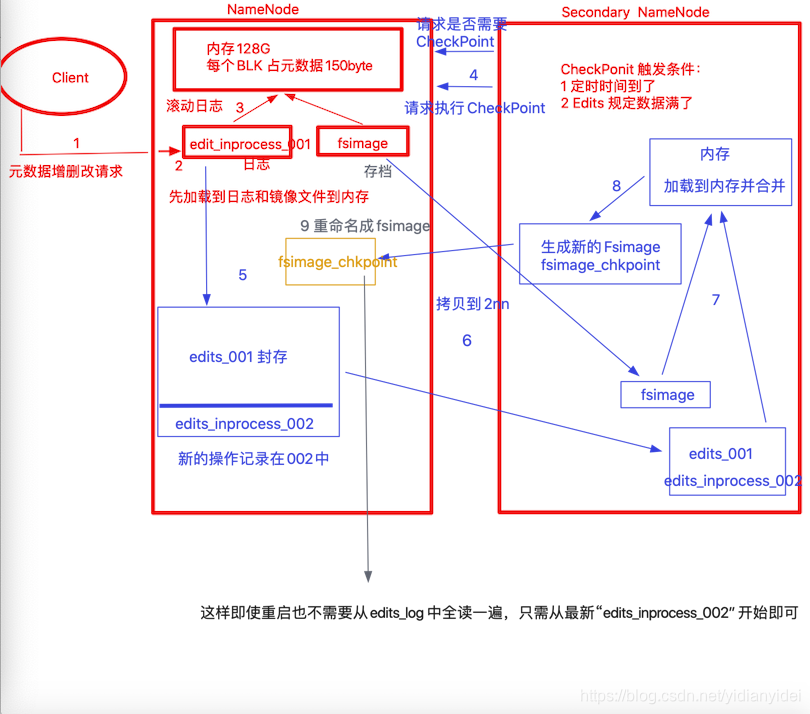
修改一下上面画的有个地方有问题 ,请以下面为主
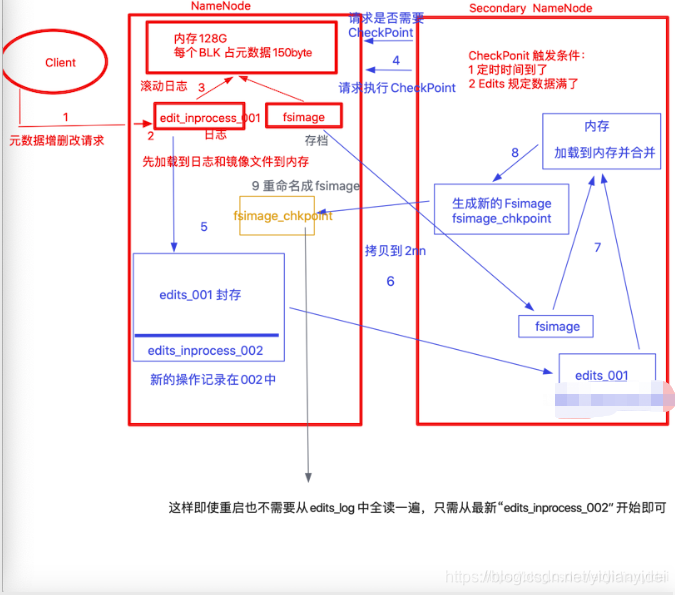
五 补充
1 CheckPoint时间设置
(1)通常情况下,SecondaryNameNode每隔一小时执行一次。
[hdfs-default.xml]
dfs.namenode.checkpoint.period
3600 每隔1小时请求一次
(2)一分钟检查一次操作次数,3当操作次数达到1百万时,SecondaryNameNode执行一次。
dfs.namenode.checkpoint.txns
1000000 当数据存储到100w 条请求
操作动作次数
2 Fsimage和Edits解析
oiv apply the offline fsimage viewer to an fsimage
oev apply the offline edits viewer to an edits file
基本语法:hdfs oiv -p 文件类型 -i镜像文件 -o 转换后文件输出路径

基本语法:hdfs oev -p 文件类型 -i编辑日志 -o 转换后文件输出路径

edits_inprocess_002 :Record 记录操作过程
fsimage:INodeDirectorySection 描述目录结构
INodeSection 记录所有 inode 信息 类型,(所有节点信息 ,格式,文件由哪些块组成)
3 NameNode故障处理
NameNode故障后,可以采用如下两种方法恢复数据。
方法一
将SecondaryNameNode中数据拷贝到NameNode存储数据的目录;
- kill -9 NameNode进程
- 删除NameNode存储的数据(/opt/module/hadoop-2.7.2/data/tmp/dfs/name)
[a@hadoop102 hadoop-2.7.2]$ rm -rf /opt/module/hadoop-2.7.2/data/tmp/dfs/name/* - 拷贝SecondaryNameNode中数据到原NameNode存储数据目录
[a@hadoop102 dfs]$ scp -r a@hadoop104:/opt/module/hadoop-2.7.2/data/tmp/dfs/namesecondary/* ./name/ - 重新启动NameNode
[a@hadoop102 hadoop-2.7.2]$ sbin/hadoop-daemon.sh start namenode
方法二:
使用-importCheckpoint选项启动NameNode守护进程,从而将SecondaryNameNode中数据拷贝到NameNode目录中。
- 修改hdfs-site.xml中的
dfs.namenode.checkpoint.period
120
[a@hadoop102 namesecondary]$ rm -rf in_use.lock
[a@hadoop102 dfs]$ pwd
/opt/module/hadoop-2.7.2/data/tmp/dfs
[a@hadoop102 dfs]$ ls
data name namesecondary
5. 导入检查点数据(等待一会ctrl+c结束掉)
[a@hadoop102 hadoop-2.7.2]$ bin/hdfs namenode -importCheckpoint
6. 启动NameNode
[a@hadoop102 hadoop-2.7.2]$ sbin/hadoop-daemon.sh start namenode
老的hadoop 版本不支持HA (隐患:2NN比NN 少了----edit_inprocess_002)
4 集群安全模式


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









