







0、目标:
将初学者快速带入es,快速掌握一些相关的概念
1、什么是ES?
ElasticSearch 中文直译为可扩展的搜索,那ES哪些方面提现了可扩展性和搜索?
什么是可扩展
要分析es的可扩展我们需要分析下es的一些原理。关于es,我们可能常能听说到节点、分片这些词,
- 什么是节点?
对于节点,可以理解为一个es服务进程、我们的生产环境es往往是由一个集群构成、一个集群往往是由多个节点组成,通常我们一台服务器会部署一个节点(当然也可以部署多个),一个节点也会部署多个分片。 - 什么是分片?
分片可以理解为一个可以独立运行的搜索服务,它包含整个es机器的部分数据。
我们在使用mysql做数据存储的时候,一般情况下都是写少读多。所以一般是一个主库,多个从库,增加从库可以缓解读的压力。如果业务不断的增长,写的压力也不断上升,一个主库已经无法承受了呢?对于这种需要缓解写的压力的情况我们只能是通过分库分表来实现。比如说用户表,我们通过一定的规则将用户信息写进不同的库中,从而实现扩容的效果,但是这样的扩容带来了一些新的问题。一个是不方便做分页查询,另外一个是业务代码需要配合改动。那么es是如果解决扩容方便的呢?
es可以设置多个主分片,这个主分片就是我们mysql的主库,是写入数据的地方。如果我们创建索引的时候,创建9个主分片,那么最终数据会均匀分布到9个主分片上。相比mysql的数据只能往一个主库写入,这样的分片模式大大扩大了数据的存储能力。
至于es的查询能力的扩展性,就类似mysql的增加从库,es也是通过增加备份分片,保存对应主分片的数据,一个主分片可以有多个备份分片。因为备份分片保存的是主分片的数据,所以在查询的时候,就可以将查询的压力分给备份分片。
不足:es的主分片在创建索引的时候指定,后期想改变也是比较麻烦的,除非重新索引所有数据。那为啥不能新增主分片呢?
原因是这样的,我们我们在插入数据的时候有个算法,类似于hashmap的算法,对key做hash之后能定位该数据需要保存到那个主分片,一旦分片数量变化,数据的存储是应该同步变化的。所以最终导致主分片的数量不能轻易调整。
什么是搜索
es的主要卖点是方便搜索,虽然在mysql中一样可以搜索,但是mysql主要是做精准查询,在es中提供了一种倒排索引来解决文本查询。比如有个店铺描述字段,我们希望输入关键字能搜索到店铺信息。在mysql中我们可能是用like来解决,但是like有个比较致命的缺陷,就是like是最左匹配的原则。也就是搜索的关键字如果不符合最左匹配,则会引起全文扫描,速度极慢。es引入的倒排索引很好的解决这块问题。
大致就是先对该字段的所有内容进行分词,比如我爱吃苹果,可以分为“我”“爱”“吃”“苹果” 四个关键字,每个文档都有一个唯一id与之对应,凡是出现以上关键字的文档都关联到该关键词后面,如下图(更多关于倒排索引的可以参考这篇文章)
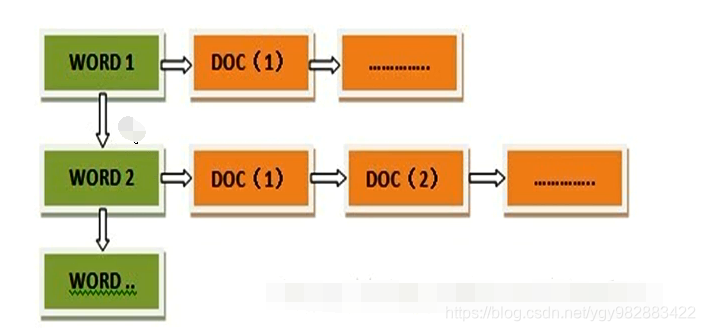
我要是查苹果的时候,希望找到包含所有苹果相关的文档返回给用户。
当然es的搜索不仅仅提现在上面的描述,还有很多其他方面,比如地理位置的搜索等。
2、ES原理
前面的介绍可能还是不够深入全面,下面就一些其他方面再对es进一步介绍
启动过程
当ElasticSearch的节点启动后,它会利用多播(multicast)(或者单播,如果用户更改了配置)寻找集群中的其它节点,并与之建立连接。这个过程如下图所示
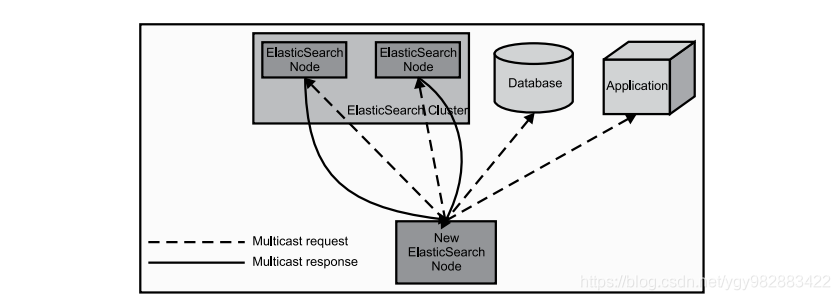
在集群中,会有一个节点被选举成主节点(master node),这个节点负责管理集群的状态,当群集的拓扑结构改变时把索引分片分派到相应的节点上。
需要注意的是,从用户的角度来看,主节点在ElasticSearch中并没有占据着重要的地位,这与其它的系统(比如数据库系统)是不同的。实际上用户并不需要知道哪个节点是主节点;所有的操作需求可以分发到任意的节点,ElasticSearch内部会完成这些让用户感到不明觉历的工作。在必要的情况下,任何节点都可以并发地把查询子句分发到其它的节点,然后合并各个节点返回的查询结果。最后返回给用户一个完整的数据集。所有的这些工作都不需要经过主节点转发(节点之间通过P2P(点对点)的方式通信)。
探测失效节点
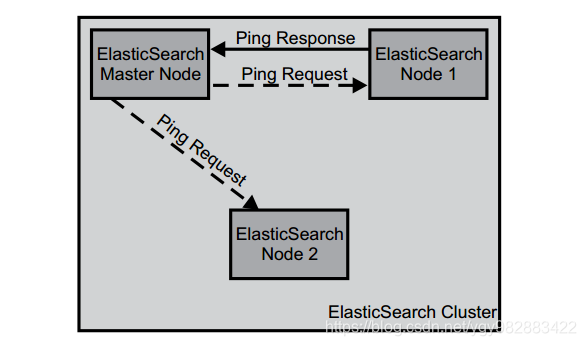
在正常工作时,主节点会监控所有的节点,查看各个节点是否工作正常。如果在指定的时间里面,节点无法访问,该节点就被视为出故障了,接下来错误处理程序就会启动。集群需要重新均衡——由于该节点出现故障,分配到该节点的索引分片丢失。其它节点上相应的分片就会把工作接管过来。换句话说,对于每个丢失的主分片,新的主分片将从剩余的分片副本(Replica)中选举出来。重新安置新的分片和副本的这个过程可以通过配置来满足用户需求。
由于只是展示ElasticSearch的工作原理,我们就以下图三个节点的集群为例。集群中有一个主节点和两个数据节点。主节点向其它的节点发送Ping命令然后等待回应。如果没有得到回应(实际上可能得不到回复的Ping命令个数取决于用户配置),该节点就会被移出集群。丢弃的节点上的主分片由存活节点上的副本分片替代。
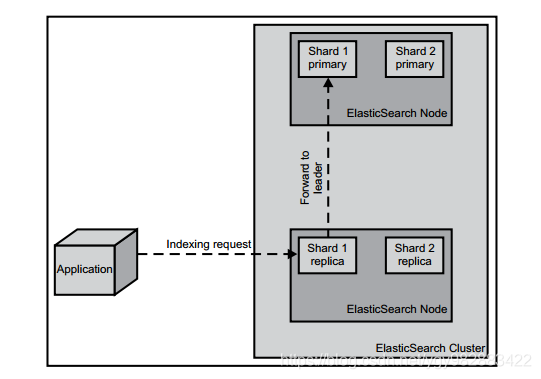
索引数据
ElasticSearch提供了4种索引数据的办法。最简单的是使用索引API,索引API。通过它可以将文档添加到指定的索引中去。比如,通过curl工具(访问http://curl.haxx.se/ ),我们可以通过如下的命令创建一个新的文档:
curl -XPUT http://localhost:9200/blog/article/1 -d '{
"title": "New version of Elastic Search released!", "content": "...",
"tags": ["announce", "elasticsearch", "release"]
}'
其他方法暂不介绍
有一点需要注意,索引数据的操作只会发生在主分片(primary shard)上,而不会发生在分片副本(Replica) 上。如果索引数据的请求发送到的节点没有合适的分片或者分片是副本,那么请求会被转发到含有主分片的节点。
数据查询
查询API在ElasticSearch中有着很大的比重。通过使用Query DSL(基于JSON,用来构建复杂查询的语言) ,我们能够:
- 使用各种类型的查询方式,包括:简单的关键词查询(term query) ,短语查询(phrase)、区间查询(range)、布尔查询(boolean)、模糊查询(fuzzy)、跨度查询(span)、通配符查询(wildcard)、地理位置查询(spatial)等其它类型的查询方式。
通过组合简单查询构建出复杂的查询。 - 过滤文档,去除不符合标准的文档而且不影响打分排序。
- 查找给定文档的相似文档。
- 查找给定短语的搜索建议和查询短语修正。
- 通过faceting构建动态的导航和数据统计
- 使用prospective search而且找到匹配写定文档的查询语句。( 关于prospective search,似乎是一种推送方式。即把用户的查询语句存储到索引中,如果新的文档添加到索引中,就把文档关联到匹配的查询语句中。这种查询适合于新闻、博客等会定时更新的应用场景 )
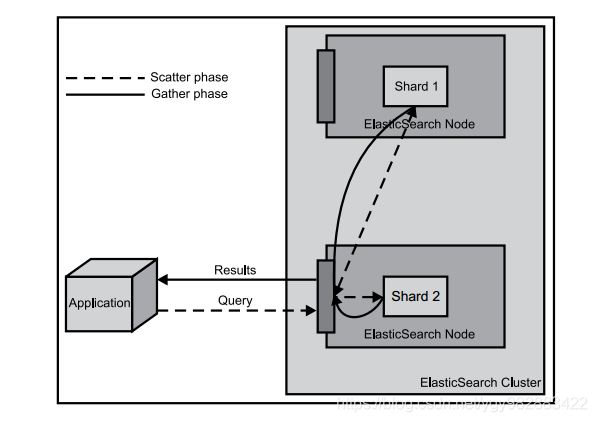
关于数据查询,其核心点在于查询过程不是一个简单、单一的流程。通常这个过程分为两个阶段:查询分发阶段和结果汇总阶段。在查询分发阶段,会从各个分片中查询数据;在结果汇总阶段,会把从各个分片上查询到的结果进行合并、排序等其它处理过程,然后返回给用户。
索引参数设置
前面已经提到ElasticSearch索引参数的自动化配置和文档结构及域类型的自动识别。当然,ElasticSearch也允许用户自行修改默认配置。用户可以自行配置很多参数,比如通过mapping配置索引中的文档结构,设置分片(shard)和副本(replica)的的个数,设置文本分析组件……
接下来的系列文章还会就es的其他使用细节进一步介绍。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









