




 文章详细介绍了网络I/O模型,包括阻塞式、非阻塞式、I/O复用(select、poll、epoll)以及零拷贝技术,讨论了传统I/O操作的问题和优化方法。此外,还提到了序列化的概念,比较了JDK序列化与其他序列化库如FastJson、Protobuf的优缺点。最后,文章探讨了通讯协议的选择,如SpringCloud和Dubbo在RPC通信中的应用,以及如何通过TCP参数优化网络通信,特别提到了Netty的相关配置选项。
文章详细介绍了网络I/O模型,包括阻塞式、非阻塞式、I/O复用(select、poll、epoll)以及零拷贝技术,讨论了传统I/O操作的问题和优化方法。此外,还提到了序列化的概念,比较了JDK序列化与其他序列化库如FastJson、Protobuf的优缺点。最后,文章探讨了通讯协议的选择,如SpringCloud和Dubbo在RPC通信中的应用,以及如何通过TCP参数优化网络通信,特别提到了Netty的相关配置选项。
1-IO模型
1.1-网络IO 模型
《UNIX网络编程》一书将这五种I/O模型分为阻塞式I/O、非阻塞式I/O、I/O复用、信号驱动式I/O和异步I/O。
1.1.1-最简单的TCP数据传输
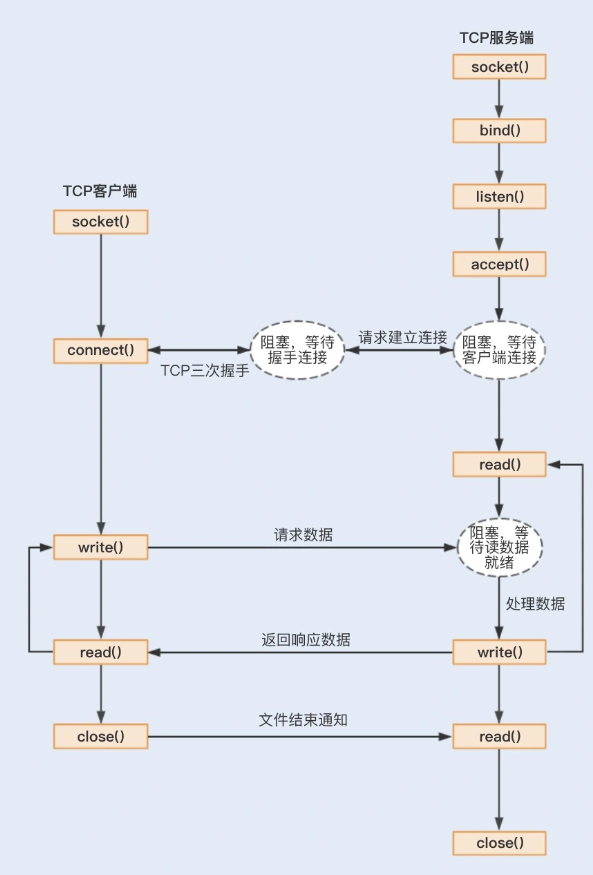
1.1.2-阻塞式I/O
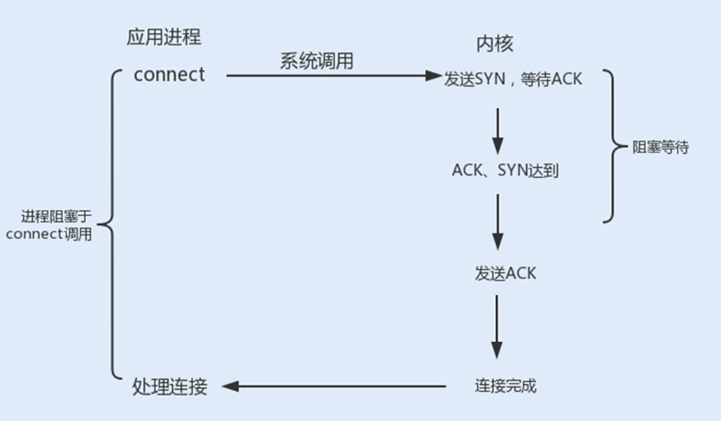
connect阻塞:当客户端发起TCP连接请求,通过系统调用connect函数,TCP连接的建立需要完成三次握手过程,客户端需要等待服务端发送回来的ACK以及SYN信号,同样服务端也需要阻塞等待客户端确认连接的ACK信号,这就意味着TCP的每个connect都会阻塞等待,直到确认连接。
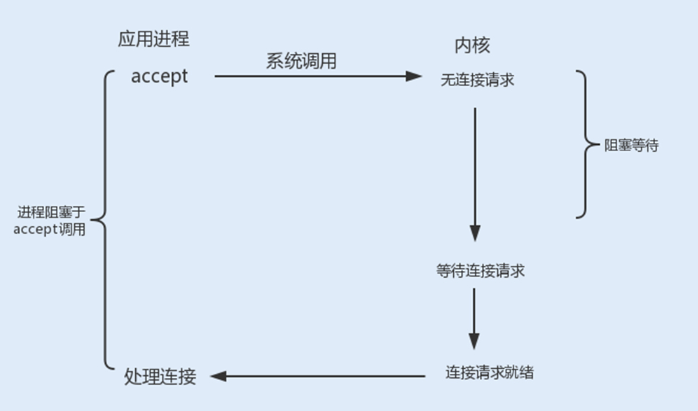
accept阻塞:一个阻塞的socket通信的服务端接收外来连接,会调用accept函数,如果没有新的连接到达,调用进程将被挂起,进入阻塞状态。
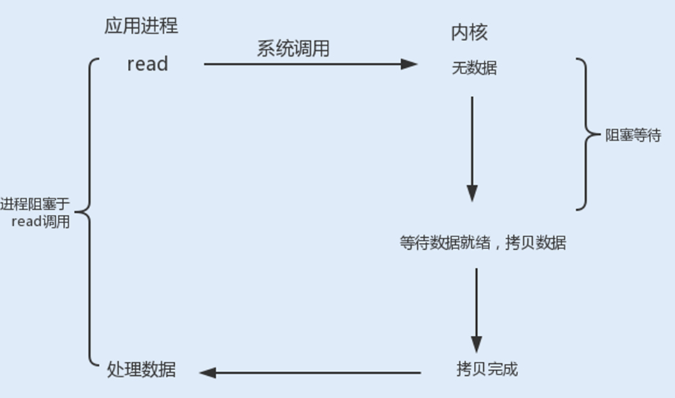
read、write阻塞:当一个socket连接创建成功之后,服务端用fork函数创建一个子进程, 调用read函数等待客户端的数据写入,如果没有数据写入,调用子进程将被挂起,进入阻塞状态。
1.1.3-非阻塞式I/O
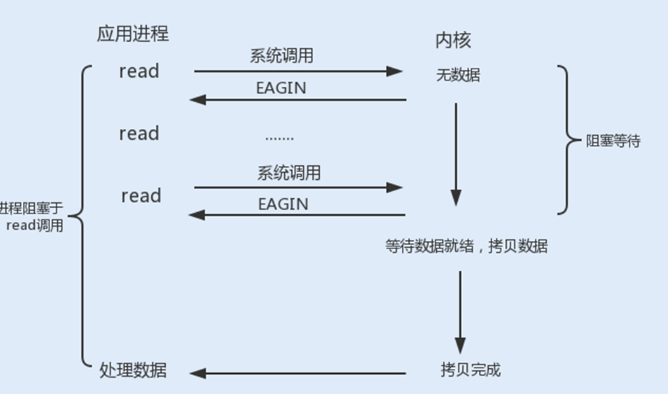
使用fcntl可以把以上三种操作都设置为非阻塞操作。如果没有数据返回,就会直接返回一个EWOULDBLOCK或EAGAIN错误,此时进程就不会一直被阻塞。但是我们需要设置一个线程对该操作进行轮询检查,这也是最传统的非阻塞I/O模型。
1.1.4-I/O复用
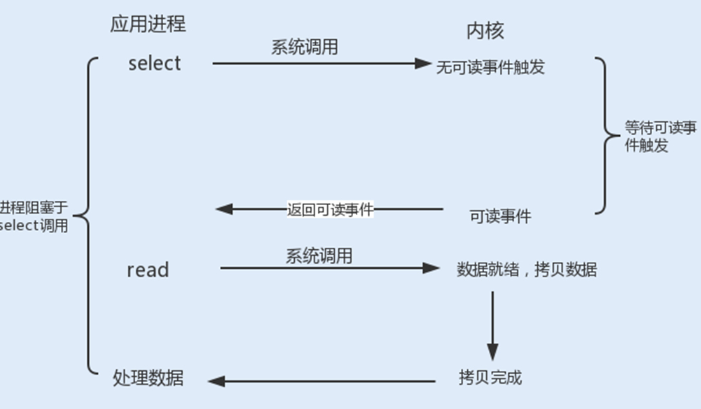
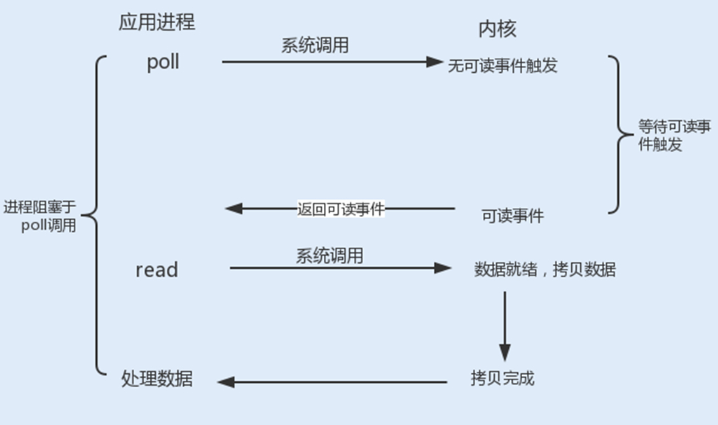
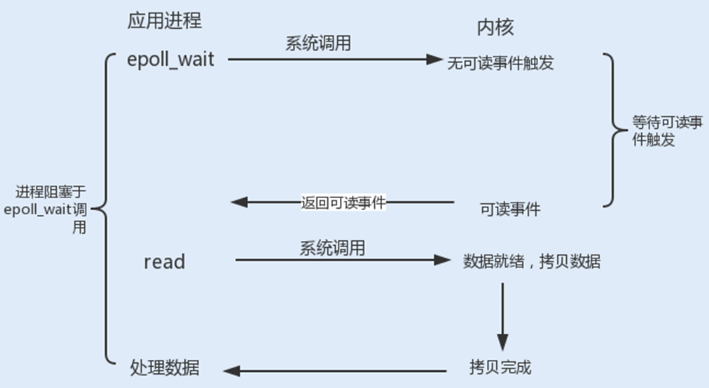
Linux提供了I/O复用函数select/poll/epoll,进程将一个或多个读操作通过系统调用函数,阻塞在函数操作上。
select | poll | epoll |
|
|
|
在超时时间内,监听用户感兴趣的文件描述符上的可读可写和异常事件的发生。 | poll() 的机制与 select() 类似,二者在本质上差别不大。poll() 管理多个描述符也是通过轮询,根据描述符的状态进行处理,但 poll() 没有最大文件描述符数量的限制。poll() 和 select() 存在一个相同的缺点,那就是包含大量文件描述符的数组被整体复制到用户态和内核的地址空间之间,而无论这些文件描述符是否就绪,他们的开销都会随着文件描述符数量的增加而线性增大。 | epoll使用事件驱动的方式代替轮询扫描fd。epoll事先通过epoll_ctl()来注册一个文件描述符,将文件描述符存放到内核的一个事件表中,这个事件表是基于红黑树实现的,所以在大量I/O请求的场景下,插入和删除的性能比select/poll的数组fd_set要好,因此epoll的性能更胜一筹,而且不会受到fd数量的限制。 |
由于信号驱动式I/O对TCP通信的不支持,以及异步I/O在Linux操作系统内核中的应用还不大成熟,大部分框架都还是基于I/O复用模型实现的网络通信。
1.2-零拷贝
零拷贝是一种避免多次内存复制的技术,用来优化读写I/O操作。
在网络编程中,通常由read、write来完成一次I/O读写操作。每一次I/O读写操作都需要完成四次内存拷贝,路径是I/O设备->内核空间->用户空间->内核空间->其它I/O设备。
Linux内核中的mmap函数可以代替read、write的I/O读写操作,实现用户空间和内核空间共享一个缓存数据。mmap将用户空间的一块地址和内核空间的一块地址同时映射到相同的一块物理内存地址,不管是用户空间还是内核空间都是虚拟地址,最终要通过地址映射映射到物理内存地址。这种方式避免了内核空间与用户空间的数据交换。I/O复用中的epoll函数中就是使用了mmap减少了内存拷贝。
1.2-传统IO问题
I/O操作分为磁盘I/O操作和网络I/O操作。前者是从磁盘中读取数据源输入到内存中,之后将读取的信息持久化输出在物理磁盘上;后者是从网络中读取信息输入到内存,最终将信息输出到网络中。
1.2.1-多次内存复制
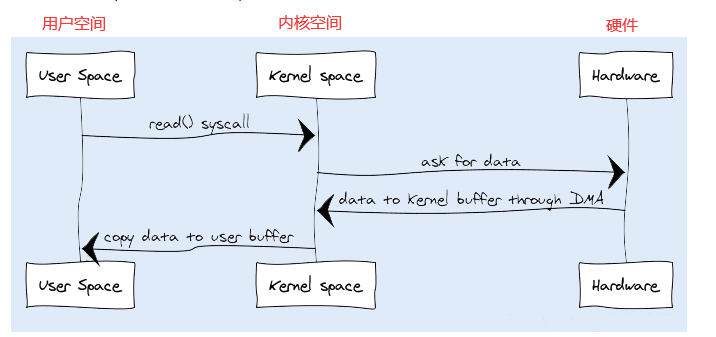
JVM会发出read()系统调用,并通过read系统调用向内核发起读请求;
内核向硬件发送读指令,并等待读就绪;
内核把将要读取的数据复制到指向的内核缓存中;
操作系统内核将数据复制到用户空间缓冲区,然后read系统调用返回
在这个过程中,数据先从外部设备复制到内核空间,再从内核空间复制到用户空间,这就发生了两次内存复制操作。这种操作会导致不必要的数据拷贝和上下文切换,从而降低I/O的性能。
1.2.2-阻塞
传统的IO和socket中,InputStream的read()是一个while循环操作,它会一直等待数据读取,直到数据就绪才会返回。这就意味着如果没有数据就绪,这个读取操作将会一直被挂起,用户线程将会处于阻塞状态。
1.3-优化IO操作
1.3.1-使用缓冲区优化读写流操作
InputStream和OutputStream,这种基于流的实现以字节为单位处理数据。传统IO后面加入了BufferedInputStream也有所改善。
NIO是基于块(Block)的,它以块为基本单位处理数据,组件缓冲区(Buffer)和通道(Channel)。
1.3.2-使用DirectBuffer减少内存复制
普通的Buffer分配的是JVM堆内存,而DirectBuffer是直接分配物理内存。DirectBuffer则是直接将步骤简化为从内核空间复制到外部设备,减少了数据拷贝。
1.3.3-避免阻塞
2-序列化
JDK提供的两个输入、输出流对象ObjectInputStream和ObjectOutputStream,它们只能对实现了Serializable接口的类的对象进行序列化和反序列化。
具体实现序列化的是writeObject和readObject,通常这两个方法是默认的,当然我们也可以在实现Serializable接口的类中对其进行重写,定制一套属于自己的序列化与反序列化机制。
另外,Java序列化的类中还定义了两个重写方法:writeReplace()和readResolve(),前者是用来在序列化之前替换序列化对象的,后者是用来在反序列化之后对返回对象进行处理的。
JDK序列化缺点:无法跨语言,安全性低,性能差。
最近几年比较流行的FastJson、Kryo、Protobuf、Hessian等。
一般情况下FastJson完全够用,极端要求性能情况下,使用Protobuf序列化。
3-通讯协议
3.1-SpringCloud和Dubbo怎么选
很多微服务框架中的服务通信是基于RPC通信实现的,在没有进行组件扩展的前提下,SpringCloud是基于Feign组件实现的RPC通信(基于Http+Json序列化实现),Dubbo是基于SPI扩展了很多RPC通信框架,包括RMI、Dubbo、Hessian等RPC通信框架(默认是Dubbo+Hessian序列化)。不同的业务场景下,RPC通信的选择和优化标准也不同。
如果业务场景是:瞬时高峰、请求量大和传入、传出参数数据包较小,选择Dubbo;
SpringCloud是基于Http通信协议(短连接)和Json序列化实现的,在高并发场景下并没有优势,一般的场景可以选择SpringCloud。
3.2-高效的通信协议
为了保证数据传输的可靠性,通常情况下我们会采用TCP协议。
使用单一长连接
优化Socket通信(比如netty)
量身定做报文格式
编码、解码
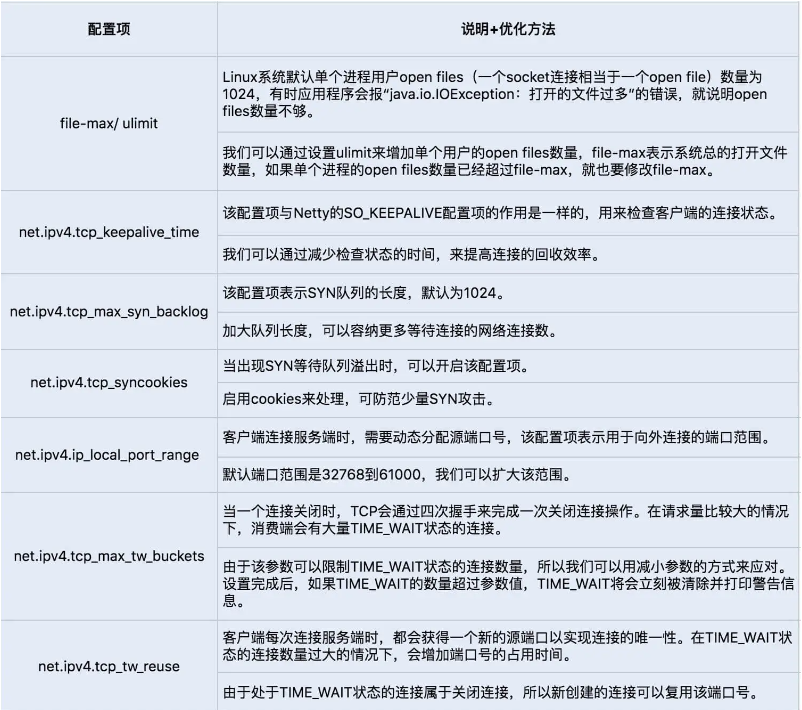
调整Linux的TCP参数设置选项
自定义协议,参考https://blog.youkuaiyun.com/ycmy2017/article/details/128915172


netty相关参数
针对套接字编程提供的一些TCP参数配置项,提高网络吞吐量,Netty可以基于ChannelOption来设置这些参数。
TCP_NODELAY:TCP_NODELAY选项是用来控制是否开启Nagle算法。Nagle算法通过缓存的方式将小的数据包组成一个大的数据包,从而避免大量的小数据包发送阻塞网络,提高网络传输的效率。我们可以关闭该算法,优化对于时延敏感的应用场景。
SO_RCVBUF和SO_SNDBUF:可以根据场景调整套接字发送缓冲区和接收缓冲区的大小。
SO_BACKLOG:backlog参数指定了客户端连接请求缓冲队列的大小。服务端处理客户端连接请求是按顺序处理的,所以同一时间只能处理一个客户端连接,当有多个客户端进来的时候,服务端就会将不能处理的客户端连接请求放在队列中等待处理。
SO_KEEPALIVE:当设置该选项以后,连接会检查长时间没有发送数据的客户端的连接状态,检测到客户端断开连接后,服务端将回收该连接。我们可以将该时间设置得短一些,来提高回收连接的效率。

















 3266
3266

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









