



今天我们来点不一样的,以下有三段代码,大家觉得哪一段取数要更快一些?可以投票哈
【方法一】:where条件限制不等于
" 方法一(where限制不等于) SELECT * INTO TABLE @DATA(lt_bkpf1) FROM bkpf WHERE bukrs = '1710' AND bktxt <> ''. |
【方法二】:先取数再剔除
" 方法二(先取再剔除) SELECT * INTO TABLE @DATA(lt_bkpf2) FROM bkpf WHERE bukrs = '1710'. DELETE lt_bkpf2 WHERE bktxt = ''. |
【方法三】:where条件限制长度
" 第三种(where不等于改成限制长度) SELECT * FROM bkpf WHERE bukrs = '1710' AND length( bktxt ) > 1 INTO TABLE @DATA(lt_bkpf3). |
大家可以尝试下觉得哪种方式更好一些
我在HANAS4 1909版本下测试结果如下,可能不同环境版本有差异,大家可以测试看看:
TYPES: BEGIN OF ty_compare, itmno TYPE i, way1 TYPE i, way2 TYPE i, way3 TYPE i, END OF ty_compare. DATA: lt_compare TYPE STANDARD TABLE OF ty_compare, ls_compare TYPE ty_compare. DATA: lv_begin TYPE i, lv_end TYPE i, lv_duration TYPE i. DATA: lv_lines TYPE i. DO 10 TIMES. CLEAR: ls_compare. ls_compare-itmno = sy-index. " 第一种(where不等于) GET RUN TIME FIELD lv_begin. SELECT * INTO TABLE @DATA(lt_bkpf1) FROM bkpf WHERE bukrs = '1710' AND bktxt <> ''. GET RUN TIME FIELD lv_end. ls_compare-way1 = lv_end - lv_begin. " 第二种(先取再剔除) GET RUN TIME FIELD lv_begin. SELECT * INTO TABLE @DATA(lt_bkpf2) FROM bkpf WHERE bukrs = '1710'. DELETE lt_bkpf2 WHERE bktxt = ''. GET RUN TIME FIELD lv_end. ls_compare-way2 = lv_end - lv_begin. " 第三种(where不等于改成有长度) GET RUN TIME FIELD lv_begin. SELECT * FROM bkpf WHERE bukrs = '1710' AND length( bktxt ) > 1 INTO TABLE @DATA(lt_bkpf3). GET RUN TIME FIELD lv_end. ls_compare-way3 = lv_end - lv_begin. APPEND ls_compare TO lt_compare. ENDDO. DATA(lo_alv) = zcl_falv=>create( CHANGING ct_table = lt_compare ). LOOP AT lo_alv->fcat ASSIGNING FIELD-SYMBOL(<fs_cat>). CASE <fs_cat>-fieldname. WHEN 'ITMNO'. <fs_cat>-coltext = '行号'. WHEN 'WAY1'. <fs_cat>-coltext = 'where条件直接限制不为空'. WHEN 'WAY2'. <fs_cat>-coltext = '先取数,然后内表剔除'. WHEN 'WAY3'. <fs_cat>-coltext = 'where条件限制有内容,长度大于1'. ENDCASE. ENDLOOP. lo_alv->display( ). |
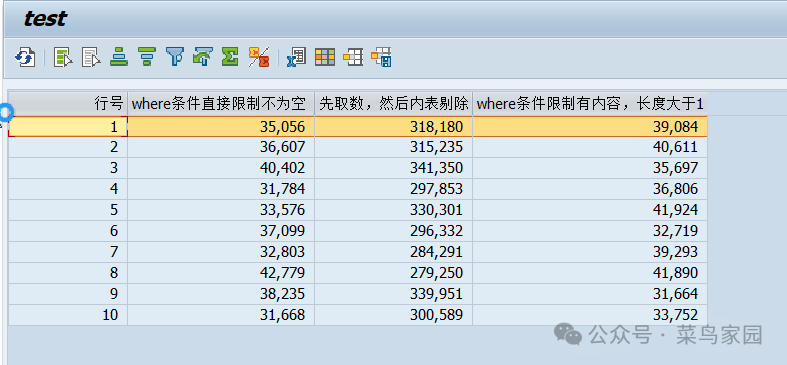
通过以上想说明的是,程序优化有些操作不是一成不变的,我们需要根据实际情况决定优化方向,不要一味的什么不能怎么做,什么应该怎么做。多思考,多测试,才能找到合适的方法。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









