




文章目录
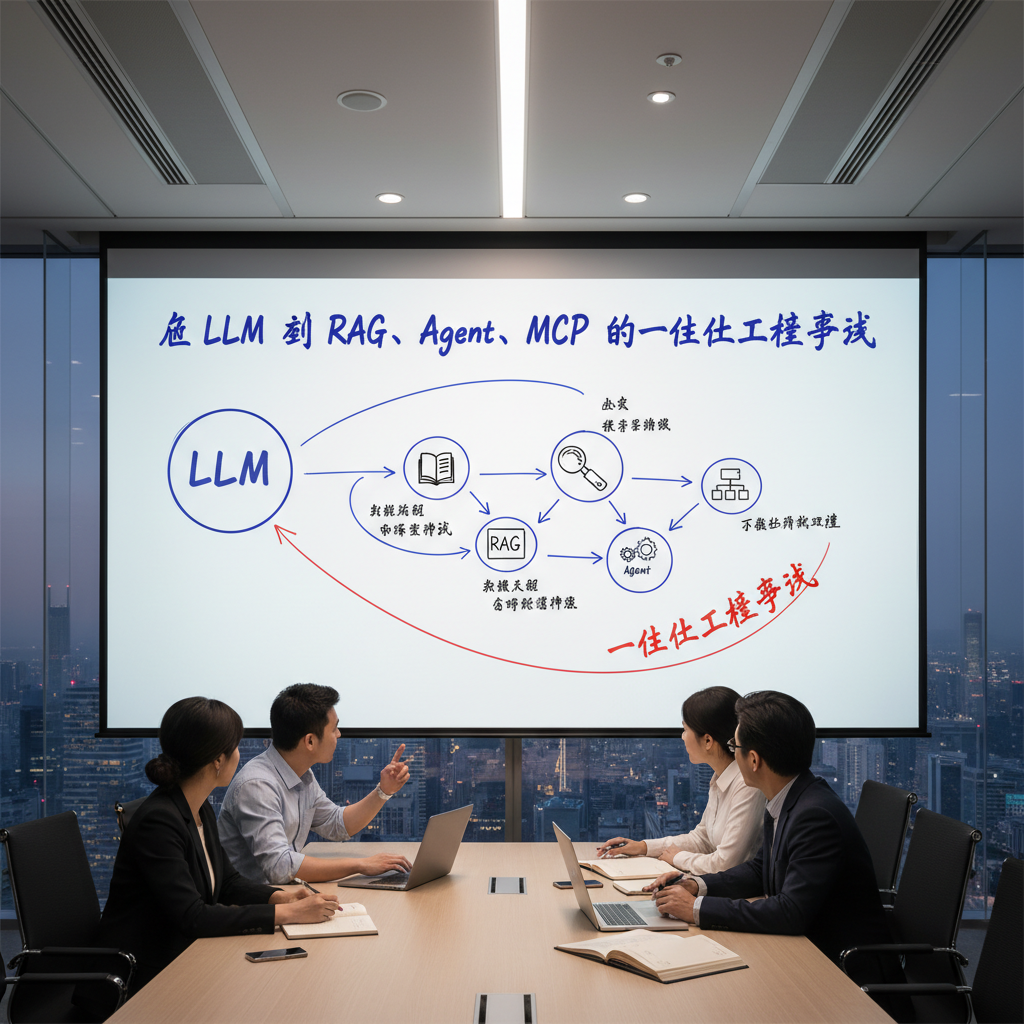
引言
2025 年,企业用大模型做应用,主线已经从「能聊天」转向「能干活」。 很多团队不再满足于一个对话机器人,而是希望它能看业务数据、理解流程、调用系统,真正完成任务闭环。
与此同时,LLM、RAG、Agent、MCP 这些关键词几乎出现在所有技术分享和方案白皮书中,但实际落地时常见两种极端:要么停留在 Hello World Demo,要么堆满名词却难以维护和扩展。 对行业开发者来说,关键问题不是“多几个术语”,而是:在企业环境中,究竟如何组合 LLM + RAG + Agent + MCP,搭出一套可运行、可迭代、可治理的 AI 基础设施。
LLM:一切能力的基座
从 GPT-3 到现在,主流大语言模型在参数规模、训练数据与推理能力上持续进化,但在工程视角下,可以把 LLM 看成一个「通用语义引擎 + 推理引擎」。 对企业开发者来说,更重要的是:它不是全能大脑,而是上层系统的一个「能力组件」,重点在于如何为它准备好上下文、工具和约束边界。
在选型上,行业里逐渐形成了「云端闭源 + 自建/托管开源 + 混合」三大路径:云端模型负责高质量通用推理,本地或私有部署模型处理敏感数据、低延迟或成本敏感场景。 对大多数企业来说,一个务实的策略是:用更轻量的模型配合高质量 RAG 和 Agent 设计,而不是盲目追求最“大”的模型。
RAG:让模型真正“懂你的业务”
RAG 的核心价值
单靠通用 LLM,很难解决企业私有知识、强时效数据和严谨合规回答的问题,这时就需要 RAG(Retrieval-Augmented Generation,检索增强生成)。 RAG 的基本思路是:在大模型生成前,用向量检索等手段从企业文档、数据库、知识图谱中找到相关信息,再把这些信息作为上下文喂给模型,让输出“有据可依”。
标准 RAG 流程大致包括:文本切分、特征向量化、建立索引、检索召回、可选重排与过滤、构造提示词、模型生成回答。 在企业知识库问答、内部政策解读、产品 FAQ 和运维手册查询等场景中,合理设计 RAG 往往能比“纯 LLM”显著提升准确率并降低幻觉。
关键工程决策
对行业开发者而言,RAG 的难点不在“有没有向量库”,而在工程细节上:分块策略、Embedding 选型、召回与重排策略、缓存策略和评估。 例如在长文档、多章节政策场景中,如果分块过大,检索不精确;太小,又会丢失上下文语义,容易导致模型误解。
评估方面,当前常见做法包括:构造标注问答集,基于 LLM 或规则对回答进行相关性、完整性和事实性评分,并监控命中率、上下文利用率、token 成本等指标。 在银行、政府、能源等高风险领域,越来越多实践引入 GraphRAG、知识图谱和多路检索,以兼顾可解释性和复杂推理能力。
Agentic RAG:从“检索+生成”到“可规划+可协作”
传统 RAG 多数只是“一问一答”的直线流程,而 Agentic RAG 则让 RAG 拥有了规划、决策和迭代能力。 在这种范式下,Agent 会根据问题拆解任务、选择检索策略、多轮调用不同数据源,并可能在中间步骤自我反思和修正。
典型做法包括:动态选择检索通道(向量库、全文检索、知识图谱等)、多跳检索(先找概览再深挖细节)、对中间结论进行验证或反问用户补充信息等。 在复杂业务问题上,例如“针对近半年投诉数据和政策变化,评估某产品的合规风险”,Agentic RAG 通常比单次 RAG 有更好的逻辑性和覆盖度。
Agent:从「聊天机器人」到「业务协作体」
Agent 是什么
在工程实践中,一个 AI Agent 通常指具备目标感知、任务规划、工具选择与调用、结果整合与反思能力的智能组件。 与普通 LLM 调用的区别在于:Agent 可以根据长期目标自动拆解子任务,灵活调用多种工具或其他 Agent,并在过程中保留记忆和状态。
Agent 常见能力包括:RAG 查询、数据库与 API 访问、代码执行、流程编排、文件操作等,这些能力通常通过工具调用或协议(如 MCP、A2A 等)暴露给 Agent。 在企业里,Agent 可以被抽象为“一个角色”:财务分析助手、测试助手、运维助手、客服 Copilot 等。
架构模式与演进
当前 Agent 架构大致有三种主流形态:
- 单体 Agent:一个 Agent + 若干工具,适合简单任务自动化,如报表生成助手、FAQ 助手。
- 工作流型 Agent:预定义流程结合 LLM 决策,用于需要较强确定性的业务,如审批流程、订单处理。
- 多 Agent(Agent 社群):多个 Agent 扮演不同角色,通过对话或协议协作解决复杂问题,如跨部门分析、项目管理等。
大量实践表明,企业级落地时往往会将 Agent 能力压缩到“窄任务 + 强约束”的形态,并辅以工作流编排,避免“过度自由导致不可控”。 在 toB 业务中,一个务实的演进路径是:从单 Agent + 简单工具调用起步,逐步引入多 Agent 协作和自动规划能力。
MCP:把 LLM 体系接上「真实世界」
MCP 的基本思想
MCP(Model Context Protocol)可以理解为“为模型生态设计的一套标准化上下文与工具接入协议”,它定义了模型如何发现、描述、调用外部工具和数据源,并统一了请求与响应规范。 在工程上,MCP 规范了一类“Server(工具/数据源提供者)– Client(LLM/Agent 调用方)”的交互模式,使不同系统可以以插件化方式被模型使用。
相比传统的零散 Function Calling 或自定义 API 适配,MCP 提供统一的能力发现、权限声明、调用约定和上下文管理,让 Agent 能在较稳定的协议层之上动态挂载与替换后端能力。 这对多团队协作、跨系统集成、多云或混合部署场景尤为关键。
MCP + RAG + Agent 的协同
在很多最新实践中,MCP 被用来把 RAG 服务、知识库、业务系统和外部工具统一暴露给 Agent:例如“知识检索 MCP 服务”“工单系统 MCP 服务”“报表生成 MCP 服务”等。 Agent 不需要关心这些服务背后是向量库、搜索引擎还是数据库,只需通过 MCP 约定的接口发现能力并调用。
同时,MCP 自身也开始与 RAG 深度结合,比如通过 MCP 把多个知识源聚合为统一检索入口,或由 MCP 控制器根据问题类型路由到不同 RAG 管线。 在企业级 Agent 平台中,以 MCP 为核心构建“AI 能力中台”已经逐步成为趋势,有利于把 AI 能力沉淀为可治理的基础设施。
LLM + RAG + Agent + MCP:一体化企业架构长什么样?
总体分层与数据流
面向行业的典型企业架构,一般可以分成四层:数据与系统层、AI 能力层(RAG、模型服务等)、Agent 与编排层、应用与业务层。 MCP 作为协议与连接层,贯穿在 AI 能力层与 Agent/应用层之间,实现统一的工具与数据接入。
一个用户请求从进入系统到完成任务,往往会经历:由 Agent 理解意图与规划任务,决定是否需要检索知识或访问业务系统,通过 MCP 调用 RAG 服务、数据库或业务 API,汇总中间结果并生成对用户友好的输出。 在复杂场景下,多 Agent 之间还会通过任务图或会话协商来协作完成跨域任务。
核心关注点:安全、权限与治理
在企业环境中,架构设计不能只看技术可行性,还要遵守安全、合规和治理要求。常见要求包括:对不同 MCP 服务实施权限控制,限制 Agent 能访问的数据范围和操作权限;记录每次调用的审计日志,用于追溯问题和合规检查;在关键业务流程中引入人工确认环节。
同时,企业会关注多租户、成本与延迟、监控与告警等问题,这就需要在架构上设计好模型路由、缓存策略、服务限流与降级方案,并配合 LLMOps 平台进行全链路观测和灰度发布。
一个端到端案例:企业内部知识 Copilot(行业开发者视角)
以“企业内部知识助手 / Copilot”为例,这是目前 RAG + Agent + MCP 最常见的落地场景之一,适用于咨询、互联网、制造、金融等多种行业。
1. 业务需求与目标
典型需求包括:统一查询内部文档(规范、政策、研发文档、运维手册等),支持自然语言提问,给出引用清晰、可追溯的答案,必要时还能帮用户生成邮件、报告等文档。 附加目标往往是:减少新人培训成本、提升客服或运维一线效率,并为管理层提供一定的数据洞察能力。
2. 技术选型与组件
在这种场景下的常见选型包括:一到两个主力大模型(云端通用 + 本地/私有模型)、一个向量数据库或检索引擎、一个面向知识的 RAG 服务、一个 Agent 编排框架和 MCP 兼容的工具层。
- LLM:选择支持工具调用且在中文和业务领域表现良好的模型,并预留后续切换或多模型路由的空间。
- RAG:为主要知识域(如产品、政策、技术文档)构建向量索引,设计多路召回与重排策略,并引入基本的评估能力。
- Agent:实现一个“知识 Copilot Agent”,负责意图识别、选择检索策略、组织引用、生成答案和辅助文档。
- MCP:把知识检索、文档存储、工单系统、用户信息服务等封装为 MCP 服务,供 Agent 动态调用。
3. 流程拆解
一个典型的问答请求,大致包括以下步骤:
- 用户在前端提出问题,Agent 分析意图,判断是简单 FAQ 还是复杂综合问题。
- Agent 调用 MCP 暴露的 RAG 服务,请求相关文档片段及其元数据;对复杂问题可能进行多轮检索或多源合并。
- Agent 结合检索结果与用户上下文(部门、权限等),组织答案草稿,并附上引用来源链接。
- 如需要进一步操作(如创建工单、生成通知邮件等),Agent 再通过 MCP 调用相应业务系统服务。
在部分实践中,为了增强可解释性和稳定性,会在 RAG 层增加知识图谱、规则引擎或结构化检索,以实现更可靠的多跳推理和关系查询。
2025 之后值得关注的趋势
2025 年之后,大模型应用在企业的演进重点将逐步从“是否使用 AI”转向“如何把 AI 融入核心业务流程并持续运营”。 多模态 LLM、图像与文档理解、多模态 RAG、长记忆与个性化 Agent 等方向,将进一步扩大全球企业在数据分析、决策支持、质量控制等方面的自动化空间。
与此同时,低代码/平台化的 Agent 开发平台和 AI 应用中台会继续成熟,AgentDevOps、RaaS(Result-as-a-Service)、统一的 MCP/A2A 协议等,将把“开发一个企业级 Agent”变成更标准化的工程活动,而不是一次性的系统集成项目。 对行业开发者来说,尽早在 LLM + RAG + Agent + MCP 组合上建立体系化认知,将直接决定未来几年在团队中的技术话语权和业务影响力。
Agent / RAG / MCP / 数据架构 资料索引
本部分对 Agent、多 Agent、RAG、MCP、企业数据架构、云原生与中间件实践 相关资料进行导航式整理,强调“好扫读、好回看、好定位”。
一、Agent 与 Multi-Agent 基础与实践
-
Agent / 多 Agent 技术综述
优快云:Agent 架构、能力与工程实践概览
👉 https://blog.youkuaiyun.com/musicml/article/details/155558784 -
多 Agent 系统设计与实现
Cloud Tencent:多 Agent 协作模式与工程思路
👉 https://cloud.tencent.com/developer/article/2546160 -
Multi-Agent 架构解析
优快云:多 Agent 设计模式与落地经验
👉 https://blog.youkuaiyun.com/m0_59235245/article/details/149756047 -
Multi-Agent 深度实践
Hogwarts 博客:多 Agent 框架与调度实践
👉 https://www.cnblogs.com/hogwarts/p/19021576 -
Multi-Agent 进阶实践分享
GitHub Pages:多 Agent 系统实战总结
👉 https://hustyichi.github.io/2025/08/28/multi-agent/
二、RAG(检索增强生成)与知识增强
-
RAG 技术体系与实践
优快云:RAG 架构与实现要点
👉 https://blog.youkuaiyun.com/EnjoyEDU/article/details/155128151 -
RAG 工程实践详解
Cloud Tencent:企业级 RAG 实现思路
👉 https://cloud.tencent.com/developer/article/2505910 -
RAG 架构设计与优化
优快云:RAG 系统设计与性能思考
👉 https://blog.youkuaiyun.com/2401_84204207/article/details/155578240 -
RAG 行业观察与趋势
53AI:RAG 在企业应用中的发展
👉 https://www.53ai.com/news/RAG/2025042103869.html
三、MCP / 工具协议 / Agent 能力接入
-
MCP 技术解读与实践
MCP 专区:Model Context Protocol 工程说明
👉 https://mcp.youkuaiyun.com/681b5366e47cbf761b689bcb.html -
Agent 工具化与协议设计
优快云:Agent 调用工具与协议思路
👉 https://blog.youkuaiyun.com/sinat_39620217/article/details/141937996
四、企业数据架构 × GenAI
-
GenAI 驱动的企业数据架构重塑
AWS 官方博客(中国):企业数据底座与 GenAI 结合
👉 https://aws.amazon.com/cn/blogs/china/industry-foundation-idata-genai-driven-enterprise-data-architecture-reshaping/ -
企业数据架构与大模型融合
Cloud Tencent:数据中台 / 数据架构新范式
👉 https://cloud.tencent.com/developer/article/2577147 -
企业级 AI 数据治理思考
36Kr:产业视角下的数据与 AI 融合
👉 https://m.36kr.com/p/3509752155134848
五、云原生 / API 网关 / 中间件
-
Higress × AI 网关实践
Higress 官方博客:AI 场景下的网关能力
👉 https://higress.cn/blog/higress-gvr7dx_awbbpb_zixhqugf2dp99bz8/ -
云原生 AI 架构实践
Huawei Cloud:云原生 + AI 的工程案例
👉 https://bbs.huaweicloud.com/blogs/434592 -
AI 中间件架构思考
Cloud Tencent:AI 时代的中间件演进
👉 https://cloud.tencent.com/developer/article/2562239
六、研究报告与行业分析
-
AI Agent / 数据智能研究报告
发现报告(FX 报告):行业研究与趋势分析
👉 https://www.fxbaogao.com/detail/5053122 -
AI Agent 行业观察
今日头条:国内 Agent 发展解读
👉 https://www.toutiao.com/article/7583230288189194804/ -
AI 与数据智能新闻
腾讯新闻:AI 产业与应用动态
👉 https://news.qq.com/rain/a/20251202A04J9800
七、视频与多媒体资料
-
Multi-Agent 技术分享(Bilibili)
👉 https://www.bilibili.com/video/BV1dQvNz1EkA/ -
Agent / RAG 实战分享(Bilibili)
👉 https://www.bilibili.com/video/BV1twpxz4EC9/ -
企业级 AI 架构分享(Bilibili)
👉 https://www.bilibili.com/video/BV1Rhk6BkELL/




















 182
182

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











