




 本文深入解析JavaScript构造函数,涵盖其定义、使用原因、执行流程及返回值特性,助力理解原型与原型链基础。
本文深入解析JavaScript构造函数,涵盖其定义、使用原因、执行流程及返回值特性,助力理解原型与原型链基础。
转载地址:https://juejin.im/post/5aa0f0ef6fb9a028e52d69ea
大家都知道原型和原型链是 JavaScript 中最经典的问题之一,而构造函数又是原型和原型链的基础,所以先了解清楚构造函数以及它的执行过程可以更好地帮助我们学习原型和原型链的知识。
本文将从以下几个方面来探讨构造函数:
1.什么是构造函数
在 JavaScript 中,用 new 关键字来调用的函数,称为构造函数。
2.为什么要使用构造函数
学习每一个概念,不仅要知道它是什么,还要知道为什么,以及解决什么样的问题。
举个例子,我们要录入一年级一班中每一位同学的个人信息,那么我们可以创建一些对象,比如:
var p1 = { name: 'zs', age: 6, gender: '男', hobby: 'basketball' };
var p2 = { name: 'ls', age: 6, gender: '女', hobby: 'dancing' };
var p3 = { name: 'ww', age: 6, gender: '女', hobby: 'singing' };
var p4 = { name: 'zl', age: 6, gender: '男', hobby: 'football' };
// ...像上面这样,我们可以把每一位同学的信息当做一个对象来处理。但是,我们会发现,我们重复地写了很多无意义的代码。比如 name、age、gender、hobby 。如果这个班上有60个学生,我们得重复写60遍。
这个时候,构造函数的优势就体现出来了。我们发现,虽然每位同学都有 name、gender、hobby 这些属性, 但它们都是不同的,那我们就把这些属性当做构造函数的参数传递进去。而由于都是一年级的学生,age 基本都是6岁,所以我们就可以写死,遇到特殊情况再单独做处理即可。此时,我们就可以创建以下的函数:
function Person(name, gender, hobby) {
this.name = name;
this.gender = gender;
this.hobby = hobby;
this.age = 6;
}当创建上面的函数以后, 我们就可以通过 new 关键字调用,也就是通过构造函数来创建对象了。
var p1 = new Person('zs', '男', 'basketball');
var p2 = new Person('ls', '女', 'dancing');
var p3 = new Person('ww', '女', 'singing');
var p4 = new Person('zl', '男', 'football');
// ...此时你会发现,创建对象会变得非常方便。所以,虽然封装构造函数的过程会比较麻烦,但一旦封装成功,我们再创建对象就会变得非常轻松,这也是我们为什么要使用构造函数的原因。
在使用对象字面量创建一系列同一类型的对象时,这些对象可能具有一些相似的特征(属性)和行为(方法),此时会产生很多重复的代码,而使用构造函数就可以实现代码的复用。
3.构造函数的执行过程
先说一点基本概念。
function Animal(color) {
this.color = color;
}当一个函数创建好以后,我们并不知道它是不是构造函数,即使像上面的例子一样,函数名为大写,我们也不能确定。只有当一个函数以 new 关键字来调用的时候,我们才能说它是一个构造函数。就像下面这样:
var dog = new Animal("black");以下我们只讨论构造函数的执行过程,也就是以 new 关键字来调用的情况。
我们还是以上面的 Person 为例。
function Person(name, gender, hobby) {
this.name = name;
this.gender = gender;
this.hobby = hobby;
this.age = 6;
}
var p1 = new Person('zs', '男', 'basketball');此时,构造函数会有以下几个执行过程:
(1) 当以 new 关键字调用时,会创建一个新的内存空间,标记为 Animal 的实例。

(2) 函数体内部的 this 指向该内存
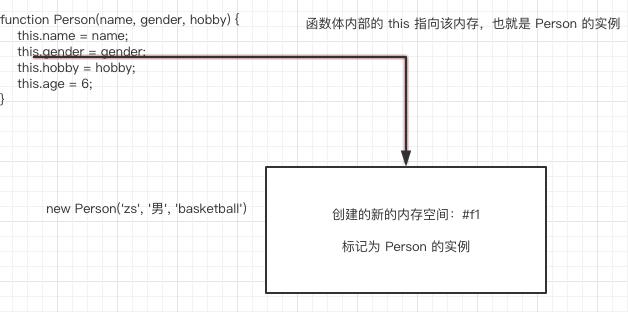
通过以上两步,我们就可以得出这样的结论。
var p2 = new Person('ls', '女', 'dancing'); // 创建一个新的内存 #f2
var p3 = new Person('ww', '女', 'singing'); // 创建一个新的内存 #f3每当创建一个实例的时候,就会创建一个新的内存空间(#f2, #f3),创建 #f2 的时候,函数体内部的 this 指向 #f2, 创建 #f3 的时候,函数体内部的 this 指向 #f3。
(3) 执行函数体内的代码
通过上面的讲解,你就可以知道,给 this 添加属性,就相当于给实例添加属性。
(4) 默认返回 this
由于函数体内部的 this 指向新创建的内存空间,默认返回 this ,就相当于默认返回了该内存空间,也就是上图中的 #f1。此时,#f1的内存空间被变量 p1 所接受。也就是说 p1 这个变量,保存的内存地址就是 #f1,同时被标记为 Person 的实例。
以上就是构造函数的整个执行过程。
4.构造函数的返回值
构造函数执行过程的最后一步是默认返回 this 。言外之意,构造函数的返回值还有其它情况。下面我们就来聊聊关于构造函数返回值的问题。
(1)没有手动添加返回值,默认返回 this
function Person1() {
this.name = 'zhangsan';
}
var p1 = new Person1();按照上面讲的,我们复习一遍。首先,当用 new 关键字调用时,产生一个新的内存空间 #f11,并标记为 Person1 的实例;接着,函数体内部的 this 指向该内存空间 #f11;执行函数体内部的代码;由于函数体内部的 this 指向该内存空间,而该内存空间又被变量 p1 所接收,所以 p1 中就会有一个 name 属性,属性值为 'zhangsan'。
p1: {
name: 'zhangsan'
}(2) 手动添加一个基本数据类型的返回值,最终还是返回 this
function Person2() {
this.age = 28;
return 50;
}
var p2 = new Person2();
console.log(p2.age); // 28p2: {
age: 28
}如果上面是一个普通函数的调用,那么返回值就是 50。
(3) 手动添加一个复杂数据类型(对象)的返回值,最终返回该对象
直接上例子
function Person3() {
this.height = '180';
return ['a', 'b', 'c'];
}
var p3 = new Person3();
console.log(p3.height); // undefined
console.log(p3.length); // 3
console.log(p3[0]); // 'a'再来一个例子
function Person4() {
this.gender = '男';
return { gender: '中性' };
}
var p4 = new Person4();
console.log(p4.gender); // '中性'关于构造函数的返回值,无非就是以上几种情况,大家可以动手试一试,也就记住了。
最后总结一下,本文从四个方面介绍了构造函数,而构造函数是原型和原型链学习的基础,所以大家有必要花点时间好好学习一下关于构造函数的知识,下篇文章我会来讲讲人人都能看懂的原型链,敬请期待。

















 1231
1231

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









