




 本文介绍如何在PyTorch中查看模型、优化器及学习率调度器的参数,并提供四种不同的方法来查看模型参数。此外,还介绍了如何选择性地冻结模型的某些层进行训练。
本文介绍如何在PyTorch中查看模型、优化器及学习率调度器的参数,并提供四种不同的方法来查看模型参数。此外,还介绍了如何选择性地冻结模型的某些层进行训练。
准备工作
import torch.optim as optim
import torch
import torchvision.models as models
device=torch.device("cuda" if torch.cuda.is_available() else "cpu")
model=models.resnet50(pretrained=False).to(device)
optimizer=optim.Adam(model.parameters(),0.01)
scheduler = optim.lr_scheduler.MultiStepLR(optimizer, milestones=[3, 6, 10, 15, 21], gamma=1/3.)
#--------------------------------
查看模型的参数
方法一
通过torchsummary这个包,首先安装这个包,
pip install torchsummary
然后
from torchsummary import summary
summary(model,input_size=(3,416,416))
结果:
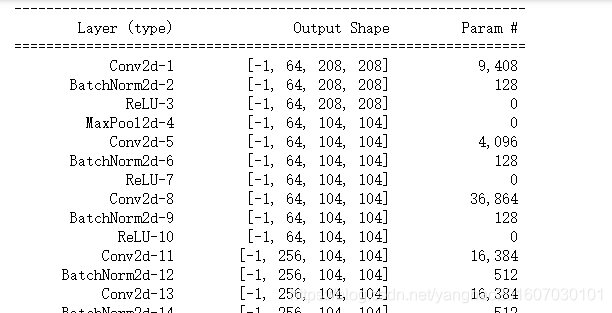

方法二
使用model.named_parameters()
sum=0
for name,param in model.named_parameters():
num=1
for size in param.shape:
num *= size
sum+=num
print("{:30s} : {}".format(name,param.shape))
print("total param num {}".format(sum))
结果:

方法三
直接使用model.parameters(),但是这样看不见参数名。
for param in model.parameters():
print(param.shape)
结果:

方法四
利用state_dict,state_dict以字典的方式保持了模型的参数名称和参数,通过遍历可以获取所有的参数。
for name in model.state_dict():
print("{:30s}:{}".format(name,model.state_dict()[name].shape))
结果:
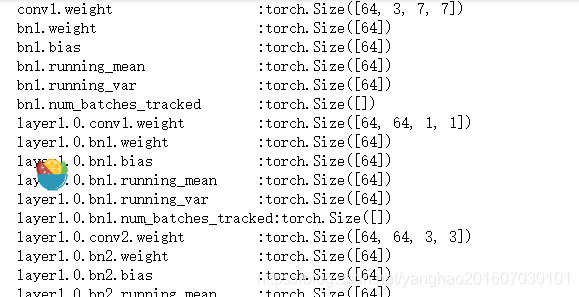
pytorch中带有参数的不止有model,还有optimizer和lr_scheduler,因此它们都有一个共同的属性state_dict,所以要想查看他们的参数名称,这个方法是通用的。
查看optimizer的参数
当然,查看优化器的参数时,除了使用查看模型参数的方法四,还有以下这种方式。
#打印optimizer的参数
print("optimizer.param_groups的长度:{}".format(len(optimizer.param_groups)))
for param_group in optimizer.param_groups:
print(param_group.keys())
print([type(value) for value in param_group.values()])
print('查看学习率: ',param_group['lr'])
结果:
optimizer.param_groups的长度:1
dict_keys(['params', 'lr', 'betas', 'eps', 'weight_decay', 'amsgrad', 'initial_lr'])
[<class 'list'>, <class 'float'>, <class 'tuple'>, <class 'float'>, <class 'int'>, <class 'bool'>, <class 'float'>]
查看学习率: 0.01
冻结训练
可以选择性的冻结模型的某些层。
for layer in list(model.parameters())[:2]:
layer.requires_grad=False
关于,冻结训练,可以看我这篇文章。


















 6066
6066




 到【灌水乐园】发言
到【灌水乐园】发言







