




 本文提出了一种新的模块——可变形卷积网络(Deformable ConvNets),包括可变形卷积(Deformable Convolution)和可变形RoI池化(Deformable RoIPooling),旨在解决CNN在几何变换上的局限性。通过学习采样点的偏移量,这些模块能适应性地调整卷积和池化的采样位置,提高模型在目标检测和语义分割等任务中的性能。实验表明,DCN在不显著增加参数量和计算成本的情况下,能有效提升现有CNN架构的准确性。
本文提出了一种新的模块——可变形卷积网络(Deformable ConvNets),包括可变形卷积(Deformable Convolution)和可变形RoI池化(Deformable RoIPooling),旨在解决CNN在几何变换上的局限性。通过学习采样点的偏移量,这些模块能适应性地调整卷积和池化的采样位置,提高模型在目标检测和语义分割等任务中的性能。实验表明,DCN在不显著增加参数量和计算成本的情况下,能有效提升现有CNN架构的准确性。
目录
Abstract
CNN由于其固定的结构而受限于模型的几何变换,本文提出的两个新模块加强了CNN的变换能力,(Deformable Convolution,DC)和(Deformable RoI Pooling,DRP)。两者的设计均是基于在模块中通过偏移来增墙空间采样位置,并从目标任务中学习偏移量。实验证明,DCN可以替代CNN用以实现如目标检测、语义分割等复杂的视觉任务。
论文贡献:
1.提出一种适应性采样方法;
2.在不显著增加参数量和计算的情况下提高目标检测和语义分割模型的性能;
3.可以轻易集成到基于CNN的计算机视觉任务中
1. Introduction
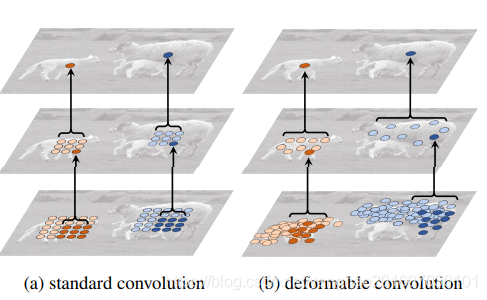
Deformable convolution network由两个模块构成,一个是deformable convolution,一个是 deformable RoI pooling。
CNN中在特征图上的卷积操作是三维的,即平面加通道。而deformable convolution和deformable RoI pooling则是二维空间的的,他们改变卷积在平面上的采样位置,即感受野的位置,而通道维度则没有改变,通过这种方式提高特征提取的性能。如图
2. Deformable Convolutional Networks
Deformable Convolution
2D卷积有两步:
第一步是通过一个卷积核在特征图上采样;
第二步把这些采样点乘不同权重w后相加。
卷积中采样点是规则的,比如一个扩张度(dilation)为1 的3×3卷积核表示为:
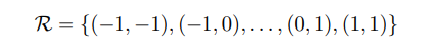
p若o则是输出特征图y上的一点,那么卷积操作就定义为:
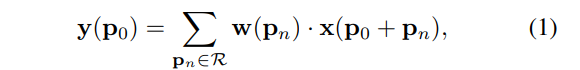
可变卷积的deformation指的则是改变卷积操作中的第一步——修改采样点位置,可通过给采样点加位移offset实现。
原理如下图:
首先通过一个和正常卷积一样的卷积和对输入特征图做卷积,得到一个和输出特征图空间维度一样的特征图大小,通道数位2N,2是每个点有x和y方向的偏移,N是二维空间上卷积的一个感受野大小,N=k×k。对应于输出特征图上的每个点,其卷积的采样点通过offsets特征图上该点处的2N个channel上的2N个offsets值来确定。确定采样点后就通过权重w相加得到输出图上该点最终值。
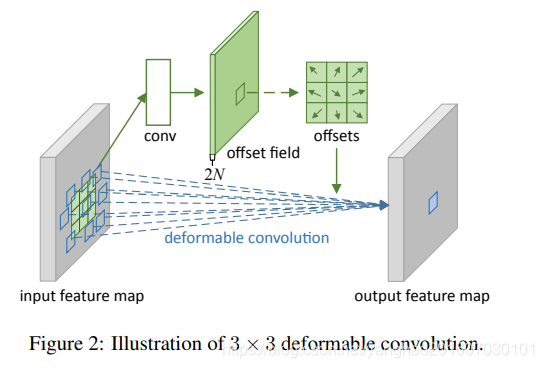
上述的公式表示:
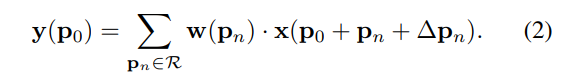
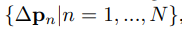
ΔPn就是我们的offsets,共N(N=k×k)个。
然后细节上补充一点,ΔPn通常会是小数,从而P=P0+Pn+ΔPn也是小数,那么x(p)取值就要谨慎选择,这里取P四周的四个整数点q,通过双线性插值来求得x(P).
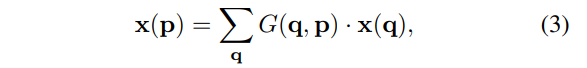
其中G是二维的,可分为两个一维的运算。
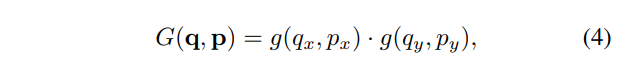
其中g(a, b) = max(0, 1 − |a − b|)。
上式即双线性插值,简单讲就是四个点分两组先x方向线性插值得到两个点,然后这两个点再y方向线性插值得到最终值。
示意图:图源:https://blog.youkuaiyun.com/u013010889/article/details/78803240
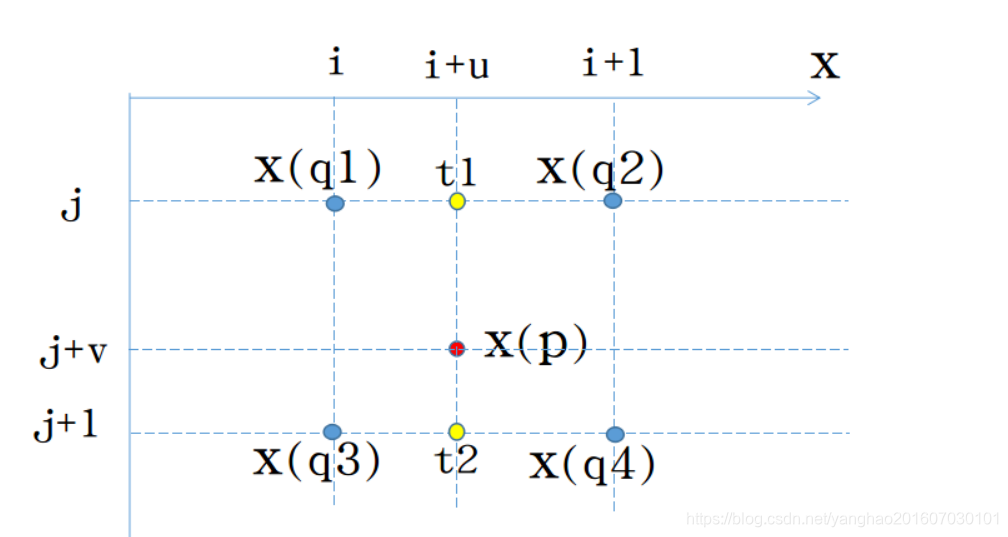
强调以下,这里用于生成采样点偏移的卷积核与生成最终特征图的卷积核尺寸和步长都一样,他们都作用于同一个输入特征图,且生成的offset field和生成的特征图尺寸一样,两个卷积核同时学习,而对于offset field的学习可能会出现小数的坐标点,因此反向传播过程中利用线性插值来学习梯度,也就是上面提到的双线性插值方式。
Deformable RoI Pooling
RoI Pooling将输入的任意大小的矩形区域转换为固定大小的特征。
RoI Pooling所作操作:首先将RoI映射到特征图上,然后给定输入特征图x,以及一个大小为w×h,其左上角为P0 的RoI,,则RoI Pooling将特征图划分为k × k个bins,每个bins通过池化操作输出一个值,最终输出一个k × k的特征图y。
于是对于第(i, j)个bin有
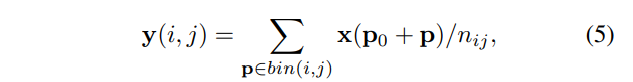
其中 n i j n_{ij} nij是该bin(i,j)中的像素个数。bin(i,j)中像素p的两个坐标 p x , p y p_x,p_y p
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









