




 C++将输入输出视为字节流,通过流和缓冲区进行处理。iostream库提供了streambuf、ios_base、ios、ostream和istream等类来管理和操作这些流。cin、cout、cerr和clog是预定义的流对象,分别对应标准输入、输出、错误和日志流。ostream的<<运算符重载用于输出,而cin则用于处理输入,如read()、peek()和putback()等方法。此外,还可以使用width()、precision()和fill()等函数进行格式化输出。
C++将输入输出视为字节流,通过流和缓冲区进行处理。iostream库提供了streambuf、ios_base、ios、ostream和istream等类来管理和操作这些流。cin、cout、cerr和clog是预定义的流对象,分别对应标准输入、输出、错误和日志流。ostream的<<运算符重载用于输出,而cin则用于处理输入,如read()、peek()和putback()等方法。此外,还可以使用width()、precision()和fill()等函数进行格式化输出。
C++输入和输出概述
流和缓冲区
C++程序把输入和输出看作字节流。输入时,程序从输入流中抽取字节;输出时,程序将字节插入到输出流中
流充当了程序和流源或流目标之间的桥梁。这使得C++程序可以以相同的方式对待来自键盘的输入和来自文件的输入
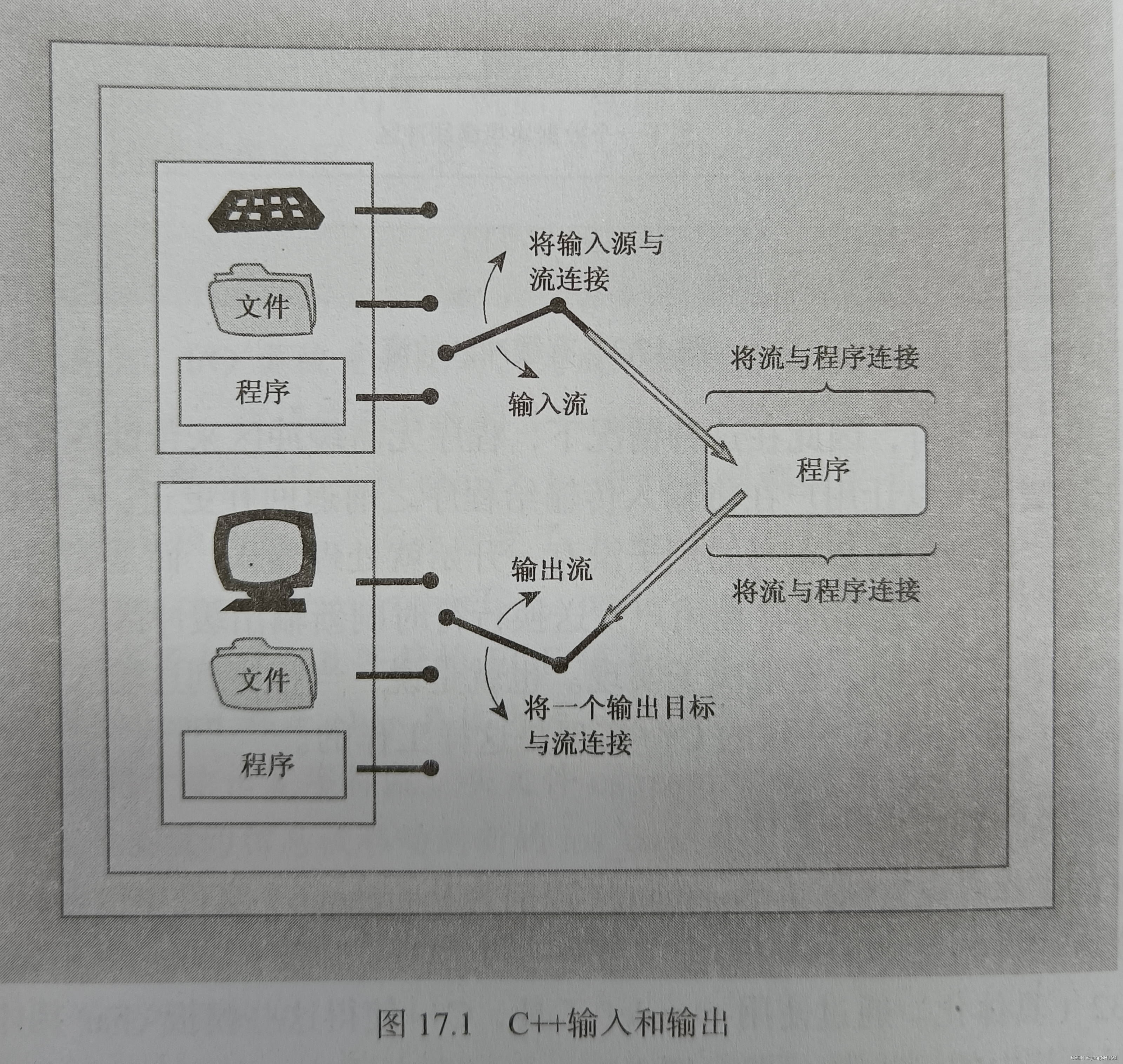
通常使用缓冲区可以更高效地处理输入和输出。缓冲区是用作中介的内存块,是将信息从设备传输到程序或从程序传输给设备的临时存储工具。
流、缓冲区和iostream文件
iostream文件中包含一些专门用来实现、管理流和缓冲区的类
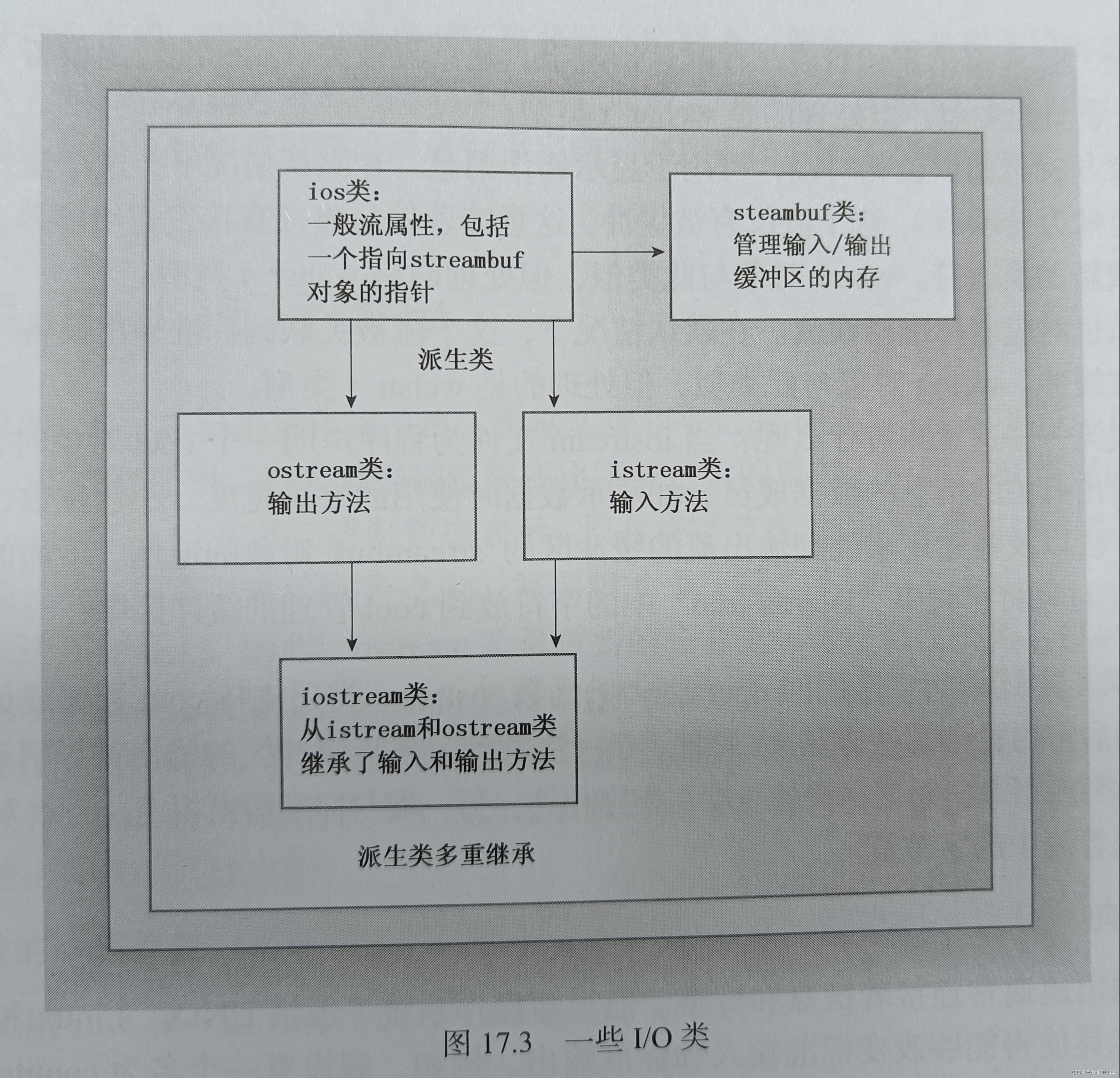
- streambuf类为缓冲区提供了内存,并提供了用于填充缓冲区、访问缓冲区内容、刷新缓冲区和管理缓冲区内存的类方法
- ios_base类表示流的一般特征,如是否可读取、是二进制流还是文本流等
- ios类基于ios_base,其中包括了一个指向streambuf对象的指针
- ostream类是从ios类派生而来的,提供了输出方法
- istream类是从ios类派生而来的,提供了输入方法
- iostream类是基于istream和ostream类的,因此继承了输入方法和输出方法
C++的iostream类库管理了很多细节
- cin对象对应于标准输入流
- cout对象与标准输出流相对应
- cerr对象与标准错误流相对应,可用于显示错误消息。这个流没有缓冲,直接将信息发送给屏幕,而不会等到缓冲区填满或换新的换行符
- clog对象也对应着标准错误流
使用cout进行输出
重载的<<运算符
ostream类重新定义了<<运算符,将其重载为输出
除了各种operator<<()函数外,ostream类还提供了put()方法和write()方法,前者用于显示字符,后者用于显示字符串
put()方法的原型如下:
ostream & put(char);
可以用类方法表示法来调用它:
cout.put('W');
其中cout是调用方法的对象,put()是类成员函数 。在原型合适的情况下,可以将数值型参数(如int)用于put(),让函数原型自动将参数转化为正确char值,如
cout.put(65) << endl;
cout.put(68.3);

write()方法显示整个字符串,其模板原型如下:
basic_ostream<charT,traits>& write(const char_type *s ,streamsize n);
第一个参数提供了要显示的字符串的地址,第二个参数指出要显示多少个字符
#include<iostream>
#include<cstring>
using namespace std;
int main()
{
const char* statel = "Florida";
const char* state2 = "Kansas";
const char* state3 = "Euphoria";
int len = strlen(state2);
int i;
cout << "Increasing loop index:\n";
for (i = 1; i <= len; i++)
{
cout.write(state2, i);
cout << endl;
}
cout << "Decreasing loop index:\n";
for (i = len; i > 0; i--)
{
cout.write(state2, i) << endl;
}
cout << "Exceeding string length:\n";
cout.write(state2, len + 5) << endl;
return 0;
}

注意cout.write()调用返回cout对象。
使用cout进行格式化
可以使用width成员函数将长度不同的数字放到宽度相同的字段中
int width();
int width(int i);
第一种格式返回字段宽度的当前设置;第二种格式将字段宽度设置为i个空格,并返回以前的字段宽度值
注意width()方法只影响接下来显示的一个项目,然后字段宽度将恢复为默认值
填充字符
在默认情况下,cout用空格填充未被使用的部分,可以用fill()成员函数来改变填充字符,例如下面的函数调用将填充字符改为星号:
cout.fill('*');
设置浮点数的精度
浮点数精度的含义取决于输出模式,在默认模式下,它指的是显式的总位数。在定点模式和科学模式下,精度指的是小数点后面的位数。C++ 的默认精度为6位,precision()成员函数使得能够选择其他值,如下面语句将cout的精度设置为2:
cout.precision(2);
头文件iomanip
C++在头文件中提供了其他一些控制符,3个最常见的控制符分别是setprecision()、setfill()、和setw(),它们分别用来设置精度、填充字符和字符宽度。
使用cin进行输入
cin对象将标准输入表示为字节流,通常用键盘来生成这种字符流。
除了前面已经介绍过的外,其他istream方法包括read(),peek(),gcount(),putback()
read()函数读取指定数目的字节,并将它们存储在指定的位置中
peek()函数返回输入中的下一个字符,但不抽取输入流中的字符
gcount()函数返回最后一个非格式化抽取方法读取的字符数。这意味着字符是由get()、getline()、ignore()或read()方法读取的,而不是由抽取运算符(>>)读取的,抽取运算符对输入进行格式化,使之与特定数据类型匹配
putback()函数将一个字符插入到字符串中,被插入的字符将是下一条输入语句读取的第一个字符。

















 5250
5250

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









